Алгоритмы планирования
Для решения проблемы трансляции данных в беспроводной среде было предложено несколько алгоритмов-планировщиков, эффективность которых можно оценить по следующим показателям:
Время доступа. Время ожидания пользователем ответа на запрос. Состоит из двух компонентов — времени настройки и времени ожидания.
Время настройки. Период времени, в течение которого клиент прослушивает канал связи, читая пакет-дескриптор или поток пакетов данных, содержащих запрошенную сводную таблицу.
Время ожидания. Период времени, в течение которого клиент ожидает появления в канале запрашиваемого пакета-дескриптора. В этот период клиентский сетевой интерфейс на клиенте отключен, и канал не прослушивается.
Энергопотребление. Для мобильных клиентов сокращение энергопотребления особенно важно. Этот параметр имеет значение и для других компьютеров с учетом негативного эффекта излишнего нагрева, который снижает надежность цифровых сетей и повышает расходы на охлаждение.
В представленной модели запросы поступают на разные таблицы, размеры которых могут отличаться. Поэтому одинаковое качество обслуживания для всех запросов невозможно и нецелесообразно. С другой стороны, запросы можно логически сгруппировать в классы, качество сервиса для каждого из которых будет разным. Таким образом, эффективность алгоритма будет характеризовать показатель доступности (для его расчета используется дополнительные показатели):
Время обслуживания (service time) — время, необходимое серверу для завершения передачи таблицы в канал нисходящей связи в режиме без приоритетного прерывания.
Относительная длительность запроса (stretch) — отношение времени отклика (доступа) на запрос к времени обслуживания.
Доступность (fairness) — среднеквадратичное отклонение для значений параметра stretch.
Время обслуживания зависит от размера таблицы, и, следовательно, за счет параметра stretch удается нормализовать значение времени доступа относительно размера таблицы. Низкое значение стандартного отклонения указывает на правильно выбранную методику планирования задач трансляции, а высокое значение говорит о том, что для некоторого класса таблиц трансляция ведется не в оптимальном режиме.
Рассмотрим подробнее пять основных алгоритмов-планировщиков:
Первым прибыл — первым обслужен (First ComeFirstServed, FCFS),
Первый — с наименьшим временем обслуживания (ShortestServiceTimeFirst, SSTF),
Первыми — самые популярные запросы (Most RequestsFirst, MRF).
RxW,
STOBS-?.
Первым прибыл — первым обслужен (ПППО). Этот простой метод планирования предполагает, что запросы обслуживаются и транслируются по мере их поступления.
Первым — с наименьшим временем обслуживания (ПСВО). В первую очередь планировщик обслуживает тот элемент данных, который требует минимальных ресурсов. В нашем случае в качестве ресурса выступает канал нисходящей связи. Поэтому первым транслируется элемент данных с минимальным размером.
Первыми — самые популярные запросы (ПСПЗ). В первую очередь планировщик выбирает для трансляции тот элемент данных, на который поступило максимальное количество запросов.
RxW. В этой схеме используются преимущества ПСПЗ и ПППО. В каждом цикле трансляции сервер выбирает некоторый элемент с максимальным значением параметра R×W, где R — количество запросов на этот элемент, W — максимальное время ожидания ответа на запрос.
Описанные выше алгоритмы-планировщики в некоторых случаях работают хорошо, а в некоторых не дают приемлемых результатов. Выбор планировщика трансляции тесно связан с особенностями конкретного приложения, в котором могут применяться особые структуры данных и методы доступа. Пример тому, OLAP-кубы. Для них необходим специальный алгоритм, который повысил бы эффективность доступа в среде трансляции.
Особенности доступа к сводным OLAP-таблицам следующие:
Гетерогенность: сводные таблицы отличаются по размеру и количеству измерений.
Асимметричный доступ: запросы с OLAP-клиентов часто образуют некоторый «горячий участок» внутри решетки куба данных. Большинство запросов относится к таблицам небольшой размерности, а затем выполняется углубление в более детальные.
Зависимость извлечения: использование детальных таблиц для извлечения более абстрактных.
Планировщик трансляции сводных таблиц по запросу (Summary Tables On-DemandBroadcastScheduler,STOBS-?)
Этот алгоритм состоит из двух компонентов — нормализующего компонента, который учитывает первые две из перечисленных выше особенностей сводных таблиц, и ?-параметра, который позволяет транслировать одни и те же данные нескольким клиентам.
Сервер собирает запросы клиентов по мере их поступления. Для каждого запроса QX к сводной таблице TX рассчитываются следующие показатели:
R — количество запросов на TX. Эта величина увеличивается с поступлением каждого запроса на эту таблицу.
A — промежуток времени, затраченный запросом QX в ожидании таблицы TX.
S — размер таблицы TX.
При решении какую таблицу отправить следующей сервер выбирает запрос с максимальным значением параметра (RхA)/S.
Параметр ? определяет меру гибкости при передаче сводной таблицы и ликвидирует из очереди трансляции несколько зависимых от нее таблиц. Например, если ? = 2 и сервер выбирает для трансляции таблицу TX, то из очереди удаляются все запросы на любую таблицу TY, которая в решетке поиска находится двумя уровнями ниже и может быть выведена из TX (см. рис. 2 — таблица, которую можно вывести из другой, всегда находится ниже последней).
Формально, TY может и не транслироваться в случае передачи TX, если Y
X и |X| – |Y| ?? . Следовательно, клиент может использовать таблицу TX, включающую изначально запрашиваемую им таблицу TY, если Y
X и |X| – |Y| ??.
Значение a меняется в диапазоне от нуля до максимального размера куба данных — MAX. Если ?= 0, то никакой гибкости в использовании сводных таблиц нет, и доступ клиента возможен только при точном соответствии. Если a = MAX, то клиенту передается первая же таблица, включающая его исходный запрос. В случаях, когда 0 < ? < MAX, транслируется первая таблица, включающая исходную и расположенная в решетке куба на a уровней выше.
Проводя различия между STOBS-? и алгоритмами, требующими точного соответствия запросу, назовем описанные выше алгоритмы строгими (STOBS-0 также относится к этой категории), а семейство STOBS-?, где ? > 0, назовем гибкими.
При этом, значение ? известно серверу и клиентам (оно может входить в дескриптор таблицы).
В качестве примера рассмотрим решетку, показанную на рис. 3 (в ее узлах расположены сводные таблицы). QX — запрос на четырехмерную таблицу (d1, d2, d3, d4). Допустим, что узлы решетки, показанные на рисунке — это таблицы, на которые есть по крайней мере один запрос. Пусть ? = 2. Также предположим, что для трансляции выбрана таблица TX, соответствующая запросу QX. Тогда клиенты, запросившие таблицы (d1, d2), (d1, d3), (d1, d2, d3) и (d1, d2, d4) будут удовлетворены таблицей TX, а запросившие таблицы (d1), (d2), (d3) и (d4) будут ждать следующего цикла трансляции.

Рис. 3 Гибкость алгоритма.
Параметр (RхA)/S учитывает все факторы, влияющие на время доступа, параметр aопределяет меру гибкости алгоритма. Преимущество гибкого подхода к трансляции состоит в том, что удовлетворяется запрос клиента не только в случае точного соответствия. Недостаток — лишнее время, которое тратит клиент, прослушивая в канале детальную, а не сводную таблицу. Выбрав разумное значение ?, можно найти приемлемый баланс между сокращением времени ожидания и увеличением времени прослушивания.
Беспроводная OLAP-модель
На рис. 1 показана архитектура среды, в которой трансляция данных происходит по запросу пользователей. Эта схема в наибольшей мере подходит для поддержки беспроводной обработки OLAP-запросов. Функции сервера состоят в поддержке и распространении сводных таблиц. Интересно, что проблема планирования трансляции, возникающая в беспроводных OLAP-системах, характеризуется вышеупомянутой особенностью — зависимостью извлечения. Иными словами, каждый клиентский запрос направлен на одну сводную таблицу, но эта таблица может включать в себя другую сводную таблицу, запрашиваемую иным клиентом. Однако каждая таблица, отвечающая определенному запросу, требует некоторых затрат на обработку, и при выборе конкретной таблицы для трансляции необходимо эти издержки учитывать.
Так как для эффективной рассылки данных общие алгоритмы планирования доставки часто используют агрегирование запросов, то зависимость извлечения дает дополнительную возможность оптимизации, повышая производительность и масштабируемость.
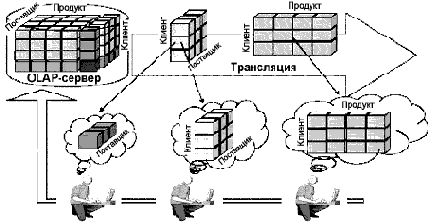
Рис.1. Беспроводная OLAP-система
Например (см. рис. 1), зафиксировав значение по измерению «Клиент» из детализированной таблицы («Поставщик – Клиент») можно получить абстрактную таблицу («Поставщик»).
Таким образом, идея использования сводных таблиц для выведения одних таблиц из других используется довольно широко. Ее смысл состоит в выборе надлежащего набора таблиц для хранения, чтобы повысить скорость обработки запросов, учитывая пространственные ограничения.
Для упрощения процесса выбора используется решетка поиска, которая представляет собой направленный граф, отображающий пространство подкубов, между которыми фиксируются зависимости извлечения. Например на рис. 2 показана решетка для схемы «Поставщик (ПС) – Продукт (ПР) – Клиент (К)».
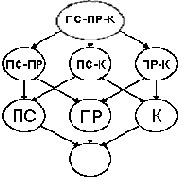
Рис.2. Решетка Кубов Данных
Зависимость извлечения сводных таблиц и идея решетки поиска применяется при выборе таблиц при трансляции в беспроводных каналах для минимизации времени ожидания ответа на запрос пользователя.
В этом случае предполагается, что все решетки подкубов хранятся на сервере (такое допущение разумно, особенно для относительно небольших витрин данных). Клиент посылает запрос на таблицу по каналу восходящей связи. Затем он прослушивает канал нисходящей связи в ожидании ответа. Клиент может находиться в одном из двух режимов:
в режиме настройки (tune), прослушивая канал трансляции;
в режиме ожидания ответа (wait).
Выполнение запросов клиентов полностью зависит от сервера, доступ к локальному хранилищу и кэширование предыдущих ответов для последующего использования не осуществляется.
Минимальная единица трансляции называется пакетом (packet) или сегментом (bucket). Транслируемая таблица разделяется на одинаковые по размеру пакеты, первый из которых называют пакетом-дескриптором (descriptor). В заголовке пакета передаются данные или дескриптор, а также расстояние (временной интервал) до начала следующего пакета-дескриптора и расстояние от начала дескриптора до пакета. Пакет-дескриптор содержит таблицу с идентификатором, описывающим агрегируемые измерения транслируемой таблицы, количество значений атрибутов или кортежей и количество пакетов данных, составляющих эту таблицу.
Период передачи таблицы называют циклом трансляции (broadcast cycle): каждая таблица передается в течение определенного цикла, который начинается с момента трансляции пакета-дескриптора. Длительности циклов для разных таблиц при этом могут различаться.
Пусть запрос в восходящий канал связи Q характеризуется набором Group-By атрибутов D. Тогда запрос представим как QD, а соответствующую ему таблицу как TD. Сводная таблица TD1 включает в себя таблицу TD2, если D2
D1, или, другими словами, TD2 зависит от TD1. Обозначим количество атрибутов (измерений) в множестве D как |D|.
Посылая в канал восходящей связи запрос на некоторую таблицу TR, клиент сразу же настраивается на нисходящий канал в поиске пакетов-дескрипоторов.
Обнаружив такой пакет, клиент классифицирует содержащуюся в нем таблицу (пусть это будет TB) следующим образом:
Точное соответствие: измерения в сводной таблице TB совпадают с измерениями в таблице TB (т.е. R = B).
Включающее соответствие: TB включена в TR, но TB в точности не соответствует TR (т.е., R
B и R ? B).
Нет соответствия: R
B.
Например: пусть R = («Поставщик – Продукт»), тогда B1 = («Поставщик – Продукт – Клиент») включает R, а для B2 = («Продукт») и B3 = («Поставщик – Клиент») не имеется соответствия. В зависимости от типа соответствия клиент будет либо настраиваться на получение дальнейшей последовательности пакетов для чтения таблицы TB, либо ожидать следующего цикла трансляции.
Методы трансляции
В беспроводных сетях трансляция является основным методом функционирования на физическом уровне. Именно она используется для распространения информации в беспроводных каналах и гарантирует масштабируемость при передаче большого объема данных. Особенно эффективно рассылку данных можно осуществлять, комбинируя две схемы — push- и pull-трансляцию. Этот подход основан на асимметрии в беспроводных коммуникациях и позволяет сократить энергопотребление в режиме приема. Предполагается, что клиентские устройства — небольшие, портативные, а в качестве источников питания обычно используют аккумуляторы. Что же касается серверов, то у них производительность канала связи и мощность для передачи больших объемов данных намного больше, чем у клиентских устройств.
В режиме push-трансляции сервер многократно посылает информацию без опроса клиентов. Любое число клиентов может прослушивать канал трансляции и извлекать информацию. Если данные подстроены точно под нужды клиентов, то такая схема эффективно использует низкую пропускную способность беспроводного канала и идеальна для достижения максимальной масштабируемости.
В режиме pull-трансляции клиенты посылают конкретные запросы. Если на одни и те же данные приблизительно в одно и то же время поступает несколько клиентских запросов, то сервер может их агрегировать и передать данные только один раз. Такая схема также позволяет эффективно использовать канал с низкой пропускной способностью и очевидно повышает эффективность приема информации пользователем.
Мобильные клиенты
Особая ситуация возникает, когда клиентские места представляют собой мобильные устройства. В данном случае самое главное — экономия энергии. Как уже говорилось, мобильные компьютеры работают от аккумуляторов, которые располагают ограниченным ресурсом мощности. Поэтому сокращение энергопотребления является одним из основных условий, которое должно быть учтено при разработке алгоритма трансляции.
Решением этой проблемы являются методы индексирования для запросов с одним или множеством атрибутов. Основная их идея состоит в том, чтобы обеспечить на клиенте достаточную информацию по индексации, при этом характер доступа к потоку данных мобильного устройства может меняться от «спящего»(doze) режима ожидания до активного (active), когда прослушиваются все поступающие данные. Очевидно, что в спящем режиме потребляемая мощность в десятки раз меньше, чем в активном.
Описанная выше модель соответствует условиям для мобильного доступа. Напомним, что в каждом заголовке пакета есть указатель, задающий временной шаг для следующего пакета-дескриптора в трансляции. Послав запрос, компьютер-клиент прослушивает нисходящий канал и настраивается на первый пакет-дескриптор. Если ему подходят следующие пакеты данных, он остается в активном режиме и скачивает транслируемую таблицу, если нет — переходит в спящий режим, экономя энергопотребление. Переключение в активное состояние происходит согласно прочитанному временному сдвигу только перед началом следующего цикла трансляции (то есть перед получением пакета-дескриптора для очередной передаваемой таблицы). Активизировавшись, клиент получает дескриптор и повторяет проверку на соответствие.
Сравнение алгоритмов
Все описанные выше алгоритмы сравнивались в соответствие с упомянутыми показателями эффективности. Превосходство схемы STOBS-? наблюдается как в отношении времени доступа, так и в отношении равнодоступности и сокращения энергопотребления.
В таблице 1 для каждого алгоритма указано среднее время доступа и среднее потребление энергии на запрос в сети, состоящей из90 клиентов.
Таблица 1. Сравнение алогоритмов-планировщиков.
| Алгоритм | Среднее время доступа (сек) |
Среднее потребление энергии (Дж) |
| ПСВО | 9,5 | 0,64 |
| ПППО | 10,1 | 0,66 |
| RxW | 7,2 | 0,53 |
| STOBS-0 | 4,9 | 0,43 |
| STOBS-2 | 2,9 | 0,40 |
В статье проведен краткий обзор
В статье проведен краткий обзор новых подходов к эффективной поддержке «мобильного» принятия решений, при этом акцент был сделан на важности метода трансляции, который обеспечивает эффективный доступ к Хранилищу данных предприятия. И хотя речь шла в основном о беспроводных и мобильных вычислительных средах, те же результаты можно использовать и в кабельных сетях, где поддерживается многоадресная передача.
В результате:
Рассмотрен новый способ объединения запросов, основанный на зависимости извлечения (derivation dependencies) между сводными таблицами, в сравнении с методом, основанным на точном соответствии запросу.
Алгоритмы-планировщики были разделены на две категории (строгие и гибкие) в зависимости от возможности передачи более детальных таблиц в качестве ответа на запрос. Кратко описано семейство эвристик STOBS, позволяющих сократить время доступа и энергопотребление при передаче OLAP-кубов.
Проведено небольшое сравнение существующих алгоритмов планирования в отношении их пригодности для рассылки сводных таблиц OLAP.
В целом можно отметить, что базовый алгоритм STOBS обеспечивает разумный компромисс между различными параметрами трансляции, что приводит к существенному сокращению среднего времени доступа и потребления энергии для беспроводных клиентов. Кроме того, он дает хороший баланс между сокращением времени ожидания и увеличением времени прослушивания канала. Последнее особенно важно для пользователей мобильных компьютеров.