CASE-средство проектирования баз данных ERWin
CASE - сокращение от Computer Aided Software Engineering. CASE-средства позволяют автоматизировать создание информационных систем на протяжение всего жизненного цикла. Имеются CASE-средства для моделирования, проектирования, разработки, тестирования, постороения отчетов, управления версиями программного продукта и другие. В этом параграфе мы рассмотрим применение только одного программного продукта ERWin. В ERWin удобно рисовать структуру базы данных. Для работы с MySQL ничего больше от ERWin'a добиться нельзя, т.к. MySQL он не поддерживает. Для других баз данных ERWin может на основе структуры базы данных сгенерировать SQL-код этой структуры. Или же наоборот, по SQL-коду сгенерировать внешний вид структуры базы данных. Проектирование происходит на двух уровнях: логическом и физическом. На логическом уровне проектируемая структура базы данных не связана с конкретной СУБД. В логической модели отображаются сущности, атрибуты и отношения между сущностями. Для работы с MySQL в ERWin нам требуется получить только красивую картинку структуры базы данных, поэтому физическая модель нам не интересна. В физической модели можно выбрать конкретную СУБД и в зависимости от этой СУБД настроить типы атрибутов.
Создание сущностей, отношений между ними, перетаскивание таблиц осуществляется при помощи инструментов с панели ERWin Toolbox.
 | Инструмент для создания сущностей. |
 | С помощью инструмента выбора (Select tool) можно перемещать сущности вместе с атрибутами. Имеется также инструмент для перемещения атрибутов - Attribute Manipulation Tool. |
| Для создания отношений между сущностями имеется два инструмента. Для создания отношений, в которых определено, как соотносятся записи одной таблице по отношению к другой используется инструмент - identifying relationship. В этом случае первичный ключ одной таблицы добавляется, как внешний ключ во вторую таблицу, при этом во второй таблице он является частью составного ключа. Так, например, создано отношение между таблицей авторов и таблицей aa. Для создания отношений, в которых не определено, как соотносятся записи используется - non-identifying relationship. |
В ERWin по правой кнопке мыши можно настроить детальность отображения структуры базы. Данный параграф не ставит задачей дать подробное описание системы ERWin, а лишь дать первоначальную точку отправления в освоение этого средства. Самое главное - теоретические основы были подробно разобраны в параграфе "Проектирование баз данных". Овладев ими вам будет несложно освоить систему ERWin. Базу данных проектируете вы, а не ERWin, которое только является, всего-навсего, лишь инструментом в ваших руках. В ERWin есть хороший самоучитель, который поможет вам быстро освоится. Здесь же не имеет смысла переписывать этот самоучитель, документируя все пункты меню ERWin.
ПроектированиеЦелью проектирования базы данных является определение таблиц, столбцов и отношений на основе заданного набора данных и предъявляемых функциональных требований к системе. Функциональные требования есть ни что иное, как SQL-запросы к базе данных. Обращаем ваше внимание на то, что данное определение цели проектирования принципиально отличается от распространенного в классической литературе. Так, например, К. Дейт в книге "Введение в системы баз данных" формулирует задачу проектирования базы данных, как определение таблиц, столбцов и отношений независимо от функциональных требований, а лишь на основе самих данных. "В общем проблема формулируется следующим образом: как в некоторой базе данных для заданного набора данных выбрать подходящую логическую структуру?" - пишет К.Дейт. При этом он не дает определения, а что же такое "подходящая логическая структура". Как вы помните, в главе "Язык SQL" было сказано, что основное назначение базы данных - хранение данных, многопользовательский доступ к ним и операции над ними. Практика показывает, что проектировать базу данных без учета операций над ними НЕВОЗМОЖНО. Нет ничего универсального. Чем шире универсальность, тем уже применимость системы. Поясним сказанное на простом примере. Пусть у нас есть данные о курсах, преподавателях, читающих курсы и учебниках по данным курсам.
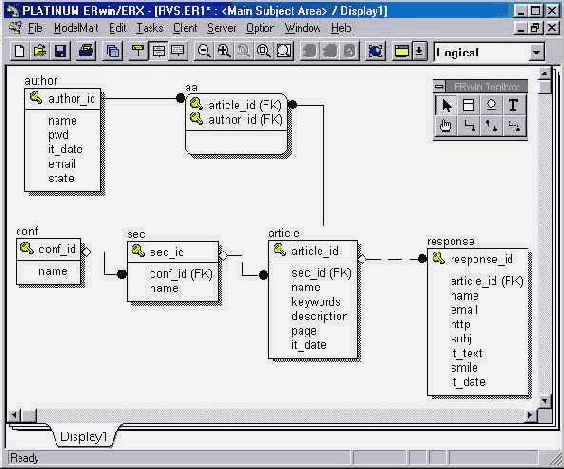
В зависимости от функциональных требований к системе каждый столбец данной таблицы может быть либо сущностью, либо атрибутом сущности, поэтому мы получаем разные структуры такой базы данных. Допустим, если мы автоматизируем работу библиотеки, то сущностью будут учебники, а данные о преподавателях и курсах пойдут, как атрибуты. В такой системе, в большинстве запросов нас будут интересовать учебники и предметы, а преподаватели просто, как сопутствующая информация. Напротив, если же мы создаем систему для отдела кадров, то нас будут интересовать в первую очередь преподаватели, во вторую читаемые ими курсы, и в самую последнюю очередь, отдел кадров интересуется учебниками, которые нужны преподавателю. Данный пример, конечно, очень упрощен, но тем не менее он отражает суть вопроса. Итак, перейдем к сути вопроса. Опять же таки, в абсолютном большинстве книжек про базы данных написано про нормализацию... Эту нормализацию давно никто не применяет и доподлинно неизвестно, а была ли эта нормализация, или же она существовала в воображении теоретиков. Мы не будем здесь разбирать абстрактные примеры и бороться с ветряными мельницами! За несколько лет работы и проектирования баз данных автору и многим его коллегам не приходилось действовать так, как учит теория и как написано в любой дурацкой книге технического пИсателя, не способного ни на что, кроме тупого переписывания справочников и других книжек. Во-первых, стоит сделать важное замечание. Процесс проектирования - это итерационный процесс. Среди этапов проектирования можно выделить следующие: Сбор данных Сбор функциональных требований На основе функциональных требований выявление сущностей и отношений между ними. Здесь выяснится, что каких-то данных не хватает или выбраны не те отношения. Сбор дополнительных данных, здесь выяснится, что на основе дополнительных данных появились дополнительные функциональные требования Сбор дополнительных функциональных требований и переход к третьему пункту, пока система не сбалансируется. В простых системах можно уложиться в 1-2 итерации. Рассмотрим пример проектирования базы данных для системы конференций. Конференция в реальном мире представляет собой съезд специалистов, каждый из которых делает доклад(ы). После доклада у слушателей имеется возможность задать вопросы. Конференция обычно делится на несколько тематических секций. Такого рода информационная система должна иметь три уровня доступа: Пользовательский. Автора статей. Администратора конференции. Функциональные требования к пользовательской части веб-сервера: Просмотр статей. Регистрация слушателя в системе. Редактирование слушателем своих данных. Возможность анонимного входа. Добавление отзыва на статью. Возможность получения уведомления об ответе на свой отзыв по электронной почте. Поиск статей по ключевым словам. Функциональные требования к уровню доступа авторов статей: Регистрация автора в системе. Редактирование автором своих данных. Добавление автором статьи в конференцию. Редактирование автором параметров своей статьи. Получение уведомления об отзыве на свою статью по электронной почте. Добавление отзыва на свою статью статью под своим уникальным именем. Функциональные требования к администраторскому доступу: Разрешение регистрации автора. Разрешение публикации статьи. Рассылка информационного сообщения по всем электронным адресам пользователей системы. Очевидным образом напрашиваются следующие сущности: конференция, секция, доклад, вопрос, специалист (автор доклада). Также довольно очевидно, что в конференции много секций, т.е. отношение один ко многим, в секции много докладов, на доклад много отзывов. Пока не совсем понятно, как соотносятся с этими таблицами администраторы, авторы и слушатели. Для начала давайте заполним эти таблицы атрибутами. В таблице конференций (conf) будет первичный ключ conf_id и название (name). Аналогичным образом и для секции (sec), sec_id, name. В таблице секции будет еще присутствовать внешний ключ, который будет ссылаться на первичный ключ conf_id таблицы конференций для осуществления связи один ко многим. В обе эти таблицы также можно включить поле описание (description), но это не обязательно. Далее идет таблица докладов article. В таблице докладов у нас первичный ключ - article_id, внешний ключ sec_id, который ссылается на первичный ключ таблицы секций, название доклада - name, ключевые слова - keywords, аннотация доклада - description, page - номер страницы в печатном сборнике и it_date - дата публикации. Теперь переходим к таблице отзывов на доклады - response. В этой таблице будет первичный ключ response_id, внешний ключ article_id, тема отзыва subj, текст отзыва it_text, иконка с улыбающейся рожицей smile и дата отзыва it_date. В таблице отзывов должны быть сведения об авторе отзыва. Но тут возникает вопрос. Казалось бы, можно просто добавить внешний ключ, ссылающийся на таблицу авторов и проблема решена. Но не так все просто. Если вы так поступите, то вы обяжете всех регистрироваться в вашей системе. С точки зрения базы данных это хорошее решение, т.к. в этом случае внешний ключ не будет содержать NULL-значений и будет обеспечиваться целостность базы данных. Но вот с точки зрения пользователя веб-сайта это плохо. Пользователь думает: "Ребята, да я вас не знаю, с чего мне тут регистрироваться, как вы будете использовать мои данные, да я вообще зашел сюда один раз статью сына прочитать и т.д.." А что делать, если пользователь хочет при подаче отзыва на статью указать адрес электронной почты отличный от того, что он указал при регистрации? Многие пользователи, опасаясь получения всевозможной незапрашиваемой корреспонденции - рекламы и т.п., имеют несколько почтовых ящиков. Адрес своего главного почтового ящика они дают только друзьям и для деловых контактов и стараются его особо нигде не светить. Для всех остальных случаев заводится ящик на бесплатном сервере, например, mail.ru или chat.ru. Итак, возвращаясь к нашим баранам, решение со внешним ключом не очень хорошее. Значит нам надо включить в таблицу response еще поля: имя автора, адрес электронной почты автора и адрес его веб-узла. Такое решение имеет тоже небольшой недостаток - избыточность данных. Если у пользователя поменяется адрес электронной почты, то нет никакой возможности изменить этот адрес в таблице отзывов. В общем-то это проблема не страшная, т.е. ничего катастрофического в том, что автор отзыва не получит сообщения по электронной почте о том, что появился еще один отзыв по теме данного доклада, нет. Можно сказать, что спасение утопающего есть дело рук самого утопающего. Мы пойдем именно по этому пути. Но если вам уж так захочется все-таки решить эту проблему, то в таблицу отзывов надо включить и внешний ключ и три атрибута об авторе отзыва. Но в этом случае нужно контролировать условие, что либо внешний ключ содержит NULL-значение, либо поля name, email & http содержат NULL-значения, иначе получится противоречие. Осталось решить, что же делать с администраторами, авторами докладов и слушателями авторов отзывов на доклады. Поскольку все они люди, но с разным статусом, то будем хранить о них данные в одной таблице. Назовем ее таблица авторов - authors. В этой таблице будет первичный ключ author_id, имя автора - name, пароль pwd, дата регистрации в системе - it_date, адрес электронной почты - email и права доступа - state. Поскольку у одного автора может много докладов, а у одного доклада много авторов, то они относятся, как многие ко многим. Итак, получаем:  |
Реляционная система управления базами данныхПочти все продукты баз данных, созданные с конца 70-х годов, основаны на подходе, который называют реляционным (relational); более того, подавляющее большинство научных исследований в области баз данных в течение последних 25 лет проводилось (возможно, косвенно) в этом направлении. На самом деле, реляционный подход представляет собой основную тенденцию сегодняшнего рынка, и реляционная модель - единственная наиболее существенная разработка в истории развития баз данных. К.Дейт, Введение в системы баз данных. Данную главу о проектировании реляционных баз данных мы начнем с определений основных понятий. Материал книги выстроен в этом плане несколько нестандартно. Обычно, изложение работы с базами данных начинается с теоретических основ. Мы же пошли от практической работы и начали с решения конкретных задач на языке SQL и разработки клиентских приложений. И теперь, когда имеется некоторый опыт работы с базами данных, мы подведем немного теории и определений. Стандартный подход плох тем, что у читателя или слушателя лекций сначала пухнет голова от теории и определений, в которых он начинает разбираться и понимать только после практической работы с базами данных. Важно также отметить, что теория баз данных сильно расходится с тем, что мы наблюдаем на практике. Итак, приступим. К.Дейт в своей классической книге "Введение в системы баз данных" дает следующее определение реляционной системы управления базами данных. Данные воспринимаются пользователем как таблицы (и никак иначе). В распоряжении пользователя имеются операторы, которые генерируют новые таблицы из старых. Как уже было сказано, таблица состоит из столбцов и записей. На пересечении столбца и записи находится ячейка. Общих ячеек, как в системе Exell, быть не может. Каждый столбец имеет заданный типа данных, а также ограничения на допустимые значения и диапазон значений. Одна из непосредственных задач СУБД (здесь и далее речь идет о реляционных СУБД, поэтому слово "реляционный" опускается) - осуществлять контроль целостности данных. Под целостностью данных подразумевается логическая непротиворечивость данных. Различают три понятия целостности: Целостность в отношении конкретной базы. Такие данные, как возраст, рост, вес не могут быть отрицательными. IP-адрес имеет строго заданный формат - это четыре числа в диапазоне от 0 до 255, разделенных точкой, плюс дополнительные ограничения на использование 0, 255 и спецадресов. Большинство СУБД не предоставляют механизмов, в полной мере позволяющих контролировать данный тип целостности. Целостность сущностей. В таблице, где хранятся записи об объектах, не может быть двух одинаковых объектов, а также не может быть неопределенных объектов, т.е. записей с неопределенным значением (NULL-значением) первичного ключа. СУБД не должна допускать записей с повторяющимися значениями первичного ключа или NULL-значением одного из компонентов первичного ключа. Данный тип целостности поддерживают все СУБД. Более подробно мы поговорим об этом понятии целостности ниже, при описании первичных ключей. Ссылочная целостность. Как вы уже видели на примере системы гостевых книг(см. рисунок ниже) в главе "Язык SQL", одной записи в таблице гостевых книг может соответствовать несколько записей в таблице сообщений. Таблицы могут находиться во взаимосвязях один к одному, один ко многим и многие ко многим. Связи между таблицами осуществляются на основании внешних ключей. В таблице сообщений не может быть сообщения, принадлежащего к несуществующей гостевой книге, иначе говоря, любой записи в таблице сообщений должна найтись запись в таблице гостевых книг. СУБД должна предоставлять механизмы для контроля операций и соблюдения ссылочной целостности при выполнении операций INSERT, UPDATE и DELETE. К сожалению, не все СУБД имеют такие механизмы.  Система гостевых книг. Рассмотрим более детально все три понятия целостности данных по порядку. К первому типу целостности относятся такие механизмы СУБД, как ограничение на диапазон допустимых значений, триггеры и транзакции. К сожалению, пока ни один из этих механизмов не поддерживается СУБД MySQL, поэтому, если ваши сайты будут базироваться на данной СУБД, то вам придется обождать до появления данных возможностей. Ограничения на значения должны появится уже в четвертой версии MySQL. При помощи ограничений на значения можно задать ограничение на формат адреса электронной почты. email varchar(32) CHECK (email LIKE '%@%'), Тем самым, запретив значения, которые не содержат знака '@'. Большинство же информационных систем применительно к веб-сайтам, будь то конференции, чаты, списки рассылки, имеют довольно простую структуру базы данных, обычно не превышающую 5-7 таблиц. В таких системах целостность данных не имеет критического значения. В случае ввода неправильного адреса электронной почты ничего катастрофического не произойдет, поэтому контроль за целостностью данных можно переложить на приложения, т.е. CGI-программы. Механизм триггеров позволяет СУБД контролировать операции INSERT, UPDATE и DELETE на предмет допустимости этих операций. Например, таким образом, вы можете ограничить число публикуемых сообщений в день от одного пользователя или запретить вводить сообщения, длиной более 255 символов, лицам, незаполнившим поля email и http. И наконец, последний механизм транзакций, о котором вам необходимо иметь представление, позволяет контролировать выполнение блоков SQL-запросов. Транзакция представляет собой набор SQL-запросов, и СУБД гарантирует, что либо все эти запросы будут выполнены, либо же ни один из них не будет выполнен. Транзакции могут применятся при вставке, изменении и удалении данных в нескольких таблицах. Например, вам необходимо в системе гостевых книг объединить две гостевые книги в одну. Для этого необходимо изменить идентификатор гостевой книги gb_id в таблице сообщений, удалить одну запись из таблицы гостевых книг и, возможно, модифицировать запись о первой гостевой книге. И мы должны быть полностью уверены в том, что либо эти операции пройдут успешно, либо же не будет выполнена ни одна из них. Далее мы рассмотрим целостность сущностей. Как уже было сказано выше, целостность сущностей базируется на первичном ключе. Мы дадим определение первичного ключа и рассмотрим ряд примеров таблицы и методов выбора первичных ключей. Первичный ключ - это столбец или группа столбцов в одной таблице таких, что не может существовать двух записей с одинаковым значением этого столбца или группы столбцов, причем для случая группы столбцов никакое подмножество столбцов не является уникальным. Можно выделить принципиально различающиеся три случая: в таблице отсутствует первичный ключ; простой первичный ключ, т.е. состоящий из одного столбца; составной первичный ключ, т.е. состоящий из нескольких столбцов. Рассмотрим первый случай, когда в таблице может и не быть первичного ключа, как, например, в таблице hit в системе анализа посетителей веб-сайта. В этой таблице просто нет столбцов, которые могли бы образовать первичный ключ. В таблице, чисто теоретически, с очень малой долей вероятности могут быть полностью одинаковые строки. Один пользователь может запустить на своем компьютере два броузера и открыть в них страницу нашего сайта. Из-за того, что ни операционная система, ни протокол TCP\IP не работают в реальном времени, и в них имеются задержки по времени, есть вероятность того, что открытие в этих броузерах нашей страницы произойдет одновременно. Соответственно, поскольку броузеры одни и те же, работают на одном компьютере, то программа counter внесет в таблицу hit две одинаковые строчки. Также небольшое пояснение, что CGI-программа counter может быть запущена одновременно несколько раз, и что сервер тоже работает не в реальном времени, поэтому и есть вероятность появления одинаковых строк. В таблице hit нет необходимости различать записи, т.е. иметь первичный ключ. Если бы такая необходимость была, то можно было бы добавить в таблицу счетчик записей. В СУБД MYSQL это делается следующим образом: CREATE TABLE hit( hit_id int(10) unsigned NOT NULL auto_increment, ... ) При вставке новой записи hit_id будет увеличиваться на единицу, тем самым мы получим возможность различать записи внутри таблицы. В системе гостевых книг первичными ключами являются поля gb_id в таблице гостевых книг и message_id в таблице сообщений. На практике чаще всего встречается именно такой способ назначения и использования первичных ключей. В таблицах системы гостевых книг первичные ключи служат для идентификации записей и установления отношения один ко многим. В классической теории для соблюдения целостности сущностей необходимо назначать первичным ключом столбец или группу столбцов, которые однозначно идентифицируют объект. Но в реальности, зачастую, таких столбцов может и не быть. Ни в таблице сообщений, ни в таблице гостевых книг нет осмысленной группы столбцов, которую бы можно было назначить первичным ключом. В данном случае, первичным ключом можно только сделать все столбцы таблицы сообщений, но, в этом случае, мы осложняем себе жизнь при выборе конкретного сообщения. В запросе SELECT * FROM message WHERE name='name' AND email='email' AND... придется перечислить совпадение для каждого столбца. Такая выборка будет происходить медленно, т.к. нужно затратить время, чтобы выполнить сравнение для каждого столбца. Гораздо удобнее ввести счетчик, тогда запрос будет выглядеть значительно проще: SELECT * FROM message WHERE id='id'. Если же у вас в таблице имеется все же столбец или несколько столбцов, однозначно идентифицирующих объект, то их бесспорно стоит назначить первичным ключом. Например, у вас база данных по автомобилям, в этом случае, первичным ключом будет номер автомобиля. Не стоит пугаться того, что номер автомобиля представляется символьной строкой. Когда вы назначаете столбец или группу столбцов первичным ключом, по ним автоматически создается индекс. Индекс представляет собой хеш-таблицу, т.е. таблицу из двух колонок: в первой колонке в отсортированном порядке идут значения первичного ключа, а во второй колонке - указатель на то место, где лежит полная запись таблицы. Поскольку первая колонка отсортирована, то операции поиска по такой таблице происходят на порядок быстрее, чем если бы индекса не было. Для всех полей таблицы, которые участвуют в предложении WHERE SQL-запросов, надо обязательно создавать индексы. Однако, учтите, что индекс ускоряет поиск только в случае, если его значения слабо повторяются. Одним словом, если вы сделаете индекс по полю "пол", то никакого ускорения не получится, т.к. половина хеш-таблицы будет состоять из одних записей, а половина из других. В MySQL индекс создается следующей командой: CREATE [UNIQUE] INDEX index_name ON tablename (column1, column2, ...) Составной первичный ключ может быть в таблице по персоналиям, где серия и номер паспорта представлены в отдельных колонках. В этом случае эти две колонки будут образовывать составной первичный ключ. Внешний ключ - это столбец или группа столбцов в одной таблице R1, совпадающих по типу данных с первичным ключом в таблице R2, и каждому значению этого столбца или группы столбцов в таблице R1 обязательно должно найтись совпадающее с ним значение в таблице R2. В нашем примере системы гостевых книг внешним ключом в таблице сообщений является поле gb_id, которое ссылается на поле gb_id в таблице гостевых книг. Оба этих столбца имеют одинаковый тип - int. В данном случае, внешний ключ состоит из одного столбца и именуется простым внешним ключом. В случае, если бы внешний ключ состоял из нескольких столбцов, он назывался бы составным. Обратите внимание, в случае составного внешнего ключа определение требует, чтобы типы столбцов совпадали. Определение внешнего ключа также говорит, что в таблице сообщений не может существовать записей, не относящихся ни к одной гостевой книге. Хотя обратное может быть, т.е. могут быть гостевые книги, не содержащие ни одного сообщения. Давайте теперь рассмотрим, а что будет при попытке вставить сообщение с полем gb_id, не совпадающим ни с одной записью из таблице гостевых книг, или же удалить запись из таблицы гостевых книг. Здесь действует третий тип целостности, называемый ссылочной целостностью. СУБД должна контролировать операции INSERT, UPDATE и DELETE так, чтобы данные не оказались в подвешенном (противоречивом) состоянии. Для этих целей существуют два механизма. Один из них был уже нами поверхностно рассмотрен - это механизм триггеров. Второй механизм позволяет задать правила для связей по внешним ключам. СУБД предоставляют возможность либо ограничить, т.е. отвергнуть некорректные операции, либо же произвести каскадные изменения, т.е. при удалении записи из таблицы гостевых книг будут удалены все соответствующие ей по внешнему ключу записи из таблицы сообщений. Далее мы рассмотрим типы отношений между таблицами: Отношение один ко многим Отношение многие ко многим Отношение один к одному Отношение один ко многим мы уже детально рассмотрели на примере системы гостевых книг. Данного типа отношения реализуются при помощи внешнего ключа в одной таблице, который ссылается на первичный ключ другой таблицы. Рассмотрим пример базы данных системы конференций. На конференцию авторами докладов подаются статьи. У каждой статьи может быть несколько авторов. У каждого автора может быть несколько статей. Подобного рода отношения называются многие ко многим и реализуются при помощи дополнительной таблицы с двумя внешними ключами, которые образуют первичный ключ, см. рисунок.  Вы видите таблицу авторов, которая относится к таблице aa (сокращение от authorarticle), как один ко многим. Это означает, что для одной записи в таблице авторов может быть несколько записей в таблице aa. Аналогичным образом и таблица статей относится к таблице aa, как один ко многим. А между таблицами авторов и статей реализуется отношение многие ко многим. Теперь поговорим об отношениях один к одному. Вообще говоря, в некоторой литературе можно встретить утверждения, что подобного рода отношения есть аномалия, и что если у вас такое отношение между таблицами получилось, то, скорее всего, их лучше объединить в одну таблицу. На самом деле, это далеко не так, и мы сейчас это продемонстрируем. Итак, реализация отношения один к одному - это когда первичный ключ одной таблицы ссылается на первичный ключ другой. Такого рода отношение встречается значительно реже. Вот пример из нашей практики. 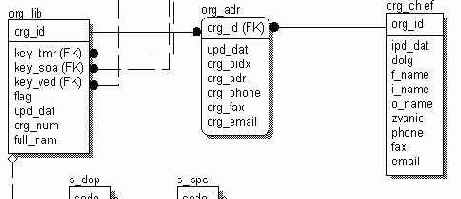 На рисунке изображен фрагмент базы данных, где отображены три таблицы: организаций, адресов организаций и руководителей организаций. Таблица организаций содержит название организации, описание ее функций, различные коды и т.д. Таблица адресов содержит данные исключительно об адресе. А таблица руководителей - о персоналиях, занимающих руководящие посты. Отношение между этим таблицами один к одному, т.к. организация может быть зарегистрирована строго по одному адресу и иметь одного руководителя. Поясним, почему нельзя объединить эти таблицы. Каждая из этих таблиц описывает свои объекты, атрибуты которых совершенно не связанны, т.е. звание руководителя никак не связано с улицей, где находится организация. В свою очередь, таблица организаций имеет отношение один ко многим со своими подразделениями, тоже можно сказать и про таблицу руководителей, которая находится в отношении один ко многим с подчиненными руководителя. Если объединить все три таблицы в одну, то получится путаница. Вы получите, что адрес организации состоит в отношении один ко многим с подчиненными руководителя, т.е. данные сольются без всякого смысла. Немаловажен и тот критерий, что работать с этими данными станет неудобно, и запросы будут выполняться медленнее. Следующий классический пример отношения один к одному, т.е. связи двух таблиц по первичным ключам - это реализация подтипа данных. Допустим, вы делаете базу данных для магазина, торгующего автомобилями. У вас будет таблица с общими характеристиками автомобиля, например: цвет, стоимость, дата выпуска и тип (иномарка или отечественная). При описании реального проекта характеристик будет значительно больше. А теперь представьте, что поскольку машины могут быть отечественного производства и иномарки, то у машин отечественного производства есть свои параметры, которых нет у иномарок, например, гарантия завода изготовителя. В то же время и у иномарок есть свои параметры, которых нет у отечественных машин, например, из какой страны импортирована, пошлина, размещение руля (слева или справа). Здесь приходит на выручку отношение один к одному, т.е. мы реализуем своего рода подтипы, см. рисунок. 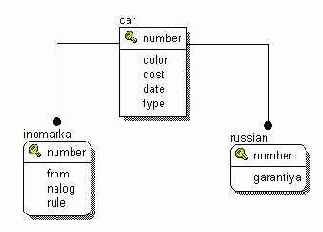 Любой записи в таблице car в зависимости от значения поля type соответствует запись либо в таблице inomarka, либо в таблице russian. |
Система форумов"Система форумов близка по сути к системе конференций, но имеет различия, вследствие которых структуры баз данных этих систем сильно различаются. У нас нет секций. Вместо докладов есть главные сообщения. Главное сообщение отличает от обычного только тем, что обычное сообщение является ответом на какое-то сообщение, а главное начинает новую тему. У одного сообщения всегда один автор. Тем не менее, это довольно упрощенная модель, в реальности условий значительно больше. Спроектируйте структуру базы данных для системы форумов. |
Аутентификация, идентификация и несанкционированный доступАутентификация - это процесс, в ходе которого на основании пароля, ключа или какой-либо иной информации, пользователь подтверждает, что является именно тем, за кого себя выдает. Идентификация - это процесс, в ходе которого выясняются права доступа, привилегии, свойства и характеристики пользователя на основании его имени, логина или какой-либо другой информации о нем. При входе пользователя в систему первым делом происходит его аутентификация. Если введенные логин и пароль совпадают с хранимыми в системе на сервере, то пользователь успешно входит в систему, иначе ему отказывается в доступе. Здесь уместно контролировать количество попыток, дабы избежать подбора паролей. В зависимости от сложности и надежности системы необходимо выбрать механизм работы с паролями. В самом простом случае можно разрешить пользователю самостоятельно вводить пароль. Но достаточно большое количество пользователей в качестве пароля вводит свой: логин, имя, номер телефона и т.п. Это можно разрешить только в тех системах, где проблема защиты информации пользователя является его собственным делом и не нанесет вреда системе в целом. Например, сервер бесплатных бюджетов пользователей chat.ru разрешает устанавливать пароль самостоятельно. В серьезных системах необходимо генерировать пароль пользователю случайным образом. В библиотеке ITCGI есть функция GeneratePassword, которая генерирует уникальный пароль. Обратите внимание, что даже в случае, если запущены одновременно несколько копий CGI-скрипта эта функция генерирует уникальный пароль, т.к. генератор основывается не только на текущем времени, но и на идентификаторе процесса CGI-программы. Логин и пароль необходимо передавать исключительно методом POST. При методе GET данные кэшируются прокси-серверами и броузерами, т.е. вероятность узнать ваш пароль значительно выше. При методе POST кэширование не происходит. Следующим важным вопросом аутентификации мы рассмотрим проблему аутентификации при вызове каждого нового скрипта. Проблема заключается в том, что пароль пользователь вводит только один раз при первом входе в систему, а аутентификацию надо производить каждый раз, когда он обращается к какому-либо CGI-скрипту.
</form> /* * (c) Copyright 1995-2000, Igor Tarasov * http://itsoft.ru * FidoNet: 2:5020/370.2 620.20 1103.5 * email: igor@itsoft.ru itarasov@rtuis.miem.edu.ru * Phone: (095)916-89-51 916-89-63 */ #include <stdio.h> #include <stdlib.h> #include <mysql.h> #include <itcgi.h> int main() { MYSQL* pDB; MYSQL_RES* res; //параметры соединения с базой LString* db = CreateString(); LString* user = CreateString(); LString* pwd = CreateString(); LString* url = CreateString(); LString* sql_query = CreateString(); LString *key = CreateString(); LString *login = CreateString(); LString *password = CreateString(); pDB = mysql_init(NULL); if(!pDB) { printError("Ошибка!", mysql_error(pDB)); return -1; } //считываем CGI-параметры и формируем SQL-запрос //таблица student содержит данные о студентах, //в том числе их логины и пароли GetParamByName("url", url); GetParamByIndex(2, login); GetParamByIndex(3, password); LString_Format(sql_query, "SELECT * FROM student WHERE id=%s AND pwd=password('%s')", *login, *password); GetRCParam(0, 0, "db", db); GetRCParam(0, 0, "user", user); GetRCParam(0, 0, "pwd", pwd); //соединяемся с базой if( !mysql_real_connect(pDB, NULL, *user, *pwd, *db, 0, NULL, 0) ) { printError("Ошибка!", "mysql_real_connect: %s\n", mysql_error(pDB)); goto LABEL_END; } //выполняем SQL-запрос if( mysql_query(pDB, *sql_query) ) { printError("Error!", "mysql_query: SQL=%s<br> %s\n", *sql_query, mysql_error(pDB)); goto LABEL_END; } //если логин и пароль правильные генерируем ключ res = mysql_store_result(pDB); if( res && res->row_count ) { mysql_free_result(res); if(!GetKey(pDB, key, *login, *password, 3600)) { printError("Error!", "mysql_query: %s\n", mysql_error(pDB)); goto LABEL_END; } } else { printError("Error!", "Password incorrect..."); goto LABEL_END; } //перенаправляем пользователя на //http://test.itsoft.ru/main.html?key=key printf("Location: http://%s/%s?key=%s\n\n", getenv("SERVER_NAME"), *url, *key); LABEL_END: mysql_close(pDB); DeleteString(db); DeleteString(user); DeleteString(pwd); DeleteString(sql_query); DeleteString(url); DeleteString(key); DeleteString(login); DeleteString(password); return 0; } =====Makefile==== #/* # * (c) Copyright 1995-2000, Igor Tarasov # * http://itsoft.ru # * FidoNet: 2:5020/370.2 620.20 1103.5 # * email: igor@itsoft.ru itarasov@rtuis.miem.edu.ru # * Phone: (095)916-89-51 916-89-63 # */ all: auth auth: auth.c itcgi.a gcc auth.c -L/usr/local/lib/mysql -I/usr/local/include/mysql \ -L/usr/local/lib -I/usr/local/include \ -o auth -lmysqlclient /usr/lib/itcgi.a -Wall -O3 strip auth Далее, каждый CGI-скрипт считывает переменную key, производит аутентификацию. Ниже приведен пример программы демонстрирующей данную возможность. #include <stdio.h> #include <mysql.h> #include "itcgi.h" #include "lstring.h" int main() { MYSQL* pDB; LString* db = CreateString(); LString* user = CreateString(); LString* pwd = CreateString(); LString* key = CreateString(); LString* HTML = CreateString(); char str[4096]; pDB = mysql_init(NULL); if(!pDB) { printError("Внимание! Ошибка!", mysql_error(pDB)); return -1; } printf("Content-type: text/html; charset=windows-1251\n\n"); GetRCParam(0, 0, "db", db); GetRCParam(0, 0, "user", user); GetRCParam(0, 0, "pwd", pwd); if( !mysql_real_connect(pDB, NULL, *user, *pwd, *db, 0, NULL, 0) ) { printf("mysql_real_connect: %s\n", mysql_error(pDB)); goto LABEL_END; } //получаем значение ключа //по которому определяем логин и пароль пользователя GetParamByName("key", key); if( !GetLoginPwd(pDB, *key, user, pwd) ) { printf("Внимание! Ошибка!", "Error password!"); goto LABEL_END; } LString_SetString(HTML, "<tr><td><a href=\"/cgi-bin/st_testinfo?id=%%id%%&key=%%key%%\" title=\"%%description%%\">%%name%%</a></td> <td>%%questions%%</td></tr>"); sprintf(str, "select test.id, test.name, questions, description FROM test, question WHERE test.id=question.test_id GROUP BY test.id, test.name, questions HAVING questions<=COUNT(*)"); if( GetHTMLFromSQL(pDB, str, HTML, NULL) ) { LString_Replace(HTML, "%%key%%", *key); printf("%s",*HTML); } LABEL_END: mysql_close(pDB); DeleteString(db); DeleteString(user); DeleteString(pwd); DeleteString(key); DeleteString(HTML); return 0; } Следующей важной задачей в многопользовательских информационных системах является задача разграничения доступа. Мало только убедится в том, что пользователь ввел верные логин и пароль, необходимо также удостоверится, а разрешено ли ему выполнять запрашиваемые операции. Злоумышленник, например, может зарегистрироваться в вашей системе и удалить или получить доступ к чужим данным, если вы не будете выполнять процесс идентификации пользователей. Поэтому обязательно проверяйте допустимость выполняемой операции тем или иным пользователем. |
Безопасность CGI
Данная глава посвящается вопросам безопасности CGI-программ. Неправильно работающая CGI-программа, в лучшем случае, завершается с ошибкой, в худшем, ведет к нарушению работы сервера или его взлому. Программа должна корректно работать в любых ситуациях. Другими словами, независимо от того, что было подано на вход программе, независимо от имеющихся свободных ресурсов, программа не должна зависать или падать. Исключение составляют следующие причины: сбой на аппаратном уровне или сбой на уровне операционной системы. Если на вход программы поданы данные неверного типа или выходящие за допустимый диапазон значений, то программа обязана сообщить об этом. Если не хватает системных ресурсов, как правило, оперативной памяти, то программа опять обязана выдать сообщение об ошибке и корректно завершить свою работу. Данные утверждения справедливы по отношению ко всем программам, не только к CGI-скриптам. Далее мы рассмотрим наиболее распространенные ошибки программистов и причины взлома веб-сайтов и серверов. |
Фильтрация и форматирование HTML-документовПожалуй, это самая распространенная проблема, в особенности для начинающих веб-программистов, хотя и опытные специалисты часто забывают или не совсем правильно обращаются с HTML-кодом. Данная проблема связана со скриптами, которые выдают заголовок Content-type: text/html\n\n и соответственно генерируют HTML-код. Для всех остальных CGI-программ данной проблемы не существует! Обратите внимание, что HTML-код необходимо фильтровать именно на выходе. Очень часто делают ошибку, когда фильтруют HTML-код перед тем, как сохранить его на сервере в файле или базе данных. Это неправильно. Поясним ситуацию на примере чата, рассмотренного в восьмой главе. Любой пользователь может в качестве сообщения ввести HTML-команды. Если он решил немного раскрасить свой текст, то, конечно, ничего страшного в этом нет, при условии, что он умеет пользоваться командами font, b, i, u и другими. Теперь представьте ситуацию, когда он либо не умеет ими пользоваться, либо просто забыл поставить закрывающую команду или угловую скобочку - >, или же это злоумышленник, который вполне отдает себе отчет в том, что делает. Итак, в чат могут ввести что-нибудь типа: =====Пример №1====== </table> ==================== =====Пример №2====== <img src="http://mysite.ru/very_big_image.jpg" width=10000 height=10000> ==================== =====Пример №3====== <script language="JavaScript"> window.open('http://mysite.ru','_top'); </script> ==================== Можно дальше сочинять, но думаю этого достаточно, в особенности для тех, кто тут же решит попробовать себя в роли злоумышленника. Возможно стоит прокомментировать примеры. В примере номер один дана команда закрыть таблицу, которая скорее всего приведет к тому, что чат, гостевая книга или форум будут отображаться некорректно в броузере пользователя. Во втором примере загружается картинка очень большого объема. Скорее всего, пользователь не дождется загрузки страницы, а если и дождется, то увидит опять что-то непотребное. Ну и в третьем примере, пользователь будет сразу же переброшен на веб-сайт злоумышленника. Для того чтобы такого рода ситуации исключить, необходимо фильтровать HTML-код, когда CGI-программа выдает его пользователю. В нашем случае необходимо заменять все < и > на < и > соответственно. В библиотеке ITCGI имеется функция ReplaceLTGT. В результате, пользователю выдастся следующий безобидный текст, который броузером не будет воспринят, как HTML-команды, а будет отображен, как обычный текст. =====Пример №1====== </table> ==================== =====Пример №2====== <img src="http://mysite.ru/very_big_image.jpg" width=10000 height=10000> ==================== =====Пример №3====== <script language="JavaScript"> window.open('http://mysite.ru','_top'); </script> ==================== С фильтрацией не переусердствуйте, помните, что не стоит фильтровать все в подряд, а только то, что может быть введено злоумышленником. Иначе может получится, что вместо оформленной части HTML-документа пользователь увидит исходный HTML-код. Иногда ставится задача не полной фильтрации HTML-команд, т.е. когда при написании сообщений в чат, гостевую книгу или форум разрешается пользователям использовать ограниченный список HTML-команд с ограниченным множеством атрибутов и ограниченным диапазоном значений этих атрибутов. Сама по себе такая задача непростая и выходит за рамки этой книги, если вы не уверены в своих силах и не можете просчитать все варианты использования дозволенных HTML-команд, то лучше не беритесь за подобного рода задачи, т.к. будет большая вероятность взлома вашего веб-сайта. Помните еще одну простую формулу: безопасность обратно пропорциональна удобству. Или же лучшее - враг хорошего. Помимо фильтрации HTML-кода еще существует проблема форматирования текста в сообщениях гостевых книг и форумов. Поясним задачу. Допустим пользователь ввел в поле ввода: 1. Лайтмэпинг в OpenGL. В случае если видюха поддерживает мультитекстуринг, то все понятно, но в случае если нет?.. Я так думаю нужно использовать Alpha blending, но в таком случае лайтмэпы будут только grayscalовые.... Может кто подскажет как сделать правильнее? 2. Каким образом и откуда импортируются функции расширений OpenGL? Например у меня ни как не получилось импортировать из opengl32.dll функции glLockArraysEXT и glUnlockArraysEXT, хотя видеокарта их поддерживает (кстати в opengl32.dll этих функций и нет, но есть они в gfxglicd.dll - входящий в комплект дровов моей I740, но т.к. это частный случай, то я думаю есть универсальный метод импорта этих функций). 3. Последний вопрос. При создании портального движка необходимо определять видимость объектов (их BoundingBox-ов) через BoundingRectangle проекции портала. Кто знает как это лучше (быстрее) всего сделать в OpenGL? (я так думаю что-то с FeedBack буфером?) Дата: 11-16-2001 на 21:04 Если данный текст не форматировать перед выводом, то его вид получится отвратительным - не будет переносов на новую строку, несколько пробелов сольются в один, а если в тексте имеется очень длинное слово, то ширина HTML-документа будет выровнена по ширине этого слова и скорее всего окажется больше, чем запланирована. Обычно таких слов не встречается, однако злоумышленники могут написать что-нибудь типа aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa и т.д. Форматирование текста в отличии от фильтрации HTML-команд не ведет к неправильной работе того или иного раздела веб-сайта, а лишь сказывается на оформление текста. В связи с вышеизложенными проблемами необходимо: \n заменять на <br> два пробела на пробел через каждые n символов без пробела вставлять пробел, чтобы таблица не расползлась В библиотеке ITCGI для этого есть функции FormatText и FilterBR. |
Переполнение буфераПереполнение буфера связано с неправильным обращением с оперативной памятью и приводит, в большинстве случаев, к краху программы. Наиболее часто эта проблема проявляется при работе со строками, при копировании и форматировании строк. Рассмотрим следующий пример: char str[4096]; ... sprintf(str, "INSERT INTO answer( rezult_id, q_id, answer, mark,\ seconds) VALUES ('%s', '%s', '%s', '%s', %d)", *rezult_id, *q_id, answer, row[1], sec1); В случае если размер форматируемой строки окажется больше, чем 4096 символов, то скорее всего произойдет сбой при исполнении программы. Это приведет к сообщению, которое пользователь увидит в своем броузере Internal Server Error. Оно означает, что CGI-программа не выдала корректного содержания. Такое случается в случае аварийного завершения или неправильного заголовка Content-type. Заранее узнать точный размер форматируемой строки не представляется возможным, можно лишь сделать допущения относительно его максимального размера. Иногда эти допущения оказываются ошибочными. Мы предполагаем одно, а пользователь программы, в данном случае это посетитель веб-сайта ведет себя совершенно по-другому. Мне самому до последнего времени иногда бьют по лбу эти грабли. Для того чтобы избежать подобного рода ошибок контролируйте размер переменных поступающих на вход CGI-программы и любых других, полученных из файлов или баз данных в ходе выполнения программы. Не доверяйте контроль размера переменных атрибуту maxlength или JavaScript! Всегда помните о злоумышленниках, которые могут вызвать вашу CGI-программу со своими параметрами. Делается это очень просто. Если CGI-скрипт может принимать параметры методом GET, то в командной строке броузера злоумышленник напишет обращение к вашему скрипту: http://your_site.ru/cgi-bin/script?p1=v1&p2=v2...pk=vk. Если же скрипт принимает параметры методом POST, то злоумышленник сделает следующий HTML-документ: <form method=post action="http://your_site.ru/cgi-bin/script"> <input type="hidden" name="p1" value="v1"> <input type="hidden" name="p1" value="v1"> ... <input type="hidden" name="pk" value="vk"> </form> И как вы догадываетесь, имена параметров, их значения и размеры могут быть какими угодно. В лучшем случае, неправильные параметры приведут к аварийному завершению программы. В худшем, злоумышленник осуществит взлом вашего сервера. Для того чтобы обезопасить себя от вызова скриптов вышеуказанными методами, проверяйте значение HTTP_REFERER - откуда был вызван CGI-скрипт. Если пользователь нажал кнопку Submit или гиперссылку на скрипт на вашем сайте, то переменная окружения HTTP_REFERER должна содержать адрес вашего сайта. Полезно также записывать значение переменной REMOTE_ADDRESS, которая содержит IP-адрес пользователя. В случае если вам в гостевой книге напишут какие-либо нецензурные ругательства можно будет будет определить, кто это сделал. Но особо полагаться на значение HTTP_REFERER тоже нельзя, т.к. это значение посылается броузером. Хакер может взламывать ваш сайт при помощи своего броузера собственной разработки или программы telnet и подделать это значение. Никогда не используйте функцию sprintf, вместо нее используйте snprintf или LString_Format из библиотеки ITCGI. snprintf гарантирует, что переполнения буфера не произойдет, но при этом форматируемая строка будет урезана. LString_Format работает с типом LString, под который выделяет динамически необходимое количество памяти. char str[4096]; ... snprintf(str, 4096, "INSERT INTO answer( rezult_id, q_id, answer,\ mark, seconds) VALUES ('%s', '%s', '%s', '%s', %d)", *rezult_id, *q_id, answer, row[1], sec1); ================================ LString* sql_query = CreateString(); .... LString_Format(sql_query, "CREATE TEMPORARY TABLE IF NOT EXISTS hh \ SELECT COUNT(*) as hit, ip FROM hit \ WHERE DATE_FORMAT(it_date, '%%Y-%%m-%%d')='%s' \ GROUP BY ip ORDER BY hit DESC", *day); .... DeleteString(sql_query); Еще один момент, о котором стоит сказать, так это об использовании функции printf для вывода HTML-кода. Никогда не пишите printf(html);, т.к. в этом случае все проценты, которые находятся в строке html будут интерпретированы функцией printf, как формат передаваемых ей параметров. В лучшем случае, эти проценты будут просто съедены, в худшем - последствия непредсказуемы. Правильно писать: printf("%s", html); В этом случае вывод html-кода пройдет нормально и с процентами ничего не случится. |
Работа с файловой системойСледующим важным аспектом безопасности является работа с файловой системой. Одна из самых распространенных ошибок начинающих веб-разработчиков - это создание файлов данных CGI-программ в директории cgi-bin. Это потенциальная дыра, т.к. файлы в папке cgi-bin могут быть запущены на выполнение. Допустим, ваша информационная система позволяет заливать картинки на сервер. Предположим, что в качестве информационной системы рассматривается аукцион или публикация статей. В такого рода системах необходимо заливать на сервер файлы данных: статью, картинки. Теперь представьте, что вместо статьи или картинки вам на сервер зальют исполняемый файл. Далее злоумышленник наберет в своем броузере запрос http://your_domen.ru/cgi-bin/file.exe. В Unix системах у файла есть атрибуты доступа на чтение, запись и выполнение. Если атрибут на выполнение не установлен, то запустить файл не получится. В windows любой файл с расширением exe, bat или com считается исполняемым. Если ваш CGI-скрипт выдает файлы данных с сервера, основываясь на запрашиваемом идентификаторе, то вам необходимо быть бдительными, чтобы не выдать с сервера секретную информацию. Ни в коем случае не используйте в качестве указания запрашиваемого файла в CGI-параметрах относительные или абсолютные пути к файлу. Злоумышленник получит возможность запрашивать с вашего сервера любые файлы. Одним из первых будет запрошен файл паролей - /etc/passwd. Пользуйтесь, как было указано выше, идентификатором. Пусть это будет либо число, либо слово, которое будет обозначать имя строго одной директории или файла. Неплохо, чтобы вы добавляли к полученному идентификатору префикс или суффикс. Например, надо показать статью под номером 129; значит, чтобы получить путь к файлам на сервере, вам надо скомпоновать строку path+'/'prefix+129. Еще лучше хранить на сервере таблицу соответствий между идентификатором и данными на диске, на которые он ссылается. Обратите особое внимание, что вам необходимо отфильтровать наличие двух точек и слешей. Злоумышленник может ввести не 129, а ../../../etc/passwd, и тем самым, опять заполучить секретную информацию. |
Выполнение команд на сервере, работа с файлами и СУБДПомимо размера переменных необходимо проверять их актуальность, т.е. принадлежность к определенному типу данных и допустимому диапазону значений. Например, рост, вес и цена не могут быть отрицательными, а адрес электронной почты, адрес сайта и телефон имеют строго определенный формат и допустимый набор символов. Наиболее важным и распространенным случаем проверки допустимости значения параметра является использование данного параметра при выполнение команды на сервере, отправки запроса в базу данных или же при любом другом взаимодействие CGI-скрипта со внешней средой. Совсем недавно мною была обнаружена такого рода ошибка на нашем веб-сайте . На этом сайте уже более полугода работал скрипт, который позволял получать справку по различным командам.  Посетитель сайта вводил команду в поле ввода и нажимал кнопку показать. Запрос отправлялся на сервер, где CGI-скрипт выполнял команду 'man $userparam'. Параметр пользователя фильтровался на разные спецсимволы типа "';| и т.п. Но на амперсанд (&) фильтра не было, поэтому когда я ввел: "rm&&ls -l", мне после справки на команду rm, сервер выдал содержание текущей директории. Два && для Unix shell служат разделителем команд, и Unix shell выполняет команды разделенные && последовательно. Злоумышленник дал бы другую команду: "ls&&rm -r /". Для тех, кто не знаком с операционной системой Unix, 'rm -r /' означает рекурсивное удаление всех данных сервера. В нашем случае такая команда не привела бы к полному удалению всех данных, т.к. данная программа выполняется c правами определенного пользователя и были бы удалены только данные этого пользователя. Дмитрий Нечволод, специалист по информационной безопасности из Digital Infinity (http://diginf.ru), рассказал мне более интересную историю, когда на сервере предоставляющем бесплатные акаунты типа chat.ru при регистрации в поле логин он ввел что-то наподобие: "username&&rm -r /". В этом случае при заведение нового пользователя CGI-скрипт должен работать с правами суперпользователя (администратора) и в данном случае было удалено все содержимое сервера. Далее приведен список символов, которые необходимо фильтровать при выполнение команд в Unix shell: &;`'\"|*?~<>^()[]{}$\n\r. Еще лучше построить алгоритм фильтрации не по принципу, что не запрещено, то разрешено, а наоборот, т.е. пропускать только допустимые символы, например буквы и цифры. При вызове в языке Си функций system, popen и любых других, тщательно проверяйте, что вы им передаете в качестве параметров, т.к. это наиболее страшная дыра в безопасности CGI-программ. Особо хочется заострить внимание на связи с базами данных. При выполнении SQL-запросов тоже необходимо производить фильтрацию CGI-параметров на допустимость значений, а также экранировать спецсимволы. Например, при работе MS Access необходимо экранировать апостроф, заменяя его на двойной апостроф. Помимо апострофа есть и другие спецсимволы языка SQL, например %. В MySQL API есть функции mysql_escape_string и mysql_real_escape_string(), которые экранируют специальные символы в строке. Но эти функции экранируют только следующие символы в строке: (ASCII 0), '\n', '\r', '\', ''', '"', и Control-Z. При использовании CGI-параметра в условии WHERE или HAVING есть еще два символа, которые необходимо экранировать - это '%' и '_'. При выполнении запроса SELECT * FROM tablename WHERE login='_fox' будет выдана не одна запись со значением логина '_fox', а все записи с логинами из четырех символов, где последнии три символа fox. Если при выполнении запроса типа SELECT такого рода ошибка быстро обнаружится, то при выполнении запроса типа DELETE, ошибка скорее всего будет обнаружена не сразу, и самое главное, что последствия уже будут катастрофическими. |
Делайте одинаковое одинаковымЕсли вы ставите фигурную скобку на новой строке или пробел после if, то будьте последовательны в своих действиях. ФатальнаяОшибка, которая не позволяет работать с системой. Например, сбой системы или неправильная логика работы. Имена переменных и функций должны быть осмысленными;-) Везде это пишут и, все равно, как только не называют. Иногда необходимо писать комментарииВ большинстве случаев хороший код не нуждается в комментариях, т.к. и так все ясно. Но все, же иногда, комментарии нужны. Если вам потребовалось слишком много комментариев, то стоит задуматься над тем, что ваш код безнадежно плохо написан, и стоило бы его переписать. Исходный текст программы должен быть отформатированДелайте отступы, переходы на новую строку, не надо экономить место на диске. Программа должна легко читаться человеком. КодированиеПрограмма аварийно завершилась, повисла или выдала, что 2х2 неравно 4. Локализация ошибкиПрограмма - это черный ящик, который что-то принимает на вход и выдает что-то на выходе. Первое, что вам необходимо сделать - понять, где именно в этом черном ящике происходит сбой. Для этого, уменьшайте количество параметров, передаваемых на вход программы. Добейтесь двух малоразличимых наборов входных параметров, чтобы при одном из них программа работала, а при другом нет. Надежность и качествоНадежность - количественная характеристика продукции сохранять определенные свойства в заданных условиях в течение заданного времени с определенной вероятностью. Качество - показывает насколько точно продукция удовлетворяет требованиям пользователей. Не существует методов измерения надежности и качества программного обеспечения. Приминительно к информационным системам вообще сложно определить, что такое надежность. Можно ли принять равной единицы(т.е. считать абсолютно надежной) программу '"Hello, World!'? Неизвестно, т.к. эта программа может не сработать при аппартном сбое, из-за нехватки системных ресурсов, ошибки оператора, допущенной при запуске в командной строке операционной системы и еще целой кучи факторов. Все что есть на данную тему(количественного измерения) в книгах и статьях - словоблудие и наукообразие. Как правило, это попытки перенести терминологию и методы оценки надежности аппаратуры на информационные системы. Тем не менее можно говорить о методах повышения характеристик надежности и качества, а также не о количественной, а о качественной оценки данных характеристик. Мы можем говорить о том, что одна программа или информационная система более надежна и\или качественна, чем другая. Например, операционная система Unix более надежна, чем Windows95. Или же ОС Unix более качественная сетевая ОС, чем WindowsNT. Слово "сетевая" здесь ключевое, без него утверждение было бы неверным. Для домашнего компьютера обычного пользователя Windows будет более качественной ОС, т.к. она в значительно большей степени удовлетворяет потребностям этого пользователя. Оценить количественно эти характеристики не представляется возможным. В руках профессионального системного администратора WindowsNT будет более надежной, чем Unix в руках чайника. Качественную оценку этих характеристик можно основывать на статистике использования программного продукта для решения определенных задач. На мой вопрос: "Как вы оцениваете надежность и качество ваших программ?", один руководитель софтверной компании ответил: "За нас это делают наши клиенты". Надежность и качество программного обеспечения зависит от жизненного цикла процесса разработки. Основываться можно только на практическом опыте. Насколько грамотная и как строго соблюдается технология создания программного обеспечения. Насколько профессиональна и опытна команда разработчиков. Какие инструментальные средства используются. Можно делать выводы на основании оценки количества выявленных ошибок при тестировании информационной системы. Оценка количества ошибок очень приблизительная, о ее точности довольно сложно судить. Некоторые делают оценку на основании интенсивности обнаружения ошибок. Некоторые искусственно закладывают в систему ошибки и смотрят, какой процент их будет выявлен при тестировании. Если заложили в систему 10 ошибок и после тестирования помимо всех прочих ошибок выявленно 7 из наших 10, то можно предположить, что в результате тестирования выявлены 70 процентов ошибок. Но все это достаточно условно. В параграфе тестирование мы рассматривали насколько разными могут быть ошибки. Каждая ошибка имеет свой вес и характер. Делать более или менее объективные выводы можно только после введения системы в эксплуатацию на основании отзывов клиентов. |
Невоспроизводимые ошибкиНевоспроизводимые ошибки представляют собой наиболее сложный тип ошибок. Например, 29 февраля ваша система вдруг начала давать сбои. ;-) Ну 29 февраля, конечно, воспроизводится. Но бывают ошибки, которые мистическим образом появляются и исчезают. В той же тестовой системе была непонятная ошибка, которая проявлялась один раз на несколько сот случаев. Непонятным образом некоторые студенты после сдачи теста получали не результаты, а сбой системы. На исправление этой ошибки ушло два рабочих дня. Оказалось, что проблема в скрипте на JavaScript, который отправлял данные HTML-формы на сервер после истечения допустимого времени ответа на вопрос. Проблема в том, что если время подходило к концу, и пользователь нажимал кнопку "Ответить", а в это же время уже начала работать функция JavaScript form.submit(), то отправка данных HTML-формы происходила дважды, т.е. скрипт проверки правильности ответа вызывался два раза. А это за собой тянуло ошибку во взаимосвязанных CGI-скриптах, и внешнее проявление сбоя системы мы наблюдали уже при подсчете результатов, а не непосредственно сразу после двойной отправки HTML-формы. Сам код JavaScript был написан верно, и с теоретической точки зрения даже если пользователь нажимает кнопку "Отправить" в последнюю секунду, HTML-форма должна была отправляться только один раз. Но на практике все оказалось совсем по-другому. На самом деле, ничего мистического нет, или, как говорится, чудес на свете не бывает. Просто невозможно воспроизвести условия, в которых наблюдалась невоспроизводимая ошибка. Надо искать в программе случайности: одновременный доступ к одному ресурсу, генератор случайных чисел, неинициализированные переменные, некорректная работа с памятью или преобразование типов, которые могут проявлять себя не каждый раз. НезначительнаяНапример, тип шрифта не тот. В заключении данного параграфа перечислим темы тестов: логика информационной системы интерфейс взаимосвязанная работа компонентов безопасность многопользовательский режим работы производительность переносимость |
Ошибки инструментария и других компонентов системыОшибки самого компилятора или интерпретатора. Очень редко, но и такое бывает. Например, лет пять назад мною была обнаружена следующая ошибка: // bug BC++3.1 & MSVC++4.2 print 0, it is wrong // watcom & others print 2, it is right #include<stdio.h> void main() { int x=10,y=8; x>y?x-=y:y-=x; printf("%d\n",x); } BorlandC3.1 и MSVisualC 4.2 выдавали ноль, а остальные компиляторы выдавали 2. Ниже идет пример еще одной, обнаруженной мной, ошибки для любителей C++ /* msvc++5.0 */ #include<new> struct A{ }; typedef A TYPE; typedef TYPE* pTYPE; void main() { pTYPE p = new TYPE; pTYPE* pp = (pTYPE*)new char[sizeof(pTYPE)]; new(pp) pTYPE(p); //pp->~pTYPE(); // pp[0].~pTYPE(); // don't work, why? pp[0].pTYPE::~pTYPE(); delete [] (char*)pp; delete p; } Ну и чтобы совсем уж быть полным, приведу недавно обнаруженную мной ошибку в СУБД MySQL. Ее обещали исправить только в четвертой версии. Ниже приведены два SQL-запроса из программы анализа посетителей веб-сайта. Первый работает нормально. Второй очень похож на первый и полностью удовлетворяет синтаксису SQL. Но второй запрос MySQL отказывается выполнять и возвращает пустую таблицу. SELECT COUNT(DISTINCT ip), COUNT(*), CONCAT(shref,href) FROM hit GROUP BY 3 SELECT COUNT(*), CONCAT(shref, href) FROM hit GROUP BY 2 После классификации ошибок давайте рассмотрим методы их поиска. В первую очередь, один простой и, казалось бы, очевидный совет: "надо думать, анализировать, почему программа не работает так, как было задумано, что надо в ней исправить". Никакой самый навороченный отладчик за вас ошибку не найдет. Никакая самая лучшая методика не найдет и не ускорит поиск ошибки, если вы не включите мозги по полной программе и не сосредоточитесь целиком и полностью на поимке ошибки. Итак, допустим вами, пользователем или тестирующим, было зафиксировано некорректное поведение программы. Что делать? Ниже перечислены методы в порядке их приоритетности, которые используют многие программисты. Ошибки логики взаимосвязанных CGI-программ Данного типа ошибки лежат во взаимосвязанных CGI-программах. Рассмотрим в качестве примера тестовую систему (см. сайт http://test.itsoft.ru). При сдаче теста в цикле работают два скрипта. Первый показывает вопрос, а второй проверяет правильность ответа. Если в тесте 10 вопросов, то эти CGI-скрипты вызываются парно в цикле десять раз. Но что будет, если пользователь нажмет кнопку "Обновить" в броузере? Скрипт, который показывает вопрос, вызовется повторно. Что будет при разрыве модемного соединения? Отладка в таких системах значительно сложнее, т.к. вам придется наблюдать за выполнением ряда взаимосвязанных скриптов. Ошибки многопользовательского доступаОшибки многопользовательских систем связаны с неправильным разграничением доступа к совместным ресурсам. Помимо файлов данных, записей в таблицах баз данных, общим ресурсов является генератор случайных чисел. На эти грабли нам пришлось наступить. Обязательно генерируйте случайные числа не только на основе времени, но и на основе уникального идентификатора процесса. В противном случае, при выполнении в один и тот же момент времени двух копий одной CGI-программы вы получите одинаковые результаты для двух пользователей. Ошибки многопользовательского доступа сложны тем, что могут не проявлять себя очень долго, до тех пор, пока в один и тот же момент времени системой ни будет запущено несколько копий одной CGI-программы. Ошибки синтаксиса языкаКак правило, в абсолютном большинстве случаев, ловятся на стадии компиляции программы, или же, если вы работаете с интерпретируемым языком типа Perl или PHP, то при первом интерпретировании программы. Но есть один существенный момент - это когда выражение допустимо, но зависит от конкретного компилятора или интерпретатора. Например, в языке Си вполне допустимыми по синтаксису, но не по смыслу, являются выражения: s[i++]=i; printf("%d %d", i++, i++);. Результат этих строк не определен, т.к. неизвестно, в каком порядке будет инкрементироваться и вычисляться значение переменной i. Переменная не может более одного раза присутствовать в выражении, если ее значение изменяется в ходе вычисления этого выражения. Ошибки во время выполнения К ошибкам во время выполнения программы относятся ошибки в логике и алгоритмах программы. Ошибки в логике программы связаны с неправильной записью алгоритма, например, вместо && вы написали или поставили точку с запятой там, где ее не должно быть. К этому же классу ошибок относится неправильное обращение с памятью. В языке Си неправильное обращение с памятью является наиболее распространенной ошибкой программистов, причем не только новичков, но и профессионалы нередко допускают ошибки подобного типа. Для языка Си - это один из самых больных вопросов и больших недостатков. Ошибки в алгоритме связаны с неправильным проектированием программы или же с изначально неправильно заложенной бизнес-логикой и функциональными требованиями. Пользователь ждет от программы то, что изначально от нее не требовалось. Ошибки во время выполнения - наиболее часто встречаемый тип ошибок и, как правило, устранение таких ошибок не представляется черес чур сложной задачей. Отключите ненужные модули программыЗакомментируйте все лишнее. Тем самым, вы упростите вашу программу. Имеет смысл комментировать отдельные куски программы до тех пор, пока ошибка не исчезнет. ОтладчикСамое последнее, к чему стоит прибегнуть, когда уже совсем ничего не остается, кроме как прозрачным взглядом наблюдать за трассировкой программы. Для CGI-программ применение отладчика не так просто, как для обычных программ. Для того чтобы применить отладчик, вам нужно задать необходимые переменные окружение, например, HTTP_REFERER или DOCUMENT_ROOT, а также вам необходимо передать CGI-параметры этому скрипту. Если вы используете библиотеку ITCGI, то она поддерживает режим отладки с командной строки. Применяйте все эти методы в комплексе для поиска ошибок. |
ОтладкаОтладка программы - это процесс, в ходе которого осуществляется устранение ошибок. Отладка порой занимает столько же времени, сколько программист затратил на написание исходного кода. Процесс отладки итерационный. Программист устраняет одну ошибку, а взамен может появиться две новых. По этому поводу Фредерик Брукс в своей классической книге "Мифический человеко-месяц или Как проектируются и создаются программные комплексы" пишет, что иной раз, обнаружив в программе ошибку и научившись ее обходить, лучше все оставить как есть и ничего не исправлять. Такой подход возможно и справедлив в системах, пользователями которых являются люди с предсказуемым поведением. В нашем случае, нет никакой возможности научить пользователя обходить ошибки в CGI-программах. Первое, с чего мы начнем, так это с классификации ошибок: Отладочные печатиРаспечатывайте значения переменных в узловых точках программы. В CGI-программах при непосредственной отладке можно выводить информацию в стандартный поток вывода - stdout, функция printf(const char *format [, argument ]...); Вы будете видеть значения переменных в броузере. Но такой способ не всегда годится, например, если система уже введена в эксплуатацию или же у вас невоспроизводимая ошибка. В этом случае воспользуйтесь выводом в стандартный поток ошибок - stderr, функция fprintf(stderr, const char *format [, argument ]...);. При выводе информации в стандартный поток ошибок она будет записываться в log-файл ошибок вашего веб-сайта. ПереносимостьКак известно абсолютно переносимой программой является "Hello, World!". Любые другие программы имеют какую-либо зависимость от внешней среды. Рассмотрение вопроса переносимости мы начнем с ответа на вопрос: "Зачем?". Казалось бы, сделали, работает и ладно. Но вдруг нам понадобилось открыть зеркало сайта на другом континенте, а там другая версия Unix. Хуже того, у вас система работала на FreeBSD, а там Linux. А бывает так, что возникает необходимость интегрировать систему, написанную под Unix, c офисной базой данных на MS Access. Еще один важный аспект, который является следствием переносимого кода - повышенная надежность программы. При переносе программы на другую платформу выявляются дополнительные ошибки, которые не были обнаружены ранее. Важно отметить, что и внешняя среда, даже на одной и той же платформе, меняется со временем, поэтому нежелательно каким-либо образом привязываться к текущей версии операционной системы, СУБД или какого-либо еще внешнего программного продукта. Переносимость также играет очень существенную роль для серийных программных продуктов, например, наша библиотека ITCGI. Если бы она была не переносима, то распространение и развитие ее было бы сильно осложнено. Рассмотрев причины, по которым программы должны обладать как можно лучшей переносимостью, давайте рассмотрим методы, которые помогут достичь этой самой переносимости. Конечно, такие языки, как Perl и PHP, сами по себе обладают, практически, стопроцентной переносимостью. Хотя это не совсем так. Сам язык Perl переносим, но вот библиотеки функций не все. Это, впрочем, вполне естественно. Если библиотека работает под Unix, то совершенно необязательно, что она также должна работать и под Windows. Поскольку главный упор в книге сделан на язык Си, то мы будем рассматривать именно этот язык программирования. Стандарт языка Си говорит, что программа может быть как переносимой, так и не переносимой в случае, если она использует системные функции операционной системы. Подавляющее большинство CGI-программ от операционной системы не зависят. Куда больше они зависят от СУБД и веб-сервера. Но перенос с одной СУБД на другую - это отдельный вопрос. От веб-сервера зависят переменные окружения CGI-программ. Так, например, в Windows в Internet Information Server путь на диске к директории, где лежит веб-сайт, определяется переменной окружения PATH_TRANSLATED, а для веб-сервера Apache это значение содержится в переменной окружения DOCUMENT_ROOT. Специально для этих целей в ITCGI включили следующую функцию. char* GetWebServerRoot() { if(getenv("PATH_TRANSLATED")!=NULL) return getenv("PATH_TRANSLATED"); else if(getenv("DOCUMENT_ROOT")!=NULL) return getenv("DOCUMENT_ROOT"); else return NULL; } При разработке CGI-программ и переносе их из Unix в Windows и обратно нам приходилось сталкиваться с различным названием даже стандартных функций. Например, snprintf в Windows в среде Visual C надо писать со знаком подчеркивания. Но это, вероятно, связано с тем, что под Windows мы использовали также MFC, и там компилятор С++. Это уже к вопросу переносимости кода с Си на С++. Иногда функции есть в стандартной библиотеке одной системы, но их нет в другой. Например, библиотека stdarg.h имеет различия в реализации под Unix и Windows, вследствие чего пришлось писать следующий код для функции LString_Format: void LString_Format(LString* p, const char* fmt, ...) //////////////////// { #ifdef __AFX_H__ CString inside; va_list argList; va_start(argList, fmt); inside.FormatV(fmt, argList); va_end(argList); LString_SetString(p,inside); #else va_list ap; char * inside; va_start(ap,fmt); vasprintf(&inside,fmt,ap); LString_SetString(p,inside); free(inside); va_end(ap); #endif } Особо хочется отметить работу с текстовыми файлами. Проблема в том, что в Windows в текстовом файле строка заканчивается двумя символами: '\r' - возврат каретки и '\n' - перевод строки. В Unix строка заканчивается одним символом '\n'. На эти грабли мы наступали и будем наступать. Проблема в том, что если вы на вход откомпилированной программы под Windows подадите файл из системы Unix, то программа может завершиться некорректно. Хотя вы пользуетесь системными функциями. Большой интерес представляет старение техники и программного обеспечения. Такая проблема актуальна для любого программного обеспечения. Но для информационных систем она куда более актуальна, чем для операционных систем или клиентских программ. Основная проблема заключается в отсутствии финансирования. Клиентские небольшие программы, типа "The Bat", и операционные системы продаются миллионными тиражами. Каждый день дорабатываются с учетом новых потребностей пользователей, т.е. они идут в ногу со временем. Информационные системы зачастую делаются в одном единственном экземпляре для потребностей одной компании. И здесь, полный застой после сдачи в эксплуатацию. Для веб-сайтов это абсолютно верное утверждение. Только очень крупные компании, бизнес которых связан непосредственно с информационными системами в Интеренет, могут позволить себе держать команду разработчиков, которая будет постоянно развивать свои решения. Такого рода компании делают деньги на рекламе на порталах, поисковых серверах, серверах по учету посетителей сайтов. Итак, резюмируя вышесказанное, планируйте хранение данных на долгосрочную перспективу. Через несколько лет, скорее всего, придется разрабатывать новую структуру для базы данных и новые CGI-скрипты. Не используйте ненадежные технологии. Сколько нововведений появлялось и стремительно исчезало через 1-2 года. Одна из самых известных технологий, на которую просто был бум в середине 90х, это технология разработки платформенно-независимых программ Java. Совсем недавно корпорация Microsoft объявила о том, что прекращает поддерживать эту технологию. Вспомните самый популярный броузер середины 90х - Netscape. Вспомните Netscape Communications Corporation, которая сделала этот броузер. Корпорация Netscape Communications ввела немало новых технологий. Какие-то из них прижились, какие-то нет. Например JavaScript живет, а вот фреймы и DHTML почти нет. Сам броузер Netscape приказал долго жить, на сегодняшний день им пользуются около 1% пользователей. Если еще полгода назад мы с большим вниманием относились к тому, что сайт должен практически одинаково выглядеть во всех броузерах, т.е. мы проверяли не только в MS Explorer, но и в Netscape, и в Oper'e, то сейчас обращать внимание на Netscape - это тоже самое, что делать сайт для людей с текстовыми броузерами. Причина не в том, что мы такие нехорошие, а в том, что это самым обыкновенным образом экономически нецелесообразно. Определенное количество человекочасов затратить необходимо, а заказчик не готов их оплачивать. |
Пишите историю модификации исходного кодаВ самом начале файла ставьте дату и пишите, что было сделано и почему. Далее идут рекомендации общего характера применительно к разработке CGI-программ. Повторное использование уже написанного ранее кода у вас будет значительно выше, чем в других проектах. Во многом это определяется вышерассмотренным правилом: "на каждую HTML-форму свой CGI-скрипт". Общие функции для нескольких CGI-программ выносите в отдельную библиотеку инструментов, именно так, у нас появилась библиотека ITCGI. CGI-программа должна быть максимально независима от дизайна и HTML-кода. Например, нижние и верхние колонтитулы мы считываем из файлов /include/head.inc и /include/footer.inc. Если CGI-программа должна выдавать данные, оформленные в определенном дизайне, то HTML-код лучше вынести в отдельный файл, а места, куда надо вставить данные, пометить, как ##имя_переменной##. В CGI-программе надо будет считать этот файл и выполнить соответствующую замену. В таком подходе есть недостаток, т.к. это несколько замедляет работу. При каждом вызове CGI-программы она должна считывать внешний файл и делать в нем замену. Но в таком подходе есть и свои плюсы, т.к. верстальщик, без непосредственного взаимодействия с программистом, может настраивать вывод CGI-скрипта. Еще очень важным моментом при разработке CGI-программ является хранение параметров в файле на сервере. Имеет смысл хранить параметры в файле с расширением .cfg, только в Apache обязательно запретите чтение этих файлов внешними пользователями. Это делается следующими строчками в файле httpd.conf: <Files ~ "*.cfg"> Order allow,deny Deny from all </Files> В библиотеке ITCGI есть ряд функций для работы с параметрами на стороне сервера. |
ПредложениеТестер вносит предложение по усовершенствованию информационной системы. Проектирование информационных системНачнем с рассмотрения общей архитектуры. Для начала, давайте выделим характерные особенности информационных систем подобного рода, функционирующих в сети Интернет на веб-сайтах, т.к. задача проектирования базируется на характеристиках той или иной системы и предъявляемых функциональных требованиях. Итак: вся информация и все вычисления хранятся и выполняются на сервере у каждого клиента свой броузер многопользовательский доступ разграничение доступа ограничения по объему передаваемой информации повышенные требования к безопасности повышенные требования к производительности переносимость Рассмотрим по порядку эти характеристики. На переднем плане первые два пункта. Они представляют собой наиболее важное отличие от информационных систем, функционирующих в закрытых сетях. Мы не имеем возможности хранить и обрабатывать какую-либо информацию на стороне клиента. Все должно выполнятся на сервере. При разработке информационной системы с клиентским программным обеспечением можно было бы хранить часть пользовательской информации и обрабатывать ее на стороне клиента. Такая возможность позволила бы нам разгрузить сервер и трафик сети. Например, в случае анализа посетителей веб-сайтов, мы хранили бы основные объемы информации у клиентов, а на сервере - лишь общедоступные статистические отчеты, выжимки и сравнительные показатели с другими клиентами. Но мы не имеем такой возможности, поэтому надо тратить большие деньги на накопители жестких дисков и вычислительные мощности серверов. Многопользовательский доступ и разграничение доступа являются общими требованиями для всех информационных систем. Важным критерием является ограничение по объему передаваемой информации. На сервере может быть канал с большой пропускной способность, но по этому каналу идет информация от множества клиентов. В свою очередь, у пользователя информация идет только для него, но очень часто пользователи сидят на плохих каналах, например, на модемном соединении, или же просто, в силу удаленности и большого количества шлюзов между клиентом и сервером, скорость передачи информации очень медленная. В связи с тем, что в сети Интернет находится огромное количество людей, среди которых есть и злоумышленники, то необходимо предъявлять повышенные требования к безопасности. Вы не можете написать инструкцию пользователю: делай так, а не иначе, а вот здесь у нас дырка, чтобы ее обойти, делайте так-то. Вы не знаете, чего ожидать от пользователя. В связи с тем, что на сервере происходят все вычисления, и что пользователь хочет работать в режиме реального времени и не намерен ждать и 30 секунд, выполнение отдельно взятой CGI-программы должно происходить максимально быстро. И наконец, переносимость. Конечно, эта особенность не столь важна, но допустим, вам потребовалось открыть зеркало сайта на другом континенте. Принципиально надо решить две проблемы. Во-первых, настройка серверной платформы и вашего программного обеспечения для функционирования вашей информационной системы. Во-вторых, перевод системы на другой язык. На другом континенте может просто не оказаться ни требуемой вашей информационной системой платформы, ни специалистов, которые бы могли все это установить, настроить и поддерживать. Например, будет другая разновидность Unix. Все эти характерные особенности, в основном, и определяют стадию проектирования. В процессе проектирования информационной системы можно выделить три основных этапа: проектирование пользовательского интерфейса; проектирование базы данных; проектирование связующей системы CGI-программ. На первом этапе проектирования необходимо выяснить требования пользователей к системе и, на основании этих требований, сделать макет сайта, показывающего все HTML-формы и HTML-файлы отчетов взаимодействия с информационной системой. Желательно, чтобы HTML-формы содержали некоторые данные по умолчанию и ссылались на HTML-документы, которые, предполагается, будут результатом выполнения запроса к системе. В этом случае, пользователям будет легче понять, что же вы спроектировали. Наиболее правильным решением является однозначная связь между функциональным требованием и CGI-программой. Одна функция (операция) - одна CGI-программа. В этом случае, исходный код будет простым и небольшим, а следовательно, значительно снижается вероятность пропустить в нем дыру в безопасности. Загрузка и выполнение такой программы будет происходить значительно быстрее. И самое главное, модифицировать и поддерживать такую программу будет значительно легче. Помимо того, чтобы расписать, какая программа какую функцию выполняет, вам необходимо установить взаимосвязи между ними. Это такая паутинная схема. В простых системах она простая, в больших ее сложность возрастает нелинейно. Конечно, можно расставлять связи по месту. В простых системах вообще ничего не рисуют, т.к. и так все очевидно. Но вот в больших системах, особенно, если вы работаете в команде из нескольких человек, полезно иметь визуальное представление, откуда и какой CGI-скрипт вызывается, и куда вы попадете после его выполнения. Принципиально, как мы уже рассматривали в главе "CGI-программирвание", CGI-программа может выдавать либо текст, либо перенаправлять на другой адрес в Интернет, либо же выдавать картинку или еще какой файл. Вот такого рода схемку, набросанную от руки, полезно иметь, чтобы ясно представлять себе архитектуру проекта. |
ПрограммированиеНачать этот параграф хочется с давно избитых правил. В настоящее время программистом кого только ни называют, и кто только себя ни называет. Можно даже встретить высказывания, что оформление текста в HTML - есть программирование. Давно избитые правила относятся к тем, кто пишет программы, в которых никто, кроме них самих, а часто и они, сами после некоторого периода времени, разобраться не могут. Код программы должен быть написан так, чтобы любой другой программист с минимальными затратами времени и энергии мог его прочитать и разобраться, как он работает, и как его модифицировать. Итак, вот список основных правил: ПроизводительностьОчень важным фактором является производительность системы. Подробно важность производительности мы рассмотрели выше, в параграфе "Проектирование информационных систем". Здесь мы не будем повторяться и перейдем сразу к методам, которые позволяют увеличить производительность системы. Первое и самое главное, что необходимо уяснить, что динамически должны формироваться только те страницы сайта, содержание которых зависит от параметров, введенных конкретным пользователем! Приведем пример. Допустим, на главной странице сайта показываются новости. Для того чтобы автоматизировать работу по поддержке сайта, вы разработали несколько CGI-программ, которые взаимодействуют с базой данных, где вы храните свои новости. Решение абсолютно правильное, так и надо делать. База данных позволит хранить архив новостей, выполнять по ним поиск, сортировку по различным критериям. Но есть одна очень распространенная ошибка. Часто на главную страницу ставят скрипт, который выдает последние 10 или 20 новостей. И этот скрипт выдает эти новости каждому пользователю. К вам зашло 1000 посетителей, и скрипт сработал 1000 раз, и 1000 раз выполнил одну и ту же работу. Это принципиальная ошибка. Необходимо просто перегенерировать содержание главной страницы один раз при модификации записей в базе данных. Конечно, пример с новостями может и не очень удачный, т.к. тут не стоит так остро вопрос с производительностью. Но в большинстве других, более сложных систем, этот вопрос стоит очень остро. Такой метод называется кэшированием. Например, на сайте http://inforg.ru без кэширования пользователю в разделе "Пошаговый поиск" пришлось бы ждать несколько минут, пока обработались бы данные. Но поскольку содержимое страниц от пользователя не зависит, то там один раз в сутки глубокой ночью запускается программа, которая перегенерирует страницы сайта на основе базы данных. В портале INFORG собрана информация по десяткам, а может быть, уже сотням тысяч организаций. Естественно, имеется возможность производить поиск на основе запроса пользователя, но тут уже ничего не поделаешь, и самое главное, пользователь готов ждать, пока его запрос будет обработан. Важно также особо отметить, что часто разработчики забывают создавать индексы в базе данных. На стадии разработки данных мало, и все работает быстро, а после введения в эксплуатацию количество данных начинает быстро расти, и тут выползают все проблемы. Очень важно рассмотреть методы тестирования производительности. Во-первых, необходимо наполнить систему данными. Во-вторых, тестирование необходимо проводить в многопользовательском режиме, т.е. чтобы одновременно с ней работало человек десять. Вам необходимо посмотреть производительность операционной системы, СУБД и отдельных CGI-программ. В Unix это можно сделать с помощью утилиты top. СУБД MySQL имеет свои утилиты по мониторингу производительности и состоянию системы. В CGI-скриптах имеет смысл производить оценку времени выполнения отдельных блоков. Делается это при помощи функций из библиотеки time.h. Если у вас загружена операционная система или СУБД, трясите системного администратора, покупайте более мощный сервер. Впрочем, загруженность СУБД, в большинстве случаев, будет означать неправильные структуры данных и плохо спроектированные SQL-запросы. Прежде, чем бежать в магазин за новым системным блоком, лучше хорошенько подумайте. Если вы все установите на более производительную технику, а оно все равно будет работать медленно, вам придется взяться за голову. В операционной системе надо поискать процессы, которые пожирают ресурсы. В СУБД ищите поля, которые участвуют в условиях отбора, но по ним не стоит индексирование. Также в СУБД ищите кривые SQL-запросы. Например, если у вас запрос SELECT выполняет выборку данных из более, чем одной таблицы, то это наиболее вероятная проблема слабой производительности. Старайтесь не допускать выборки из более, чем трех таблиц. Несколько запросов, выполненных подряд по выборке данных из двух таблиц, выполнятся быстрее, чем один из запрос из нескольких таблиц. Если же проблема в вашем CGI-скрипте, то просмотрите все циклы и алгоритмы. Оптимизация, как правило, не дает никаких результатов. Не надо перебирать всевозможные опции компилятора, они дадут вам ускорение на несколько процентов. Меняйте алгоритмы. Избавляйтесь от лишних циклов, выносите за скобки цикла медленные операции, кэшируйте результаты. |
Разработка информационных системГостевые книги, форумы, интернет-магазины, поисковые машины и другие интерактивные сайты являются информационными системами. В подавляющем большинстве проектов по разработке веб-сайтов работает один веб-программист. В первую очередь, это связано с очень маленьким бюджетом проекта и недостатком финансирования. Рассматривать здесь, в теории, как должно было бы быть, мы не будем. Если вы работаете над проектом в команде профессионалов из более чем 10 человек, то скорее всего, вы и так все знаете, в крайнем случае просто обязан все знать руководитель проекта. Вряд ли что-то новое вы узнаете из данной книги. В общем, закройте эту книгу, т.к. здесь рассмотрения проектов с бюджетом в несколько десятков тысяч долларов нет. Итак, переходим к малобюджетным проектам и их реализации в условиях ограниченных ресурсов. В связи с вышесказанным, в таком проекте веб-программисту приходится выполнять проектирование, программирование, отладку, тестирование и документирование создаваемой им информационной системы. |
СерьезнаяОшибка, которая доставляет неудобства и осложняет работу пользователя. Например, сортировка записей осуществляется не в том порядке. Стремитесь к простотеНе стоит писать на птичьем языке типа *p[i++] = ++n; или f1() && f2(); или for(i=0,p=5,&s=*p;exp1()&&exp2&&exp3()exp4();i++,p++); Многие не помнят, в каком порядке происходят вычисления инкремента и не догадываются, что вы хотели вызвать функцию f2, если f1 вернула не ноль. Не заставляйте программиста, читающего вашу программу думать. Разбивайте сложные конструкции на несколько строк, расставляйте скобки. ТестированиеЦелью процесса тестирования является выявление ошибок в программе. Чем больше ошибок нашли, тем лучше. О том, как интерпретировать количество ошибок, будет рассказано в параграфе "Надежность и качество". Мы будем различать три этапа тестирования на стадии проектирования, реализации и тестирование законченного продукта. Неплохо также тестировать сам процесс тестирования, но эта тема уже выходит за рамки данной книги. Тестирование ни в коем случае не стоит делать непосредственному испольнителю, т.к. у него уже замыленный взгляд. Он знает, как спроектирована или работает программа, что ей подавать на вход. Человек так устроен, что всегда идет не самым простым и правильным путем, а тем, которым у него уже получалось дойти до цели. Другими словами, проектировщик или программист уже интуитивно представляет пути, по которым надо идти, чтобы получить результат. И он не знает и не представляет еще 1001 способ, которым можно воспользоваться программой. Надо правильно понимать, что процесс тестирования не ставит своей задачей доказать правильность работы программы или информационной системы. Это просто невозможно сделать, т.к. невозможно протестировать абсолютно все варианты работы и использования программы. Однако, можно говорить, что были пройдены такие-то тесты и программа работоспособна. Результаты тестирования необходимо документировать и подшивать в отчет. В ходе тестирования тестерам должны быть доступны исходные коды программ. Но не путайте процесс тестирования с отладкой. Задачей тестера является зафиксировать ошибку и, по возможности, указать, как ее можно воспроизвести. Исправлять и отлаживать программу должен программист. Поскольку, как уже было сказано, протестировать все возможные случаи работы программы нельзя, то необходимо протестировать ее работу в характерных точках. Прежде, чем приступать к поиску ошибок необходимо определить, что такое ошибка и как ее идентифицировать. Для того чтобы можно было со стопроцентной уверенностью утверждать об обнаружение ошибки нужно иметь эталон, с которым можно было бы сравнивать объект тестирования.
то непонятно, он не можетТестеру что- то непонятно, он не может точно сказать столкнулся ли он с ошибкой или особенностью программы. Каждуй ошибку различают по степени важности: Зовите на помощь коллегИной раз достаточно просто позвать на помощь своего коллегу со свежей головой и с незамыленным взглядом, начать объяснять ему, как тут у вас все устроено и работает, и тут вы возьметесь за голову со словами: "Семен Семеныч" (с) к\ф Бриллиантовая рука. Если такого не произойдет, то вдвоем, задавая друг другу вопросы, вы быстро найдете ошибку. Мы применяем этот способ в самых безнадежных случаях, и он, действительно, почти всегда приводит к положительному результату. Да, самое главное, после поиска ошибки обязательно угостите своего коллегу пивом, фантой или еще чем-нибудь, иначе в следующий раз он вряд ли придет к вам на помощь с особым энтузиазмом. /Cgi-bin/Директория с исполняемыми файлами, должна быть закрыта на чтение. Фиксированный или масштабируемый веб-сайт?Сначала поясним, что есть что и какие есть плюсы, минусы и те или иные отличительные черты фиксированного и масштабируемого сайта. Фиксированный сайт имеем определенную, явно или неявно, ширину и просматривается одинаково независимо от размеров окна броузера. Явно его размер может задаваться шириной общей таблицы HTML-документа, а неявно размером наибольшего элемента HTML-документа. Масштабируемый сайт имеет минимальную ширину, меньше которой он не сжимается, а при ширине окна броузера больше, чем его минимальная ширина, подстраивается под размеры окна броузера. Какой вариант лучше сказать нельзя, у каждого есть свои сильные и слабые стороны. Фиксированный сайт хорош тем, что веб-мастер видит сайт точно также, как его увидят и другие пользователи, имеется в виду расположение текста, картинок и других элементов относительно друг друга, см. пример . Но при этом, если у пользователя окно броузера немного меньше размеров сайта, то появляется линейка прокрутки по горизонтали, что заставляет пользователя постоянно ее таскать влево-вправо, чтобы прочитать содержимое сайта. Очень узкие или очень широкие размеры окна броузера по горизонтали страшны для обоих типов сайтов, т.к. при очень узком окне у обоих сайтов появится горизонтальная линейка прокрутки, а при широком окне, что возможно только на мониторах с очень высоким разрешением, фиксированный сайт вытянется в сосиску по вертикали, а масштабируемый в сардельку по горизонтали. В следствии вышесказанного, экстремальные случаи не рассматриваются и это уже проблема пользователя, в окне какого размера ему смотреть сайт. При небольших же отклонениях\колебаниях размеров ширины окна броузера, на мой взгляд, все лучше масштабируемый сайт, который будет подстраиваться под размеры окна броузера. В качестве примера см. сайт http://itsoft.ru. Заранее рассчитывать на какой-то размер очень сложно, т.к. неизвестно ни разрешение экрана пользователя, ни количество и размер всевозможных панелей офиса и\или ICQ и прочих утилит. На сегодняшний день надо ориентироваться на диапазон от 700 до 1024 пикселей.
<table cellspacing=0 ><tr><td bgcolor=green><img src="0.gif" width=120 height=1></td ><td width=100% bgcolor=blue>Здесь текст</td ><td bgcolor=#C2C2C2><img src="0.gif" width=120 height=1></td ></tr></table> Необходимо отметить, что даже фиксированные сайты по ширине в зависимости от размера шрифта пользователя могут менять свой размер. |

/Include/footer.incНижний колонтитул. Файл с функциями JavaScript здесь не описан, т.к. JavaScript применяется не очень часто, и набора общих функций для всего сайта может не существовать. |
Общие требования к веб-сайту.Теперь рассмотрим требования предъявляемые к веб-сайту. Постараемся перечислить их в порядке значимости. Совместимость с основными версиями броузеров. Минимальный объем HTML-кода. Модификация сайта при минимуме человекочасов. Портабельность сайта. Теперь поясним каждый пункт в отдельности. Безусловно, самым важным является совместимость HTML-кода страниц вашего сайта с основными броузерами. На сегодняшний день основными являются: Internet Explorer 4.x, 5.x, Netscape Navigator 4.x, 6.x, Opera 4.x, 5.x., также рекомендую просматривать ваши страницы в третьих версиях броузеров. В них, скорее всего, ваш сайт будет отображаться не совсем корректно, т.к. третьи версии не поддерживают многих элементов, например, каскакадных таблиц стилей. Но если ваша страница отображается совсем неправильно, то скорее всего вы что-то не так сверстали. Иногда, для сайта очень важно, чтобы он приемлемо отображался не только в четвертых, но и в третьих версиях броузеров. Например, сайт компании Философт - http://www.philosoft.ru, которая занимается техническими переводами. Если кто-то из потенциальных клиентов не сможет ознакомиться с предлагаемыми услугами, то, понятное дело, реальным клиентом он вряд ли станет. Если сайт не просматривается или отображается некорректно в четвертых версиях броузеров, то теряется значительная часть посетителей. Объем HTML-кода должен стремиться к минимуму по двум причинам. Первая, и самая главная, вызвана скоростью загрузки вашего HTML-документа пользователем. Пользователь не будет долго ждать. Если страница не появилась в течение одной минуты, то скорее всего, пользователь уйдет на другой веб-сайт. Вторая причина связана с совместимостью с основными версиями броузеров и дальнейшим сопровождением сайта. Практика показывает, что чем больше объем HTML-кода, тем сложнее добиться, чтобы он одинаково отображался в различных броузерах. Здесь имеется в виду не абсолютный размер HTML-кода. Дело в том, что одного и того же результата можно добиться разными способами.
Вариант 2. <table> <tr><td rowspan=2>Ячейка 1 <td>Ячейка 2 <tr><td>Ячейка 3 </table> Более правильным, с практической точки зрения совместимости с различными броузерами, является второй вариант HTML-кода. Старайтесь избегать использования лишних команд, и особенно, вложенных таблиц. Ни в коем случае нельзя допускать пробелы между HTML-командами, т.к. они часто приводят к разрывам на страницах. В первую очередь это относится к верстке с использованием таблиц и картинок. В этих случаях наиболее часто проявляются подобного рода дефекты. Ниже идет пример правильного оформленного HTML-кода взятого с сайта . Здесь пришлось внести много переносов на новую строку из-за ограничения по ширине страницы. Тем не менее, обратите внимание на символы ><, т.е. пробелы между HTML-командами исключены. <table width=100% cellspacing=0 cellpadding=0 ><tr><td width=120><a href=/><img src=/logo.gif width=120 height=60 border=0 alt="На главную страницу"></a></td ><td width=147><img src=/head/<!--#echo var="QUERY_STRING"-->.gif width=147 height=60></td ><td width=100% background=/headvline.gif><img src=/0.gif width=1 height=1></td ><td width=468 bgcolor=#CCCCCC><img src=/itsoft.gif width=468 height=60></td ></tr></table><table width=100% cellspacing=0 cellpadding=0 ><tr><td width=104><a href=/><img src=/inforgru.gif width=104 height=20 border=0 alt="На главную страницу"></a></td ><td width=100% background=/headvline2.gif><img src=/0.gif width=1 height=1></td ><td width=632><img src=/m1.gif width=19 height=20><a href=/main.html?<!--#echo var="QUERY_STRING"-->><img src=/mmain.gif border=0 width=67 height=20></a><img src=/msep.gif width=11 height=20><a href=/cgi-bin/find.pl?<!--#echo var="QUERY_STRING"-->><img src=/mbd.gif border=0 width=105 height=20></a><img src=/msep.gif width=11 height=20><a и т.д. В дальнейшем, после завершения работ над сайтом, его придется поддерживать, т.е. дополнять и изменять. Для быстрой и успешной модификации сайта необходимо, чтобы: Сайт имел структуру, пример предлагаемой структуры сайта см. выше. Исходный HTML-код должен быть читабельным. Верхние и нижние колонтитулы были вынесены в отдельный файл. CSS (таблицы каскадных стилей), используемые в нескольких документах находились в отдельном файле. Функции JavaScript, используемые в нескольких документах находились в отдельном файле. Гиперсылки имели правильные пути - абсолютные и относительные. В именах файлов и адресах гиперссылок использовались только цифры и буквы английского алфавита нижнего регистра, также допускается использование символа подчеркивания. Все остальные символы русского алфавита, английские символы верхнего регистра значительно могут осложнить поддержку веб-сайта. При соблюдении вышеуказанных требований модификация сайта и портабельность сайта будут осуществляться с минимальными затратами. Об использование стилей, JavaScript, новых технологиях и прочих извращенных фантазиях. Интерфейс веб-сайта - это средство навигации и доступа к информации. Исходя из этого определения, применяйте только те технологии и те средства тех или иных технологий, которые вам действительно необходимы. Например, в языке гипертекстовой разметки HTML достаточно большое количество команд, однако реально на практике мы применяем лишь меньшую половину из них, в остальных просто нет надобности. Совсем не стоит применять самые последние технологии, которые могут не поддерживаться какими-либо броузерами. Главная задача - дать пользователям удобно работать с информацией на вашем сайте, а не затруднить к ней доступ. Например, стили позволяют очень большой спектр возможностей для веб-мастера, однако, если правильно сделать файлы верхнего и нижнего заголовков HTML-документа - /include/head.inc и /include/footer.inc, то во многих случаях можно обойтись без стилей Все случаи оправданного JavaScript описаны в пятой главе. Если я что-то забыл, то обязательно пришлите мне свой пример использования JavaScript по делу. |
Определения.В данной главе рассматриваются проблемы и особенности верстки отдельных HTML-документов и веб-сайта в целом. Начнем с некоторых определений, чтобы работать в одной системе координат. Шрифты и цветВопрос шрифтов и цветовой гаммы является одним из самых важных и значимых при разработке веб-сайтов. Хотя это предельно простые вещи, однако, чуть ли не на каждом втором веб-сайте используются нездоровые сочетания цветов, реже используются нечитаемые шрифты. Использование нестандартных шрифтов крайне нежелательно. Наиболее подходящим и распространенным шрифтом для веб-страниц является Arial. Ни в коем случае не фиксируйте размер шрифта средствами CSS. В броузере Netscape можно намертво зафиксировать размер шрифта. В настройках броузера мне не удалось найти опцию, указывающую броузеру не учитывать размер шрифта. Но если шрифт не зафиксирован, то Неткейп позволяет его увеличивать и уменьшать почти до любых размеров. В этом отношении Netscape ведет себя гораздо правильнее. Он увеличивает размер шрифта до любого необходимого, т.е. до тех пор, пока пользователю не станет удобно. В MS Internet Explorer по умолчанию размер шрифта не изменяется, если в файле стилей веб-сайта он зафиксирован. Для того чтобы игнорировать фиксированные шрифты и иметь возможность их увеличивать или уменьшать зайдите в меню Сервис->Свойства обозревателя->Офрмление и поставте галочку "Не учитывать размеры шрифтов, указанные на веб-страницах".  MS Internet Explorer имеет только пять градаций на размер шрифта, а фактически только две. По умолчанию, стоит средний. И для того чтобы увеличить шрифт, вы можете выбрать либо "Крупный", либо "Самый крупный". Но иногда, даже самый крупный не спасает. У меня монитор находится на расстоянии 70-80 сантиметров от глаз. Ходить по интернету я люблю, откинувшись в кресле. Сайты, которые имеют зафиксированный или уменьшенный шрифт, меня напрягают и мне не нравятся. А есть еще люди с расстройством зрения, о них тоже необходимо думать. Есть мониторы с высоким разрешением экрана 1600х1200. Но почему-то до сих пор встречается очень много сайтов, которые фиксируют маленький шрифт. Мотивация людей, которые фиксируют размер шрифта не поддается здравой логике. Они решают за пользователя, что хорошо, а что плохо. Всегда тестируйте сайт на различных разрешениях экрана и размерах шрифтов. В свете рассмотренной выше проблемы, необходимо рассмотреть графические меню. Меню сделанное в графике имеет один плюс - одинаково выглядит во всех броузерах и иногда выглядит красивее. Слово иногда специально выделенно жирным, т.к. очень часто встречаются такие графические меню, что непонятно зачем человек напрягался, когда оно выглядит значительно хуже текстового. Ну, а красота так вообще понятие субъективное. Меню сделанное в графике имеет также один минус - оно не масштабируется. И на экране 640х480 и на 1600х1200 оно будет состоять из одинакового количества пикселов, а фактические видимые размеры будут разными. У пользователя с разрешением 640х480 меню может не поместиться на экране. Напротив, пользователь с разрешением 1600х1200 вынужден будет бежать за лупой или уменьшать разрешение экрана. Текстовое меню пользователь может уменьшить и увеличить. Теперь давайте рассмотрим вопрос с цветами. Каких только серобурмалиновых цветов сейчас не насмотришься в Интернет, чем думали дизайнеры или веб-мастера непонятно. Возможно, они зачастую хотят продемонстрировать миру или своему начальнику познания в области HTML, при этом, им совершенно нет дела до пользователей, которым приходится читать зеленый текст на черном фоне. Мне даже как-то попался желтый текст на белом фоне. ;-)) Единственным приемлемым сочетанием для текстовых блоков является черное на белом! Все остальное есть плод больной фантазии. Другие сочетания можно допускать только в заголовках или названиях меню. В этом случае, другие сочетания будут оправданы, т.к. они служат для выделения заголовка или меню. Недавно мне на глаза попался журнал "Хакер", как его люди читают мне просто непонятно, белый текст на черном, зеленом или каком-либо другом фоне. Если вы решили использовать нестандартное сочетание цветов, то обратитесь к следующему рисунку, чтобы подобрать цвета текста и фона, которые не вызовут больших затруднений у пользователя. |
Информационное наполнениеЦелью хорошего информационного наполнения сайта является получение пользователем информации. Информационное наполнение и оформление текстов сайтов страдает в большинстве случаев. Надо четко понимать, что информация на сайте и информация в книге, журнале или газете отличаются не только по оформлению, но и по содержанию. Текст с монитора читается хуже, чем с бумаги, поэтому на сайте текст должен быть более лаконичным. Рассчитывайте на беглый просмотр, вряд ли кто-то будет детально вчитываться. Используйте представление текста в виде списков и таблиц. Списки значительно легче воспринимаются, чем обычный повествовательный текст. Старайтесь, чтобы прокрутка документа по вертикали не занимала более трех экранов. Дробите большие документы на более мелкие. Разбавьте текст картинками, только не переборщите, а то загрузка страницы будет происходить очень долго. Не злоупотребляйте нестандартными шрифтами и сочетаниями цветов. Очень распространенная ошибка - фоновый рисунок. Ни в коем случае не используйте эту глупость! Текст на фоне картинки читается очень медленно. Очень важным элементом текста являются гиперссылки. Старайтесь ими не злоупотреблять. Если у вас через слово гиперссылка, то это уже не текст для чтения, а навигационное меню. Если вы ставите гиперссылку в тексте, то выделяйте ее. Стандартным выделением гиперссылки в тексте является подчеркивание. Выделение цветом менее заметно. Ни в коем случае в HTML-документах не используйте слова с подчеркиванием. Интуитивно у пользователей уже срабатывает рефлекс, что подчеркнутое слово - это гиперссылка. Пользователь будет в недоумении щелкать на это слово, но ничего происходить не будет. Гиперссылки лучше открывать в том же окне или в окне без панели инструментов и статусной строки, если это своего рода сноска. В первом случае, посетителю придется возвращаться назад при помощи кнопки "Назад", а во втором - закрыть окно. Здесь же необходимо отметить еще один тип ссылок - якоря, т.е. гиперссылки на определенное место в HTML-документе. Их применяют также для навигации внутри одной страницы. Такие ссылки имеют большой недостаток при нажатии пользователем кнопки "Назад". Если пользователь сначала бродил по якорям внутри одной страницы, то нажав "Назад", он не выходит на предыдущую страницу, а начинает бродить по той же странице в обратном порядке. Следующим важным моментом, где разработчики сайтов часто ошибаются, являются заголовки и структура сайта в целом. Самая распространенная ошибка - ни о чем не говорящий пункт меню. Например, вы посещаете сайт какой-либо организации с названием ZZZ, и один из пунктов меню называется ZZZ. Это логически неправильно, т.к. весь сайт в целом посвящен организации ZZZ. Иногда в таких разделах бывает описание организации, но тогда этот раздел должен называться "О нас". Иногда там находится структура организации, тогда его надо переименовать и назвать "Структура". Очень часто в навигационном меню умещается одно слово, а подобрать такое одно слово, которое будет точно характеризовать раздел, не получается. В этом случае необходимо выбрать наиболее близкий вариант, а в атрибуте alt или title дать расшифровку из нескольких слов. Название меню и название страницы должны четко отражать содержимое страницы. |
Картинка командной строкиПоскольку сайт представляет собой совокупность гипертекстовых документов, то часто бывает, что на одну и ту же страницу можно попасть кучей разных способов. Поэтому, очень важно отметить, что гиперрсыллки, где пользователь уже побывал, должны менять цвет или выделяться каким-то особым образом. Неотемлемой частью сложной навигации являются поиск и полная карта сайта. Для поиска можно сделать локальную базу данных с ключевыми словами или же поставить механизм поиска с какого-нибудь поискового сервера. Карта сайта представляет собой обычное содержание, как в книге. Важно отметить, что число элементов меню на одном уровне не должно превышать 10. Оптимально 7. Иначе происходит перегрузка. Но это уже в большей степени работа редактора, который, уже исходя из своих профессиональных навыков и требований предметной области, разработает иерархическую структуру сайта. Отдельно необходимо рассмотреть выпадающие меню. Один способ мы рассматривали в главе JavaScript при помощи выпадающего списка. Есть еще способ, основанный на использовании слоев. Например, на сайте http://www.microsoft.com/rus/ такое меню.  У такого меню есть свои плюсы и минусы. Большой плюс в том, что в такое меню можно уместить огромную структуру сайта, и с одной страницы вы можете попасть в любой раздел. Минус в том, что не во всех броузерах это меню будет корректно отображаться. Правда, сейчас уже 98% процентов пользователей с MS Internet Explorer, поэтому сейчас этот аргумент не такой сильный. Более серьезным недостатком является проблема с индексированием такого сайта поисковыми машинами. Используйте выпадающее меню только, действительно, в случае крайней необходимости при большой структуре сайта. В своих проектах нам удавалось обходится без выпадающих меню. Кстати, такого рода меню можно сделать не только средствами JavaScript, но и средствами Flash. Но Flash'а может не оказаться на компьютере. Более того, мне приходилось наблюдать, как на современной машине с пятым Explorer'ом не просматривалось такое меню во Flash. Проблема оказалась в том, что на машине был третий, а не пятый Flash. Попытки обновить Flash тоже ни к чему не привели, почему-то новая версия не устанавливалась. Данный случай говорит только об одном, что не надо без крайней на то необходимости использовать неустоявшиеся технологии. |
НавигацияКое-что о навигации вы уже узнали из предыдущего параграфа. В данном параграфе мы попытаемся систематизировать наши знания о навигации. Целью навигации является быстрый доступ к нужной информации. Например, в книге навигацией служит содержание. Здесь же не могу не отметить, что в известных книгах по веб-дизайну и удобству использования веб-сайтов навигации, как ни странно, не оказалось. В первую очередь, я имею в виду книгу Стива Круга "Веб-дизайн или не заставляйте меня думать" и книгу Дмитрия Кирсанова "Веб-дизайн". Обе эти книги я прочел с большим интересом. Но вот, когда впоследствии мне требовалось найти конкретную информацию, то в содержании книги Ситва Круга перечислены только названия глав, без указания подразделов, т.е. параграфов. Более того, названия глав мало мне о чем говорили, т.к. имели в половине случаев очень абстрактные названия, и мне приходилось задумываться и листать книгу в поисках нужной информации. Тем самым, автор противоречил сам себе, он заставил меня серьезно думать и напрягаться в поиске нужной информации. В книге Дмитрия Кирсанова названия параграфов есть, но и они меня тоже зачастую ставили в затруднение. Но тут у меня нет никаких претензий, т.к. все-таки он дизайнер, и книга для дизайнеров, а я человек с техническим складом ума. Кстати, раз уж зашел разговор о книгах, то было бы неправильно не сказать и еще об одной замечательной книге Якоба Нильсона. Она тоже довольно интересна, хотя местами страдает чрезмерным рассмотрением вполне понятных и уже устоявшихся вещей. Все эти книги рекомендую прочитать. В конце данной книги будет дан полный список литературы, которую желательно прочитать и иметь всегда под рукой. Помимо быстрого доступа к информации посетителю важно понимать, где он находится. В книге такими указателями являются номера страниц. На сайте - это заголовки страниц и выделение в навигации текущего раздела. Имеет смысл сделать на сайте строчку с путем, где вы находитесь. Очень желательно, чтобы эта строчка коррелировала с URL документа. Но не всегда имеется возможность называть директории на сайте именами разделов. Названия разделов могут включать в себя спецсимволы или быть на русском языке. Очевидно! Тривиально! Удобно!Вспомните, как часто вам приходится напрягаться, посещая различные сайты? Либо шрифты и цвета на сайте такие, что невозможно прочитать информацию, либо вы не можете найти то, что вам нужно, либо процесс заполнения HTML-формы ставит вас в тупик. Сайт, как впрочем и любая информационная система, да и вообще любой продукт, должен быть очевидным, тривиальным и удобным в использовании. В плане очевидности пользователь всегда должен знать, что ему делать и какие ручки крутить в зависимости от его потребностей. В плане тривиальности не должно быть лишних ручек, кнопок и прочих механизмов, пугающих пользователя сложностью системы. Ну и наконец, пользователю должно быть удобно. В этой главе будет рассказано о том, что такое хорошо и что такое плохо, а также, как сделать так, чтобы было хорошо. При разработке сайта, в первую очередь, надо руководствоваться здравым смыслом. Сразу необходимо сделать небольшое отступление по поводу здравого смысла, т.к. особенность менталитета нашего русского человека в том, что зачастую здравый смысл - это его личное мнение, но никак не мнение большинства или кого-то еще. Ни в законах, ни в инструкциях здравого смысла нет - в этом убежден почти каждый россиянин, а вот в его голове есть. Мы, собственно говоря, и законов то не читали, а уже придумывали, как их обойти. В английском языке common sense, если переводить дословно - общее мнение, а на русский переводится, как здравый смысл. Итак, первое, что надо уяснить, что сайт разрабатывается для пользователей, а не для его разработчиков, руководителей проекта или заказчиков. И можно считать почти аксиомой, что мнение пользователей не совпадет с мнением заказчиков и исполнителей работ по сайту. Вот, в чем корень зла - причина, почему большинство сайтов не устраивают пользователей, и как следствие неэффективно выполняют свои задачи. Когда вы что-либо делаете, задавайте себе вопрос: "Зачем?". Сформулировав точный ответ на него, вы будете лучше понимать, что именно вам стоит сделать. Часто начинающий сайтостроитель, узнавая что-то новенькое, немедленно прикручивает это новенькое на сайт, чтобы все знали, насколько он крут. Итак, давайте постараемся перечислить причины почему получаютя плохие сайты: У сайта изначально были не определены или же неправильно определены цели и задачи. Сайт создавался с точки зрения руководства компании или менеджера проекта, а не его непосредственных пользователей. Разработчики не обладают должными знаниями и кругозором, а также не имеют серьезного опыта. Это основные причины, и они перечислены в порядке значимости. Да, именно в порядке значимости. Профессионализм команды разработчиков стоит на последнем месте. Если у вас неправильно определены цель и задачи сайта, то даже сама профессиональная команда не спасет ваш проект. Ваш прекрасно сделанный сайт останется никому не нужным. Мне доводилось наблюдать проекты, в которых сайт делался ради сайта. Кто-то где-то что-то услышал и решил, что надо сделать сайт, а зачем этот сайт делать, никто не знает. В подавляющем большинстве случаев возникают разногласия между исполнителями и заказчиками. Более детально о них мы поговорим в главе, посвященной управлению проектами по созданию веб-сайта. А пока давайте, с точки зрения пользователя, рассмотрим различные аспекты сайта. И начнем мы с того, что первым делом пользователь видит, посещая сайт. |
Скриншот мастер-дизайнПеречислим, что необходимо и должно присутствовать, и чего не должно быть на второстепенной странице: Несколько уменьшенный логотип в верхнем левом углу, который является гиперссылкой на главную страницу. Что это за раздел или сраница? В центральной части ассоциативная картинка, вместо девиза - название страницы, взглянув на которую, пользователь быстро ориентируется, куда он попал. Ассоциативная картинка справедлива только для крупных разделов. В большинстве случаев, наличие тематической картинки необязательно. Меню сервисов. Верхний правый угол. Меню страниц сайта. Идет горизонтально по центру. Меню разделов. Вертикально слева. В том разделе, где мы находимся, иерархически должно быть подменю (локальное меню данного раздела). Новости, опросники или кнопоки партнеров на второстепенной странице если присутствуют, то уже как сопутствующая информация по теме данного раздела. Основное свободное место под содержание документа. Координаты владельца сайта не нужны. Быстрая альтернативная навигация по всем страницам сайта внизу в центре должна обязательно присутствовать, т.к., если ваш документ занимает более 5 экранов, то пользователю утомительно пролистывать его обратно вверх. Заставка. Главная страница. Второстепенная страница.В наше время это случается уже не так часто, но все же случается. Пользователь при посещение сайта долго ждет загрузки и видит заставку. Заставка - вещь абсолютно бесполезная и ненужная. Постоянных пользователей сайта она будет приводить в бешенство. Конечно, можно задействовать механизм Cookie и сделать так, чтобы заставка показывалась только один раз, но все равно пользователь вынужден ждать, пока она загрузится, и есть риск, что не дождется и уйдет на другой сайт. Единственное, более или менее оправданное назначение заставки, выбор языка сайта. Но, однако, это не самое лучшее решение с точки зрения постановки задачи выбора языка. Локализированную версию сайта лучше держать в соответствующей доменной зоне. Например, русскоязычный сайт в зоне ru, англоязычный в зоне com или uk. Раньше заставки еще применялись для выбора кодировок - KOI-8R, WIN-1251, MAC, DOS. Впоследствии, где-то с выходом 3-х версий броузеров - это приблизительно 1996 год - проблема кодировок перестала существовать, т.к. появилась возможность выбирать кодировку в броузере. В настоящее время заставки получили новый импульс с появлением технологии Flash. Многие хотят обязать своих посетителей просмотреть Flash-ролик, надеясь произвести тем самым впечатление на пользователя. Мое мнение, что и эти заставки не нужны. Даже если поместите кнопку "Пропустить", то все равно пользователю нужно ждать начальной загрузки ролика и нажимать каждый раз кнопку "Пропустить". Если уж вам так хочется потратить деньги на Flash-ролик, то сделайте на главной странице сайта ссылку на этот Flash-ролик. Те пользователи, что сидят на хорошем канале, и которым это интересно, нажмут на эту ссылку и посмотрят вашу Flash'ку. Кроме заставок еще встречаются автоматически открывающиеся окна. Они тоже вредны и являются плохим признаком. Тут стоит запомнить одно простое правило: "Не надо насиловать пользователя и предлагать ему просмотреть то, что он не запрашивал". Пользователь открывает ваш сайт, а тут ему автоматом открывается еще одно окно.
Здесь скриншот Российского Вакуумного Общества с пояснениями.Теперь переходим к рассмотрению второстепенной страницы. Второстепенная страница должна быть выдержана в таком же стилевом оформлении, что и главная. Второстепенная страница, по сути - это несколько урезанная главная страница, где центральная часть отдается под конкретный документ. Хотя это не всегда так. Ниже приведены скриншоты главной и второстепенных страниц для сайта "Мастер-дизайн". Тестирование на этапе проектированияНа стадии проектирования необходимо оттестировать проектную документацию. Во-первых, документация должна быть полной, т.е. чтобы ее можно было отдать любой команде разработчиков и эта команда без дополнительных уточнений реализовала бы проект. Это, конечно, идеальная картина, но это то, к чему надо стремиться. Во-вторых, проектная документация должна описывать "правильную" систему, которая отражает суть происходящего. Не всегда правильно то, что говорит Заказчик. Совсем недавний пример. Мы разрабатывали веб-сайт для Российского Вакуумного Общества. У них регулярно проходят конференции. На конференцию, каждый автор присылает свои тезисы. Тезисы присылаются в формате Word. В конференции имеется несколько секций. Наша задача была осуществить пуликацию тезисов в Интеренет с возможностью обсуждения их, также нужно было генерировать всевозможные отчеты по авторам, расслать электронную почту и т.д. и т.п.. Был еще целый ряд требований к системе, но здесь их нет смысла приводить. Мы разработали гибкую систему, где автор после регистрации и оборения администратором может вносить свои тезисы. Естественно, уже можно вносить не тезисы, а полностью статью, т.к. места на сервере много. При вводе системы в эксплуатацию столкнулись с проблемой, которую не учли на стадии проектирования системы. На конференции есть коммиссия, которая может перебросить доклад по своему усмотрению из одной секции в другую, изменять названия докладов, создавать или удалять секции, и прочие мелкие изменения. В результате, получилось, что конференцию можно публиковать в Интеренет, только после утряски всех этих мелочей. Если в нашей системе тезисы, каждый автор сам публиковал, то в требуемой системе тезисы должны были публиковаться все разом. В данном случае мы сделали лишнюю работу, поэтому ничего переделывать не пришлось, просто кое-что отрезали. Если придется делать конференцию, где коммиссии нет или ее роль заключается только лишь в оценке докладов, но ни их корректировки, то наши разработки пригодятся. Тем не менее данный пример хорошо демонстирует ошибку заложенную на стадии проектирования. Для того чтобы такие ошибки исключить надо промоделировать работу системы. Моделировать можно просто перекладывая бумаги на столе. Необходимо убедиться, что система отвечает намеченным целям и решает все поставленные перед ней задачи.
|