Дуплексная работа
Аппаратная отказоустойчивая система реализуется с помощью дуплексной пары, которая создается путем соответствующего конфигурирования двух процессорных модулей. Идентичное состояние памяти и кэшей в этих двух модулях поддерживается благодаря выполнению на обоих ЦП одного и того же программного кода с теми же самыми данными, а также поступлению в память обоих ЦП всего потока ввода. Оба ЦП генерируют идентичные исходящие потоки вывода. Один из этих потоков выбирается маршрутизаторами для пересылки в контроллеры в/в или другие процессоры.
Дуплексная работа затрагивает три аспекта построения системы: межмодульную синхронизацию, синхронизацию уровня линий связи ServerNet и обработку ошибок. Для реализации дуплексного режима требуются два маршрутизаторов в различных подсетях ServerNet и два ЦП, подсоединенные к разным шинам когерентности (для работы с разделяемой памятью). Отказ одного из компонентов системы не может вывести из строя оба ЦП или оба маршрутизатора. Все ЦП, разделяющие шину когерентности, имеют общую синхронизацию. Специалисты Tandem называют эту комбинацию процессорных модулей (ЦП), шины когерентности и системы синхронизации слайсом. Система, сконфигурированная для дуплексной работы, имеет два слайса.
Работа дуплексной системы требует синхронной работы двух слайсов. ЦП в каждом слайсе в одном и том же такте выполняют идентичные команды. Входной поток ввода поступает в интерфейс памяти каждого ЦП в одном и том же такте. Поэтому в нормальных условиях при отсутствии неисправностей поведение слайсов будет полностью идентичным.
Модули ЦП имеют развитые средства обнаружения неисправностей. ЦП останавливается при обнаружении его схемами контроля любой ошибки. Остановка ЦП приводит к тому, что по обоим его портам ServerNet будет передана запрещенная кодовая комбинация. В результате маршрутизатор может определить неисправный ЦП (основополагающим правилом системы установлено, что все ошибки ЦП должны приводить к передачам по ServerNet запрещенных кодовых комбинаций).
Когда маршрутизатор, подсоединенный к дуплексному ЦП, обнаруживает ошибку, он начинает выполнение протокола восстановления. Этот протокол реализован полностью аппаратно без привлечения программных средств. При этом один из ЦП исключается из работы, а другой свою работу продолжит. Протокол гарантирует, что исправный ЦП останется работать. Однако существуют случаи, когда в исключенном ЦП неисправности отсутствуют. Например, к исключению ЦП из работы могут привести неисправности в одном из маршрутизаторов или в одной из линий связи ServerNet. В этих случаях система обслуживания может исключить из работы неисправный маршрутизатор, а исключенный ЦП перевести в состояние online.
Если при пересылке пакета из ЦП маршрутизатор обнаруживает неисправность линии связи ServerNet, он помечает пакет как недостоверный. Любой узел ServerNet, который получит этот пакет, будет его игнорировать. Это означает, что неисправность в ЦП, маршрутизаторе или линии связи может привести к потере одного или нескольких пакетов. При нормальной дуплексной работе только один из двух маршрутизаторов дуплексных процессоров пересылает пакеты, поступающие из каждого ЦП. Это ограничивает потерю пакетов пределами одной подсети ServerNet. Интерфейсные кристаллы обнаруживают потерю пакетов ServerNet с помощью средств временного контроля. Программное обеспечение ввода/вывода выполняет восстановление путем повторной передачи данных по альтернативному пути.
Емкость и пропускная способность дисковой памяти
Одной из наиболее общих проблем в СУБД является обеспечение большой емкости дисковой памяти для хранения данных при достаточной пропускной способности дисковой подсистемы. На большинстве серверов при выполнении обращений к диску доминируют операции произвольного доступа. Сегодня на рынке доступны множество дисков, но их производительность при выполнении операций произвольного доступа почти одна и та же:
Таблица 2.4.Временные параметры некоторых дисков
| НМД | Задержка вращения (мс) |
Среднее время поиска (мс) | Скорость обращений к диску оп/с, Мб/с (объем блока данных - 8 Кб) | |
| Полностью произвольные |
Полностью последовательные |
|||
| 424 Мб | 6.8 | 14 | 50, 0.400 | 323, 2.6 |
| 535 Мб | 5.56 | 12 | 57, 0.456 | 451, 3.6 |
| 1.05 Гб | 5.56 | 11.5 | 67, 0.536 | 480, 3.8 |
| 2.1 Гб | 5.56 | 11.5 | 62, 0.496 | 494, 4.0 |
Хотя диск 2.1 Гб имеет впятеро большую емкость, чем диск 424 Мб, он обеспечивает только на 24% лучшую скорость выполнения операций произвольного доступа. В действительности диск 1.05 Гб быстрее, чем диск 2.1 Гб. (Хотя их характеристики очень близки, диск 1.05 Гб имеет дополнительное фирменное обеспечение в своем встроенном контроллере. Главное отличие состоит в том, что контроллер диска 1.05 Гб способен соединяться и разъединяться с шиной SCSI намного быстрее, чем контроллер диска
2.1 Гб). По этим причинам наилучшие результаты почти всегда достигаются при использовании наименьшего по емкости диска, даже когда больший диск имеет превосходные спецификации по всем параметрам. Например, сервер SPARCserver 1000 может оснащаться дисками емкостью 535 Мб, 1.05 Гб и 2.1 Гб. Как видно из таблицы 2.5, для заданного объема дисковой памяти (16 Гбайт), общая пропускная способность дисковой подсистемы существенно выше при использовании дисков 535 Мб (больше чем в три раза).
Использование дисков такой малой емкости не всегда практично, поскольку общие требования к емкости дисковой подсистемы могут привести к использованию дисков большей емкости, или возможно в системе окажется недостаточно доступных слотов периферийной шины для конфигурирования необходимого числа главных адаптеров SCSI. Тем не менее, целесообразно рассмотреть возможность использования дисковых подсистем с большей пропускной способностью в таких системах, где о действительной нагрузке ввода/вывода известно, что она носит взрывной характер, либо полностью неизвестна, или где общий объем данных относительно невелик по сравнению с количеством имеющих к ним доступ пользователей.
Таблица 2.5. Пропускная способность ввода/вывода для дисковой памяти емкостью 16 Гб
| НМД | Требуемое количество | Общая скорость оп/с |
Строк SCSI | Стоимость (1994 г.) | Цена за операцию |
| 535 Мб | 32 | 1824 | 8 | $50360 | $27 |
| 1.05 Гб | 16 | 1072 | 4 | $39580 | $37 |
| 2.1 Гб | 8 | 496 | 2 | $37390 | $75 |
Было бы серьезной ошибкой подбирать для системы дисковые накопители исключительно исходя из требуемой общей емкости дисковой памяти. Хотя эта проблема не нова, со временем она становится все более серьезной, поскольку емкость дисковых накопителей и требования к общей емкости дисковой памяти начинают увеличиваться значительно более быстрыми темпами, чем пропускная способность дисков.
Рекомендации:
Чтобы добиться наибольшей общей производительности и пропускной способности дисковой подсистемы следует конфигурировать наименьшие по емкости дисковые накопители. На одной шине Fast SCSI-2 (10 Мб/с) следует конфигурировать умеренное число (3-5) дисков. Для шины Fast-and-Wide SCSI (20 Мб/с) количество дисков может быть увеличено немного более чем в два раза (8-11 дисков). Количество шин SCSI следует выбирать максимально возможным, естественно с учетом других ограничений. Для увеличения эффективной пропускной способности дисковой подсистемы следует использовать специальные программные средства типа On-line:DiskSuite и расщепление дисков.Файловые системы по сравнению с "чистыми" (неструктурированными) дисками
Большинство СУБД позволяют администратору системы выбрать способ размещения файлов СУБД (на "чистых" дисках или в стандартной файловой системе UNIX). Некоторые системы, наиболее известными из которых являются Ingres и Interbase, навязывают использование файловой системы UNIX. Для систем, которые допускают выбор указанных возможностей, приходится оценивать целый ряд разных критериев.
Хранение данных в файловой системе оказывается менее эффективным (отличие составляет по крайней мере 10%), поскольку при выполнении каждого обращения к диску со стороны СУБД в работу включается дополнительный слой системного ПО. Поскольку в больших СУБД часто одним из ограничивающих ресурсов является мощность процессора, использование "чистых" разделов (raw partition) улучшает производительность системы при пиковой нагрузке. Только по этой причине большинство администраторов баз данных обычно предпочитают хранение данных на "чистых" разделах дисков. Если ожидается, что система достигнет своих пределов производительности, особенно в части использования мощности ЦП, то это может быть наиболее подходящий выбор. Однако следует отметить, что эффективность процессора в действительности становится под вопрос только под пиковой нагрузкой. Большинство же систем испытывают эти пиковые нагрузки только в очень редких случаях.
Хранение данных в файловой системе имеет также определенную цену в терминах потери емкости памяти. Файловая система UNIX потребляет примерно 10% от форматированной емкости дисков для метаданных о файлах и файловой системе. Более того, файловая система резервирует 10% оставшегося пространства, чтобы обеспечить быстрый поиск свободного пространства в случае расширения файлов (этот дополнительный объем памяти в принципе может быть использован, но за счет потенциально значительных дополнительных задержек, которые возникнут при открывании или расширении файлов файловой системы). Если СУБД работает с данными через файловую систему, то по сравнению с "чистым" диском емкость дисковой памяти в целом уменьшается на 19%.
Если хранение данных в файловой системе обходится дороже как с точки зрения потребления мощности процессора, так и с точки зрения потерь емкости памяти, возникает вопрос: "А зачем все это нужно?". Имеется несколько важных причин, по которым в СУБД используется хранение данных в файловой системе. Большинство из них связано с обеспечением гибкости или относятся к разряду более знакомой для пользователя технологии.
Во-первых, и что возможно наиболее важно, использование файловой системы позволяет работать с памятью с помощью стандартных утилит UNIX. Например, стандартные утилиты UNIX ufsdump и ufsrestore могут использоваться для того, чтобы производить надежное резервное копирование и восстановление памяти СУБД. Для этого могут также использоваться не связанные с операционной системой инструментальные средства резервного копирования, подобные Online:Backup 2.0 компании Sun. Кроме того, гораздо проще осуществлять манипулирование отдельными частями базы данных. Например, можно осуществлять прямое перемещение таблицы с одного диска на другой, даже если используются диски разного размера и типа. Поскольку каждый из поставщиков СУБД предлагает свои собственные внутренние утилиты резервного копирования и восстановления, все они различны. Более того, некоторые из них выполняются настолько медленно, что заказчики часто прибегают к использованию копирования физических томов (т.е. используют команду dd(1)) со всеми присущими такому копированию сложностями. Хранение данных в файловой системе позволяет выполнять единообразные, надежные процедуры для того, чтобы работать через систему и сеть. При этом, если необходимо, могут также использоваться инструментальные средства поставщиков СУБД.
При некоторых обстоятельствах операции через файловую систему дают возможность оптимизации, которую сама СУБД не может реализовать. В частности, файловая система UNIX пытается кластеризовать данные в более крупные физические единицы, чем большинство СУБД. Поскольку дисковое пространство для таблиц часто заранее распределено, файловой системе обычно удается агрегатировать данные в блоки объемом по 56 Кб, в то время как менеджеры памяти СУБД обычно оперируют только страницами размером в 2 (или иногда 8) Кб. Последовательное сканирование таблиц или индексов, хранящихся таким образом часто может оказаться более эффективным, чем эквивалентных таблиц, хранящихся более традиционным способом. Если в операциях системы доминирует последовательное сканирование (или операции соединения (joins), которые часто подразумевают последовательное сканирование), хранение данных в файловой системе обеспечивает более высокую производительность.
Рекомендации:
Для обеспечения максимальной пиковой производительности следует конфигурировать "чистые" диски. При размещении таблицы СУБД в файловой системе UNIX следует добавить 19% дополнительного дискового пространства на накладные расходы файловой системы. Для обеспечения максимальной гибкости можно размещать таблицы СУБД в файловых системах. Если СУБД хранит таблицы в файловой системе UNIX следует сконфигурировть 15% дополнительной памяти (или соответственно более маленький кэш разделяемых данных).Физическая реализация архитектуры
Ниже на Рисунок 4.5 показана схема, представляющая системные платы, разработанные компанией Bull, которые используются для физической реализации архитектуры PowerScale.
Многопроцессорная плата:
Многопроцессорная материнская плата, которая используется также в качестве монтажной панели для установки модулей ЦП, модулей основной памяти и одной платы в/в (IOD).
Модуль ЦП (дочерняя процессорная плата):
Каждый модуль ЦП, построенный на базе PowerPC 601/604, включает два микропроцессора и связанные с ними кэши. Имеется возможность модернизации системы, построенной на базе процессоров 601, путем установки модулей ЦП с процессорами 604. Смешанные конфигурации 601/604 не поддерживаются.
Дочерняя плата ввода/вывода: (IOD)
IOD работает в качестве моста между шинами MCA и комплексом ЦП и памяти. Поддерживаются 2 канала MCA со скоростью передачи 160 Мбайт/с каждый. Хотя поставляемая сегодня подсистема в/в базируется на технологии MCA, это не является принципиальным элементом архитектуры PowerScale. В настоящее время проводятся исследования возможностей реализации нескольких альтернативных шин ввода/вывода, например, PCI.
Физическая реализация PowerScale
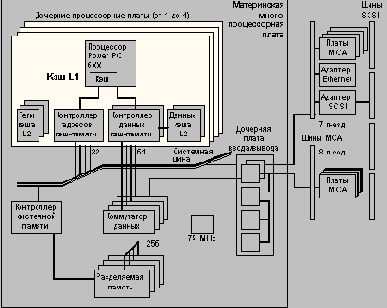
Каждая плата памяти состоит из четного числа банков. Максимальное число банков равно 16. Объем памяти на каждой плате может быть 64, 256 или 512 Мбайт.
Коммутатор данных (DCB) интегрирован в нескольких СБИС (4х16 бит) и функционально соединяет магистраль данных MPB_SysBus с подсистемой памяти, модулями ЦП и платой в/в. Ширина магистрали данных DCB на уровне массива памяти составляет 256 + 32 бит, а ширина магистрали данных для каждого порта ЦП и порта в/в равна 64 + 8 бит. Операции DCB управляются контроллером системной памяти (SMC) с помощью командной шины, обеспечивающей необходимую коммутацию устройств.
Гибкость доступа к данным
Использование мониторов транзакций практически не накладывает каких-либо ограничений на многообразие или сложность запросов доступа к нижележащей СУБД. Например, вполне осмысленной оказывается транзакция, выдающая запрос на набор данных из базы данных DB2 на мейнфрейме IBM, работающей под управлением ОС MVS, а другой набор данных из локальной базы данных Sybase, и затем сливающая оба набора вместе для представления приложению. В результате создается иллюзия того, что данные хранятся в унифицированной базе данных, размещенной в одном и том же "хранилище данных" (data warehause).
В связи с тем, что во многих "старых" (legacy) системах используются мониторы обработки транзакций CICS, мигрирующая часть или все базы данных, связанные с этими системами, могут работать с небольшими изменениями существующих приложений. Все что требуется - это физический перенос данных на новую платформу и модификация описания транзакций для использования данных на новом месте. Однако сложность такого переноса не должна недооцениваться, поскольку он часто требует внесения изменений в представление данных (трансляцию COBOL "PIC 9(12)V99S" в C++ float) и организацию данных (например, из сетевой архитектуры IMS в реляционную архитектуру, используемую почти повсеместно СУБД на базе UNIX). Но возможность сохранить части, связанные с прикладной обработкой и представлением существующих приложений существенно сокращает сложность и риск, связанные с таким переносом.
Характеристики межсоединений некоторых коммерческих MPP
В частности, чтобы предотвратить появление узкого горла в системе, связанного с единым справочником, можно распределить части этого справочника вместе с устройствами распределенной локальной памяти. Таким образом можно добиться того, что обращения к разным справочникам (частям единого справочника) могут выполняться параллельно, точно также как обращения к локальной памяти в распределенной памяти могут выполняться параллельно, существенно увеличивая общую полосу пропускания памяти. В распределенном справочнике сохраняется главное свойство подобных схем, заключающееся в том, что состояние любого разделяемого блока данных всегда находится во вполне определенном известном месте. На Рисунок 3.33 показан общий вид подобного рода машины с распределенной памятью. Вопросы детальной реализации протоколов когерентности памяти для таких машин выходят за рамки настоящего обзора.
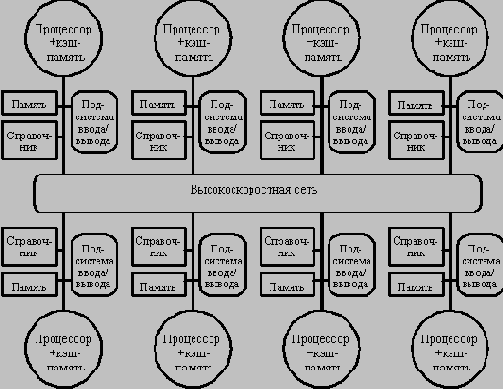
Архитектура системы с распределенной внешней памяью и
распределенным по узлам справочником
Характеристики рабочей нагрузки (тесты TPC)
В отличие от NFS, где примерно можно понять, какая нагрузка навязывается серверу, без знания деталей приложения, охарактеризовать нагрузку, генерируемую приложением базы данных, невозможно без детальной информации о том, что же в действительности приложение делает. Даже имея подобные сведения, приходится сделать множество предположений о том, как сама СУБД будет обращаться к данным, насколько эффективным может оказаться дисковый кэш СУБД при выполнении определенных транзакций, или даже о том, какова может быть смесь транзакций.
На сегодня в промышленности приняты следующие типы характеристик нагрузки, генерируемой приложением базы данных: "легкая", "средняя", "тяжелая" и "очень тяжелая". Категория "легкая" приравнивается к рабочим нагрузкам, которые доминируют в операциях, подобным транзакциям дебит/кредит, определенным в оценочных тестах TPC-A. Нагрузками "средней" тяжести считаются транзакции, определенные стандартом теста TPC-C. Тяжелыми рабочими нагрузками считаются нагрузки, которые ассоциируются с очень большими приложениями, такими как Oracle*Financials. Такие нагрузки по крайней мере в 5-10 раз тяжелее, чем принятые в тесте TCP-A, а некоторые являются даже еще более тяжелыми.
Основным классом приложений, которые попадают в категорию "очень тяжелой" нагрузки, являются системы поддержки принятия решений. Из-за очень больших различий в природе запросов к системе поддержки принятия решений, администраторы баз данных или самой СУБД сталкиваются с очень большими проблемами по обеспечению широкомасштабной, полезной оптимизации. Запросы к системе поддержки принятия решений часто приводят к формированию существенно большего числа запросов к нижележащей системе из-за необходимости выполнения многонаправленных соединений, агрегатирования, сортировки и т.п. Тест TPC-D был специально разработан для оценки работы приложений поддержки принятия решений.
Иерархия памяти
При разработке процессора R10000 большое внимание было уделено эффективной реализации иерархии памяти. В нем обеспечиваются раннее обнаружение промахов кэш-памяти и параллельная перезагрузка строк с выполнением другой полезной работой. Реализованные на кристалле кэши поддерживают одновременную выборку команд, выполнение команд загрузки и записи данных в память, а также операций перезагрузки строк кэш-памяти. Заполнение строк кэш-памяти выполняется по принципу "запрошенное слово первым", что позволяет существенно сократить простои процессора из-за ожидания требуемой информации. Все кэши имеют двухканальную множественно-ассоциативную организацию с алгоритмом замещения LRU.
Иллюстрация проблемы когерентности кэшпамяти
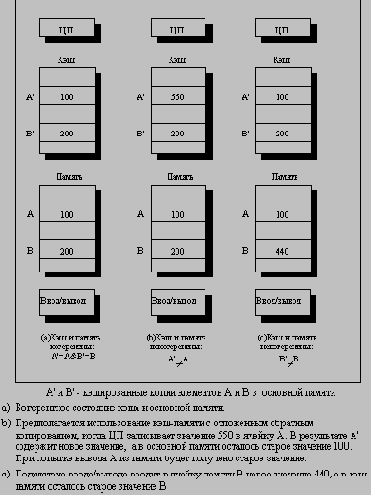
С этим простым определением согласованного состояния памяти мы можем гарантировать когерентность путем обеспечения двух свойств:
-
Операция чтения ячейки памяти одним процессором, которая следует за операцией записи в ту же ячейку памяти другим процессором получит записанное значение, если операции чтения и записи достаточно отделены друг от друга по времени.
Операции записи в одну и ту же ячейку памяти выполняются строго последовательно (иногда говорят, что они сериализованы): это означает, что две подряд идущие операции записи в одну и ту же ячейку памяти будут наблюдаться другими процессорами именно в том порядке, в котором они появляются в программе процессора, выполняющего эти операции записи.
Первое свойство очевидно связано с определением когерентного (согласованного) состояния памяти: если бы процессор всегда бы считывал только старое значение данных, мы сказали бы, что память некогерентна.
Необходимость строго последовательного выполнения операций записи является более тонким, но также очень важным свойством. Представим себе, что строго последовательное выполнение операций записи не соблюдается. Тогда процессор P1 может записать данные в ячейку, а затем в эту ячейку выполнит запись процессор P2. Строго последовательное выполнение операций записи гарантирует два важных следствия для этой последовательности операций записи. Во-первых, оно гарантирует, что каждый процессор в машине в некоторый момент времени будет наблюдать запись, выполняемую процессором P2. Если последовательность операций записи не соблюдается, то может возникнуть ситуация, когда какой-нибудь процессор будет наблюдать сначала операцию записи процессора P2, а затем операцию записи процессора P1, и будет хранить это записанное P1 значение неограниченно долго. Более тонкая проблема возникает с поддержанием разумной модели порядка выполнения программ и когерентности памяти для пользователя: представьте, что третий процессор постоянно читает ту же самую ячейку памяти, в которую записывают процессоры P1 и P2; он должен наблюдать сначала значение, записанное P1, а затем значение, записанное P2. Возможно он никогда не сможет увидеть значения, записанного P1, поскольку запись от P2 возникла раньше чтения. Если он даже видит значение, записанное P1, он должен видеть значение, записанное P2, при последующем чтении. Подобным образом любой другой процессор, который может наблюдать за значениями, записываемыми как P1, так и P2, должен наблюдать идентичное поведение. Простейший способ добиться таких свойств заключается в строгом соблюдении порядка операций записи, чтобы все записи в одну и ту же ячейку могли наблюдаться в том же самом порядке. Это свойство называется последовательным выполнением (сериализацией) операций записи (write serialization). Вопрос о том, когда процессор должен увидеть значение, записанное другим процессором достаточно сложен и имеет заметное воздействие на производительность, особенно в больших машинах.
Инициализация
Сервисные процессоры несут полную ответственность за инициализацию системы. Во время начальной установки системы они прежде всего создают полный перечень доступных в стойке ресурсов, используя шины обслуживания и перепрограммируемые ПЗУ, которые хранят информацию о конфигурации всех компонентов системы. Затем сервисные процессоры инициализируют эти компоненты, используя интерфейс сканирования.
Вслед за этим сервисные процессоры, расположенные в разных стойках, включаются в процесс динамического определения топологии ServerNet. Этот процесс не зависит от ранее полученных данных по конфигурации системы. Он работает ниже уровня передачи пакетов ServerNet, поскольку предшествует установке средств маршрутизации. После того как сервисные процессоры определили топологию сети, они выполняют назначение идентификаторов узлов ServerNet и программирование таблиц маршрутизации в маршрутизаторах.
Затем сервисные процессоры начинают выполнение начальной установки операционной системы на главном процессоре. Сервисные процессоры сообщают программе начальной загрузки и операционной системе перечень аппаратных средств и информацию об их конфигурации, включая адреса ServerNet для каждого устройства системы.
Исполнительные устройства
В процессоре R10000 имеются пять полностью независимых исполнительных устройств: два целочисленных АЛУ, два основных устройства плавающей точки с двумя вторичными устройствами плавающей точки, которые работают с длинными операциями деления и вычисления квадратного корня, а также устройство загрузки/записи.
Использование ресурсов ввода/вывода
При разработке подсистемы ввода/вывода должно быть уделено внимание не только максимальной емкости ее компонентов, но также уровню использования (загруженности) каждого ресурса. Большинство параметров, используемых для описания емкости ресурсов, так или иначе связаны с пропускной способностью. Например, шина SCSI характеризуется пропускной способностью в 10 Мбайт/с. Это скорость пересылки битов по шине. Такой параметр не дает информации о том, насколько занята сама шина и, следовательно, не дает также информации о том, сколько времени будет потрачено на обслуживание данного запроса. Приводить в качестве параметра ресурса рейтинг максимальной пропускной способности - все равно, что говорить, что предел скорости автомагистрали равен 130 км в час: если въезды и съезды с нее так перегружены, что это занимает длительное время, то общая скорость вероятно будет намного ниже установленного предела.
Точно такие же принципы применимы к различным периферийным устройствам и периферийным шинам. В частности, это справедливо и для шин SCSI. Экспериментальные результаты показывают, что если должна поддерживаться пиковая производительность, то степень загруженности шины SCSI должна поддерживаться на уровне 40%. Аналогичным образом, степень загрузки дисков должна поддерживаться на уровне 60%. Диски могут выдерживать значительно большую степень загрузки чем шина SCSI, поскольку во встроенных дисковых контроллерах имеется интеллект и средства буферизации. Это позволяет координировать работу буферов дорожек, каретки диска и очереди запросов такими способами, которые не возможны на достаточно примитивных главных адаптерах шины SCSI.
Обычно невозможно оценить, какова будет средняя степень загрузки дисков или шины SCSI до тех пор, пока система не начнет работать. В результате, достаточно приемлемой оказывается такая конфигурация, которая позволяет распределить часто используемые данные и индексы по стольким дискам и шинам SCSI, сколько позволяют бюджет и технические ограничения. Для данных, доступ к которым происходит не очень часто, например, только во время ночной пакетной обработки (или других полуархивных данных подобных транзакциям годовой давности), можно рекомендовать как можно более плотную упаковку на накопителях.
Как только система начнет работать, можно измерить действительную степень загрузки дисков и соответствующим образом перераспределить данные. Как указывалось выше, перераспределение данных должно выполняться с учетом других параметров доступа к диску: везде надо поддерживать баланс.
В контексте СУБД имеется по крайней мере два механизма для распределения данных по дисковым накопителям. Для эффективного распределения доступа к данным все известные СУБД имеют возможность осуществлять конкатенацию нескольких дисковых накопителей или файлов UNIX. (В СУБД Ingres, например, реализовано истинное расщепление дисков, ограниченное стандартным размером чередования 16 Кбайт). Похожие возможности (помимо горячего резервирования и расщепления дисков) предлагают и специальные программные средства типа Online:DiskSuite. Если работа с таблицей ограничивается возможностями подсистемы ввода/вывода, следует исследовать запросы, которые вызывают ввод/вывод. Если эти запросы реализуют произвольный доступ к дискам, например, если многие пользователи независимо запрашивают индивидуальные записи, то имеющиеся возможности конкатенации дисков в СУБД полностью адекватны распределению нагрузки доступа по множеству дисков (при достаточно полном заполнении пространства таблицы). Если обращения по своей природе последовательны, например, если один или несколько пользователей должны просматривать каждую строку таблицы, то больше подходит механизм расщепления дисков.
Основное преимущество использования расщепления с помощью средств, подобных
Online:DiskSuite, заключается в том, что задача распределения обращений к данным становится гораздо более простой для администратора базы данных. При действительном расщеплении эта задача тривиальна и почти всегда дает оптимальные результаты. Часто это не тот случай, когда логически разделение данных по пространствам таблицы использует внутренние механизмы СУБД. Задача заключается в том, чтобы распределить тяжело используемые таблицы по отдельным дисковым ресурсам, однако часто невозможно принять решение относительно конфликтующих комбинаций запросов при обращениях к этим таблицам, приводящих к неровной нагрузке. При использовании
DiskSuite степень загруженности дисков сама будет стремиться к естественному уровню.
Обычно СУБД делят таблицу на несколько относительно больших сегментов и размещают данные равномерно по этим сегментам. Главное отличие между конкатенацией СУБД и функцией расщепления Online:DiskSuite заключается в размещении смежных данных. Когда диски конкатенируются друг с другом, последовательное сканирование представляет собой тяжелую нагрузку для каждого из дисков, но эта нагрузка носит последовательный характер (только один диск участвует в обслуживании запроса). Истинное расщепление дисков, реализованное в Online:DiskSuite, осуществляет деление данных по гораздо более мелким границам, позволяя тем самым всем дискам участвовать в обслуживании даже сравнительно небольшого запроса. Как результат, при использовании расщепления загрузка дисков при выполнении последовательного доступа существенно уменьшается. К архивным и журнальным файлам всегда осуществляется последовательный доступ и они являются хорошими кандидатами для расщепления, если реализация обращений к таким файлам ограничивает общую производительность системы.
По мере продолжения роста размеров и важности баз данных, процедуры резервного копирования, которые выполняются с блокировкой доступа к СУБД, становятся практически неприемлемыми. При реализации резервного копирования в оперативном режиме (режиме online) могут возникнуть достаточно сложные вопросы по конфигурированию соответствующих средств, поскольку резервное копирование больших томов данных, находящихся в базах данных, приводит к очень интенсивной работе подсистемы ввода/вывода. Резервное копирование в оперативном режиме часто вызывает очень высокий уровень загрузки дисков и шины SCSI, что приводит к низкой производительности приложений. Следует уделять особое внимание конфигурациям всех устройств, вовлеченных в процессы резервного копирования.
Рекомендации:
После начальной инсталляции необходимо наблюдать за работой системы и переразмещать данные до тех пор, пока каждый дисковый накопитель не будет загружен менее, чем на 60%. Для распределения последовательных дисковых обращений по множеству дисков рекомендуется использовать программные продукты типа Online:DiskSuite. Когда типовой доступ к диску носит характер произвольного обращения, для более равномерного распределения обращений к данным и уменьшения степени загрузки дисков следует использовать встроенную в СУБД функцию кокатенации. Особое внимание следует уделять влиянию резервного копирования в режиме online на работу системы, особенно на загрузку шины SCSI.Использование специфических свойств динамических ЗУПВ
Как упоминалось раньше, обращение к ДЗУПВ состоит из двух этапов: обращения к строке и обращения к столбцу. При этом внутри микросхемы осуществляется буферизация битов строки, прежде чем происходит обращение к столбцу. Размер строки обычно является корнем квадратным от емкости кристалла памяти: 1024 бита для 1Мбит, 2048 бит для 4 Мбит и т.д. С целью увеличения производительности все современные микросхемы памяти обеспечивают возможность подачи сигналов синхронизации, которые позволяют выполнять последовательные обращения к буферу без дополнительного времени обращения к строке. Имеются три способа подобной оптимизации:
блочный режим (nibble mode) - ДЗУВП может обеспечить выдачу четырех последовательных ячеек для каждого сигнала RAS. страничный режим (page mode) - Буфер работает как статическое ЗУПВ; при изменении адреса столбца возможен доступ к произвольным битам в буфере до тех пор, пока не поступит новое обращение к строке или не наступит время регенерации. режим статического столбца (static column) - Очень похож на страничный режим за исключением того, что не обязательно переключать строб адреса столбца каждый раз для изменения адреса столбца.Начиная с микросхем ДЗУПВ емкостью 1 Мбит, большинство ДЗУПВ допускают любой из этих режимов, причем выбор режима осуществляется на стадии установки кристалла в корпус путем выбора соответствующих соединений. Эти операции изменили определение длительности цикла памяти для ДЗУВП. На рисунке 3.24 показано традиционное время цикла и максимальная скорость между обращениями в оптимизированном режиме.
Преимуществом такой оптимизации является то, что она основана на внутренних схемах ДЗУПВ и незначительно увеличивает стоимость системы, позволяя практически учетверить пропускную способность памяти. Например, nibble mode был разработан для поддержки режимов, аналогичных расслоению памяти. Кристалл за один раз читает значения четырех бит и подает их наружу в течение четырех оптимизированных циклов. Если время пересылки по шине не превосходит время оптимизированного цикла, единственное усложнение для организации памяти с четырехкратным расслоением заключается в несколько усложненной схеме управления синхросигналами. Страничный режим и режим статического столбца также могут использоваться, обеспечивая даже большую степень расслоения при несколько более сложном управлении. Одной из тенденций в разработке ДЗУПВ является наличие в них буферов с тремя состояниями. Это предполагает, что для реализации традиционного расслоения с большим числом кристаллов памяти в системе должны быть предусмотрены буферные микросхемы для каждого банка памяти.
Новые поколения ДЗУВП разработаны с учетом возможности дальнейшей оптимизации интерфейса между ДЗУПВ и процессором. В качестве примера можно привести изделия компании RAMBUS. Эта компания берет стандартную начинку ДЗУПВ и обеспечивает новый интерфейс, делающий работу отдельной микросхемы более похожей на работу системы памяти, а не на работу отдельного ее компонента. RAMBUS отбросила сигналы RAS/CAS, заменив их шиной, которая допускает выполнение других обращений в интервале между посылкой адреса и приходом данных. (Такого рода шины называются шинами с пакетным переключением (packet-switched bus) или шинами с расщепленными транзакциями (split-traнсaction bus), которые будут рассмотрены в других главах. Такая шина позволяет работать кристаллу как отдельному банку памяти. Кристалл может вернуть переменное количество данных на один запрос и даже самостоятельно выполняет регенерацию. RAMBUS предлагает байтовый интерфейс и сигнал синхронизации, так что микросхема может тесно синхронизироваться с тактовой частотой процессора. После того, как адресный конвейер наполнен, отдельный кристалл может выдавать по байту каждые 2 нсек.
Большинство систем основной памяти используют методы, подобные страничному режиму ДЗУПВ, для уменьшения различий в производительности процессоров и микросхем памяти.
Использование зеркалирования дисков для облегчения резервного копирования
Простым, но эффективным способом сокращения времени резервного копирования является выполнение копирования на отдельный зеркальный диск. ПО Online:DiskSuite предлагает зеркалирование с очень небольшими накладными системными расходами. Если зеркальная копия сделана непосредственно после контрольной точки, или после того как база данных выключена, она действительно становится онлайновой дисковой резервной копией, которая сама может быть скопирована в любое удобное время. Можно даже выполнить рестарт базы данных, чтобы продолжить нормальную обработку, хотя с меньшей избыточностью. Если доступно достаточное количество дисковых накопителей, то может быть использован и второй набор зеркальных дисков, что позволяет сохранить полное зеркалирование даже, когда один набор зеркальных дисков отключается (во время нормальных операций диски будут зеркалироваться по трем направлениям). В этом случае резервное копирование в режиме online может продолжаться после копирования на ленту, что обеспечивает в случае необходимости очень быстрое восстановление. Этот дополнительный набор зеркальных дисков мог бы быть заново подключен перед следующей контрольной точкой, обеспечив достаточно времени (примерно 30 минут), которое позволит этому набору зеркальных дисков синхронизоваться с зеркальными дисками, работавшими в режиме online.
Эволюция архитектуры POWER в направлении архитектуры PowerPC
Компания IBM распространяет влияние архитектуры POWER в направлении малых систем с помощью платформы PowerPC. Архитектура POWER в этой форме может обеспечивать уровень производительности и масштабируемость, превышающие возможности современных персональных компьютеров. PowerPC базируется на платформе RS/6000 в дешевой конфигурации. В архитектурном плане основные отличия этих двух разработок заключаются лишь в том, что системы PowerPC используют однокристальную реализацию архитектуры POWER, изготавливаемую компанией Motorola, в то время как большинство систем RS/6000 используют многокристальную реализацию. Имеется несколько вариаций процессора PowerPC, обеспечивающих потребности портативных изделий и настольных рабочих станций, но это не исключает возможность применения этих процессоров в больших системах. Первым на рынке был объявлен процессор 601, предназначенный для использования в настольных рабочих станциях компаний IBM и Apple. За ним последовали кристаллы 603 для портативных и настольных систем начального уровня и 604 для высокопроизводительных настольных систем. Наконец, процессор 620 разработан специально для серверных конфигураций и ожидается, что со своей 64-битовой организацией он обеспечит исключительно высокий уровень производительности.
При разработке архитектуры PowerPC для удовлетворения потребностей трех различных компаний (Apple, IBM и Motorola) при сохранении совместимости с RS/6000, в архитектуре POWER было сделано несколько изменений в следующих направлениях:
упрощение архитектуры с целью ее приспособления ее для реализации дешевых однокристальных процессоров; устранение команд, которые могут стать препятствием повышения тактовой частоты; устранение архитектурных препятствий суперскалярной обработке и внеочередному выполнению команд; добавление свойств, необходимых для поддержки симметричной многопроцессорной обработки; добавление новых свойств, считающихся необходимыми для будущих прикладных программ; ясное определение линии раздела между "архитектурой" и "реализацией"; обеспечение длительного времени жизни архитектуры путем ее расширения до 64-битовой.Архитектура PowerPC поддерживает ту же самую базовую модель программирования и назначение кодов операций команд, что и архитектура POWER. В тех местах, где были сделаны изменения, которые могли потенциально препятствовать процессорам PowerPC выполнять существующие двоичные коды RS/6000, были расставлены "ловушки", обеспечивающие прерывание и эмуляцию с помощью программного обеспечения. Такие изменения вводились, естественно, только в тех случаях, если соответствующая возможность либо использовалась не очень часто в кодах прикладных программ, либо была изолирована в библиотечных программах, которые можно просто заменить.
Кэшпамять данных (Dкэш)
В процессоре UltraSPARC-1 используется кэш-память данных с прямым отображением емкостью 16 Кбайт, реализующая алгоритм сквозной записи. D-кэш организован в виде 512 строк, в каждой строке размещаются два 16-байтных подблока данных. С каждой строкой связан соответствующий адресный тег. D-кэш индексируется с помощью виртуального адреса, при этом теги также хранят соответствующую часть виртуального адреса. При возникновении промаха при обращении к кэшируемой ячейке памяти происходит загрузка 16-байтного подблока из основной памяти.
Поиск слова в D-кэше осуществляется с помощью виртуального адреса. Младшие разряды этого адреса обеспечивают доступ к строке кэш-памяти, содержащей требуемое слово (прямое отображение). Старшие разряды виртуального адреса сравниваются затем с битами соответствующего тега для определения попадания или промаха. Подобная схема гарантирует быстрое обнаружение промаха и обеспечивает преобразование виртуального адреса в физический только при наличии промаха.
Кэшпамять данных первого уровня
Кэш-память данных первого уровня процессора R10000 имеет емкость 32 Кбайт и организована в виде двух одинаковых банков емкостью по 16 Кбайт, что обеспечивает двухкратное расслоение при выполнении обращений к этой кэш-памяти. Каждый банк представляет собой двухканальную множественно-ассоциативную кэш-память с размером строки (блока) в 32 байта. Кэш данных индексируется с помощью виртуального адреса и хранит теги физических адресов памяти. Такой метод индексации позволяет выбрать подмножество кэш-памяти в том же такте, в котором формируется виртуальный адрес. Однако для того, чтобы поддерживать когерентность с кэш-памятью второго уровня, в кэше первого уровня хранятся теги физических адресов памяти.
Массивы данных и тегов в каждом банке являются независимыми. Эти четыре массива работают под общим управлением очереди формирования адресов памяти и схем внешнего интерфейса кристалла. В очереди адресов могут одновременно находиться до 16 команд загрузки и записи, которые обрабатываются в четырех отдельных конвейерах. Команды из этой очереди динамически выдаются для выполнения в специальный конвейер, который обеспечивает вычисление исполнительного виртуального адреса и преобразование этого адреса в физический. Три других параллельно работающих конвейера могут одновременно выполнять проверку тегов, осуществлять пересылку данных для команд загрузки и завершать выполнение команд записи в память. Хотя команды выполняются в строгом порядке их расположения в памяти, вычисление адресов и пересылка данных для команд загрузки могут происходить неупорядоченно. Схемы внешнего интерфейса кристалла могут выполнять заполнение или обратное копирование строк кэш-памяти, либо операции просмотра тегов. Такая параллельная работа большинства устройств процессора позволяет R10000 эффективно выполнять реальные многопроцессорные приложения.
Кэшпамять команд
Объем внутренней двухканальной множественно-ассоциативной кэш-памяти команд составляет 32 Кбайт. В процессе ее загрузки команды частично декодируются. При этом к каждой команде добавляются 4 дополнительных бит, которые указывают исполнительное устройство, в котором она будет выполняться. Таким образом, в кэш-памяти команды хранятся в 36-битовом формате. Размер строки кэш-памяти команд составляет 64 байта.
Классификация систем параллельной обработки данных
На протяжении всей истории развития вычислительной техники делались попытки найти какую-то общую классификацию, под которую подпадали бы все возможные направления развития компьютерных архитектур. Ни одна из таких классификаций не могла охватить все разнообразие разрабатываемых архитектурных решений и не выдерживала испытания временем. Тем не менее в научный оборот попали и широко используются ряд терминов, которые полезно знать не только разработчикам, но и пользователям компьютеров.
Любая вычислительная система (будь то супер-ЭВМ или персональный компьютер) достигает своей наивысшей производительности благодаря использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Именно возможность параллельной работы различных устройств системы (работы с перекрытием) является основой ускорения основных операций.
Параллельные ЭВМ часто подразделяются по классификации Флинна на машины типа SIMD (Single Instruction Multiple Data - с одним потоком команд при множественном потоке данных) и MIMD (Multiple Instruction Multiple Data - с множественным потоком команд при множественном потоке данных). Как и любая другая, приведенная выше классификация несовершенна: существуют машины прямо в нее не попадающие, имеются также важные признаки, которые в этой классификации не учтены. В частности, к машинам типа SIMD часто относят векторные процессоры, хотя их высокая производительность зависит от другой формы параллелизма - конвейерной организации машины. Многопроцессорные векторные системы, типа Cray Y-MP, состоят из нескольких векторных процессоров и поэтому могут быть названы MSIMD (Multiple SIMD).
Классификация Флинна не делает различия по другим важным для вычислительных моделей характеристикам, например, по уровню "зернистости" параллельных вычислений и методам синхронизации.
Можно выделить четыре основных типа архитектуры систем параллельной обработки:
1) Конвейерная и векторная обработка.
Основу конвейерной обработки составляет раздельное выполнение некоторой операции в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых операндов соответствует максимальной производительности конвейера. Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Векторные операции обеспечивают идеальную возможность полной загрузки вычислительного конвейера.
При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений на векторной машине состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы.
2) Машины типа SIMD. Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных.
В отличие от ограниченного конвейерного функционирования векторного процессора, матричный процессор (синоним для большинства SIMD-машин) может быть значительно более гибким. Обрабатывающие элементы таких процессоров - это универсальные программируемые ЭВМ, так что задача, решаемая параллельно, может быть достаточно сложной и содержать ветвления. Обычное проявление этой вычислительной модели в исходной программе примерно такое же, как и в случае векторных операций: циклы на элементах массива, в которых значения, вырабатываемые на одной итерации цикла, не используются на другой итерации цикла.
Модели вычислений на векторных и матричных ЭВМ настолько схожи, что эти ЭВМ часто обсуждаются как эквивалентные.
3) Машины типа MIMD. Термин "мультипроцессор" покрывает большинство машин типа MIMD и (подобно тому, как термин "матричный процессор" применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В мультипроцессорной системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других процессорных элементов. Процессорные элементы, конечно, должны как-то связываться друг с другом, что делает необходимым более подробную классификацию машин типа MIMD. В мультипроцессорах с общей памятью (сильносвязанных мультипроцессорах) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с локальной памятью) вся память делится между процессорными элементами и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом.
Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Существует большое количество вариантов этой модели. На одном конце спектра - модель распределенных вычислений, в которой программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм. На другом конце спектра - модель потоковых вычислений, в которых каждая операция в программе может рассматриваться как отдельный процесс. Такая операция ждет своих входных данных (операндов), которые должны быть переданы ей другими процессами. По их получении операция выполняется, и полученное значение передается тем процессам, которые в нем нуждаются. В потоковых моделях вычислений с большим и средним уровнем гранулярности, процессы содержат большое число операций и выполняются в потоковой манере.
4) Многопроцессорные машины с SIMD-процессорами.
Многие современные супер-ЭВМ представляют собой многопроцессорные системы, в которых в качестве процессоров используются векторные процессоры или процессоры типа SIMD. Такие машины относятся к машинам класса MSIMD.
Языки программирования и соответствующие компиляторы для машин типа MSIMD обычно обеспечивают языковые конструкции, которые позволяют программисту описывать "крупнозернистый" параллелизм. В пределах каждой задачи компилятор автоматически векторизует подходящие циклы. Машины типа MSIMD, как можно себе представить, дают возможность использовать лучший из этих двух принципов декомпозиции: векторные операции ("мелкозернистый" параллелизм) для тех частей программы, которые подходят для этого, и гибкие возможности MIMD-архитектуры для других частей программы.
Многопроцессорные системы за годы развития вычислительной техники претерпели ряд этапов своего развития. Исторически первой стала осваиваться технология SIMD. Однако в настоящее время наметился устойчивый интерес к архитектурам MIMD. Этот интерес главным образом определяется двумя факторами:
-
Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей.
Архитектура MIMD может использовать все преимущества современной микропроцессорной технологии на основе строгого учета соотношения стоимость/производительность. В действительности практически все современные многопроцессорные системы строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, соответствующим решаемым задачам. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти. В многопроцессорной системе с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика".
В архитектурах с локальной памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, основных сетей обмена и пропускной способности памяти и каналов обмена.
Часто, и притом необосновано, в машинах с общей памятью и векторных машинах затраты на обмен не учитываются, так как проблемы обмена в значительной степени скрыты от программиста. Однако накладные расходы на обмен в этих машинах имеются и определяются конфликтами шин, памяти и процессоров. Чем больше процессоров добавляется в систему, тем больше процессов соперничают при использовании одних и тех же данных и шины, что приводит к состоянию насыщения. Модель системы с общей памятью очень удобна для программирования и иногда рассматривается как высокоуровневое средство оценки влияния обмена на работу системы, даже если основная система в действительности реализована с применением локальной памяти и принципа передачи сообщений.
В сетях с коммутацией каналов и в сетях с коммутацией пакетов по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь межпроцессорный обмен связывает сетевые ресурсы: каналы, процессоры, буферы сообщений. Объем передаваемой информации может быть сокращен за счет тщательной функциональной декомпозиции задачи и тщательного диспетчирования выполняемых функций.
Таким образом, существующие MIMD-машины распадаются на два основных класса в зависимости от количества объединяемых процессоров, которое определяет и способ организации памяти и методику их межсоединений.
К первой группе относятся машины с общей (разделяемой) основной памятью, объединяющие до нескольких десятков (обычно менее 32) процессоров. Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров. Поскольку имеется единственная память с одним и тем же временем доступа, эти машины иногда называются UMA (Uniform Memory Access). Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным. Структура подобной системы представлена на Рисунок 3.28.
Когда необходимо выполнять резервное копирование?
Составить расписание для резервного копирования системы, которая используется главным образом в течение нормального рабочего времени, обычно сравнительно просто. Для выполнения процедур резервного копирования после завершения рабочего дня часто используются скрипты. В некоторых организациях эти процедуры выполняются автоматически даже без привлечения обслуживающего персонала, в других в неурочное время используют операторов. Для выполнения автоматического резервного копирования без привлечения обслуживающего персонала требуется возможность его проведения в рабочем режиме (режиме online).
Если система должна находиться в рабочем режиме 24 часа в сутки, или если время, необходимое для выполнения резервного копирования превышает размер доступного окна (временного интервала), то планирование операций резервного копирования и конфигурирование соответствующих средств значительно усложняются.
Концепция виртуальной памяти
Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений. Прежде всего к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем.
В любой момент времени компьютер выполняет множество процессов или задач, каждая из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче тем более, что многие задачи реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности. Она делит физическую память на блоки и распределяет их между различными задачами. При этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение.
Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объема. Если программа становилась слишком большой для физической памяти, часть ее необходимо было хранить во внешней памяти (на диске) и задача приспособить ее для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведенного ей пространства физической памяти. Виртуальная память освободила программистов от этого бремени. Она автоматически управляет двумя уровнями иерархии памяти: основной памятью и внешней (дисковой) памятью.
Кроме того, виртуальная память упрощает также загрузку программ, обеспечивая механизм автоматического перемещения программ, позволяющий выполнять одну и ту же программу в произвольном месте физической памяти.
Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами. Ниже рассмотрены оба типа организации виртуальной памяти.
Конфигурация клиент/сервер и региональные сети
В последнее время резко увеличилось число приложений, в которых фронтальные системы и серверы СУБД могут или должны размещаться в географически разнесенных местах. Такие системы должны соединяться между собой с помощью глобальных сетей. Обычно средой передачи данных для таких сетей являются арендованные линии с синхронными последовательными интерфейсами. Эти линии обычно работают со скоростями 56-64 Кбит/с, 1.5-2.0 Мбит/с и 45 Мбит/с. Хотя скорость передачи данных в такой среде значительно ниже, чем обычные скорости локальных сетей, подобных Ethernet, природа последовательных линий такова, что они могут поддерживать очень высокий уровень загрузки. Линия T1 предлагает пропускную способность 1.544 Мб/с (2.048 Мбит/с за пределами США). По сравнению с 3.5 Мбит/с, обеспечиваемых Ethernet в обычном окружении, линия T1 предлагает пропускную способность, которая количественно практически не отличается от Ethernet. Неполные линии T3 часто доступны со скоростями 10-20 Мбит/с, очевидно соперничая с сетями Ethernet и Token Ring. В ряде случаев можно найти приложения, которые могут работать успешно в конфигурации клиент/сервер даже через сеть со скоростью 56 Кбит/с.
Для традиционных бизнес-приложений трафик конфигурации клиент/сервер обычно содержит сравнительно низкий объем данных, пересылаемых между фронтальной системой и сервером СУБД, и для них более низкая пропускная способность сети может оказаться достаточной. В большинстве случаев задержка сети не является большой проблемой, однако если глобальная сеть имеет особенно большую протяженность, или если сама среда передачи данных имеет очень большую задержку (например, спутниковые каналы связи), приложение должно быть протестировано для определения его чувствительности к задержкам пакетов.
Для сокращения трафика клиент/сервер до абсолютного минимума могут использоваться мониторы обработки транзакций.
Конфликты по данным остановы конвейера и реализация механизма обходов
Одним из факторов, который оказывает существенное влияние на производительность конвейерных систем, являются межкомандные логические зависимости. Такие зависимости в большой степени ограничивают потенциальный параллелизм смежных операций, обеспечиваемый соответствующими аппаратными средствами обработки. Степень влияния этих зависимостей определяется как архитектурой процессора (в основном, структурой управления конвейером команд и параметрами функциональных устройств), так и характеристиками программ.
Конфликты по данным возникают в том случае, когда применение конвейерной обработки может изменить порядок обращений за операндами так, что этот порядок будет отличаться от порядка, который наблюдается при последовательном выполнении команд на неконвейерной машине. Рассмотрим конвейерное выполнение последовательности команд на рисунке 3.4.
В этом примере все команды, следующие за командой ADD, используют результат ее выполнения. Команда ADD записывает результат в регистр R1, а команда SUB читает это значение. Если не предпринять никаких мер для того, чтобы предотвратить этот конфликт, команда SUB прочитает неправильное значение и попытается его использовать. На самом деле значение, используемое командой SUB, является даже неопределенным: хотя логично предположить, что SUB всегда будет использовать значение R1, которое было присвоено какой-либо командой, предшествовавшей ADD, это не всегда так. Если произойдет прерывание между командами ADD и SUB, то команда ADD завершится, и значение R1 в этой точке будет соответствовать результату ADD. Такое непрогнозируемое поведение очевидно неприемлемо.
| ADD | R1,R2,R3 | IF | ID | EX | MEM | WB | |||||
| SUB | R4,R1,R5 | IF | ID | EX | MEM | WB | |||||
| AND | R6,R1,R7 | IF | ID | EX | MEM | WB | |||||
| OR | R8,R1,R9 | IF | ID | EX | MEM | WB | |||||
| XOR | R10,R1,R11 | IF | ID | EX | MEM | WB |
Конфликты по данным приводящие к приостановке конвейера
К сожалению не все потенциальные конфликты по данным могут обрабатываться с помощью механизма "обходов". Рассмотрим следующую последовательность команд (рисунок 3.5):
| Команда | ||||||||||
| LW R1,32(R6) | IF | ID | EX | MEM | WB | |||||
| ADD R4,R1,R7 | IF | ID | stall | EX | MEM | WB | ||||
| SUB R5,R1,R8 | IF | stall | ID | EX | MEM | WB | ||||
| AND R6,R1,R7 | stall | IF | ID | EX | MEM | WB |
Конвейерное выполнение оператора А = В + С
Очевидно, выполнение команды ADD должно быть приостановлено до тех пор, пока не станет доступным поступающий из памяти операнд C. Дополнительной задержки выполнения команды SW не произойдет в случае применения цепей обхода для пересылки результата операции АЛУ непосредственно в регистр данных памяти для последующей записи.
Для данного простого примера компилятор никак не может улучшить ситуацию, однако в ряде более общих случаев он может реорганизовать последовательность команд так, чтобы избежать приостановок конвейера. Эта техника, называемая планированием загрузки конвейера (pipeline scheduling) или планированием потока команд (instruction scheduling), использовалась начиная с 60-х годов и стала особой областью интереса в 80-х годах, когда конвейерные машины стали более распространенными.
Пусть, например, имеется последовательность операторов: a = b + c; d = e - f;
Как сгенерировать код, не вызывающий остановок конвейера? Предполагается, что задержка загрузки из памяти составляет один такт. Ответ очевиден (рисунок 3.7):
| Неоптимизированная последовательность команд |
Оптимизированная последовательность команд |
| LW Rb,b | LW Rb,b |
| LW Rc,c | LW Rc,c |
| ADD Ra,Rb,Rc | LW Re,e |
| SW a,Ra | ADD Ra,Rb,Rc |
| LW Re,e | LW Rf,f |
| LW Rf,f | SW a,Ra |
| SUB Rd,Re,Rf | SUB Rd,Re,Rf |
| SW d,Rd | SW d,Rd |
Магнитные и магнитооптические диски
В данном разделе мы кратко рассмотрим основную терминологию, применяемую при описании магнитных дисков и контроллеров, а затем приведем типовые характеристики нескольких современных дисковых подсистем.
Дисковый накопитель обычно состоит из набора пластин, представляющих собой металлические диски, покрытые магнитным материалом и соединенные между собой при помощи центрального шпинделя. Для записи данных используются обе поверхности пластины. В современных дисковых накопителях используется от 4 до 9 пластин. Шпиндель вращается с высокой постоянной скоростью (обычно 3600, 5400 или 7200 оборотов в минуту). Каждая пластина содержит набор концентрических записываемых дорожек. Обычно дорожки делятся на блоки данных объемом 512 байт, иногда называемые секторами. Количество блоков, записываемых на одну дорожку зависит от физических размеров пластины и плотности записи.
Данные записываются или считываются с пластин с помощью головок записи/считывания, по одной на каждую поверхность. Линейный двигатель представляет собой электро-механическое устройство, которое позиционирует головку над заданной дорожкой. Обычно головки крепятся на кронштейнах, которые приводятся в движение каретками. Цилиндр - это набор дорожек, соответствующих одному положению каретки. Накопитель на магнитных дисках (НМД) представляет собой набор пластин, магнитных головок, кареток, линейных двигателей плюс воздухонепроницаемый корпус. Дисковым устройством называется НМД с относящимися к нему электронными схемами.
Производительность диска является функцией времени обслуживания, которое включает в себя три основных компонента: время доступа, время ожидания и время передачи данных. Время доступа - это время, необходимое для позиционирования головок на соответствующую дорожку, содержащую искомые данные. Оно является функцией затрат на начальные действия по ускорению головки диска (порядка 6 мс), а также функцией числа дорожек, которые необходимо пересечь на пути к искомой дорожке. Характерные средние времена поиска - время, необходимое для перемещения головки между двумя случайно выбранными дорожками, лежат в диапазоне 10-20 мс. Время перехода с дорожки на дорожку меньше 10 мс и обычно составляет 2 мс.
Вторым компонентом времени обслуживания является время ожидания. Чтобы искомый сектор повернулся до совмещения с положением головки требуется некоторое время. После этого данные могут быть записаны или считаны. Для современных дисков время полного оборота лежит в диапазоне 8-16 мс, а среднее время ожидания составляет 4-8 мс.
Последним компонентом является время передачи данных, т.е. время, необходимое для физической передачи байтов. Время передачи данных является функцией от числа передаваемых байтов (размера блока), скорости вращения, плотности записи на дорожке и скорости электроники. Типичная скорость передачи равна 1-4 Мбайт/с.
В состав компьютеров часто входят специальные устройства, называемые дисковыми контроллерами. К каждому дисковому контроллеру может подключаться несколько дисковых накопителей. Между дисковым контроллером и основной памятью может быть целая иерархия контроллеров и магистралей данных, сложность которой определяется главным образом стоимостью компьютера. Поскольку время передачи часто составляет очень небольшую часть общего времени доступа к диску, контроллер в высокопроизводительной системе разъединяет магистрали данных от диска на время позиционирования так, что другие диски, подсоединенные к контроллеру, могут передавать свои данные в основную память. Поэтому время доступа к диску может увеличиваться на время, связанное с накладными расходами контроллера на организацию операции ввода/вывода.
Рассмотрим теперь основные составляющие времени доступа к диску в типичной подсистеме SCSI. Такая подсистема включает в себя четыре основных компонента: основной компьютер, главный адаптер SCSI, встроенный в дисковое устройство контроллер и собственно накопитель на магнитных дисках. Когда операционная система получает запрос от пользователя на выполнение операции ввода/вывода, она превращает этот запрос в набор команд SCSI. Запрашивающий процесс при этом блокируется и откладывается до завершения операции ввода/вывода (если только это был не запрос асинхронной передачи данных). Затем команды пересылаются по системе шин в главный адаптер SCSI, к которому подключен необходимый дисковый накопитель. После этого ответственность за выполнение взаимодействия с целевыми контроллерами и их устройствами ложится на главный адаптер.
Затем главный адаптер выбирает целевое устройство, устанавливая сигнал на линии управления шины SCSI (эта операция называется фазой выбора). Естественно, шина SCSI должна быть доступна для этой операции. Если целевое устройство возвращает ответ, то главный адаптер пересылает ему команду (это называется фазой команды). Если целевой контроллер может выполнить команду немедленно, то он пересылает в главный адаптер запрошенные данные или состояние. Команда может быть обслужена немедленно, только если это запрос состояния, или команда запрашивает данные, которые уже находятся в кэш-памяти целевого контроллера. Обычно же данные не доступны, и целевой контроллер выполняет разъединение, освобождая шину SCSI для других операций. Если выполняется операция записи, то за фазой команды на шине немедленно следует фаза данных, и данные помещаются в кэш-память целевого контроллера. Подтверждение записи обычно не происходит до тех пор, пока данные действительно не запишутся на поверхность диска.
После разъединения, целевой контроллер продолжает свою собственную работу. Если в нем не предусмотрены возможности буферизации команд (создание очереди команд), ему надо только выполнить одну команду. Однако, если создание очереди команд разрешено, то команда планируется в очереди работ целевого контроллера, при этом обрабатывается команда, обладающая наивысшим приоритетом в очереди. Когда запрос станет обладать наивысшим приоритетом, целевой контроллер должен вычислить физический адрес (или адреса), необходимый для обслуживания операции ввода/вывода. После этого становится доступным дисковый механизм: позиционируется каретка, подготавливается соответствующая головка записи/считывания и вычисляется момент появления данных под головкой. Наконец, данные физически считываются или записываются на дорожку. Считанные данные запоминаются в кэш-памяти целевого контроллера. Иногда целевой контроллер может выполнить считывание с просмотром вперед.
После завершения операции ввода/вывода целевой контроллер в случае свободы шины соединяется с главным адаптером, вслед за чем выполняется фаза данных (при передаче данных из целевого контроллера в главный адаптер) и фаза состояния для указания результата операции. Когда главный адаптер получает фазу состояния, он проверяет корректность завершения физической операции в целевом контроллере и соответствующим образом информирует операционную систему.
Одной из характеристик процесса ввода/вывода SCSI является большое количество шагов, которые обычно не видны пользователю. Обычно на шине SCSI происходит смена семи фаз (выбор, команда, разъединение, повторное соединение, данные, состояние, разъединение). Естественно каждая фаза выполняется за некоторое время, расходуемое на использование шины. Многие целевые контроллеры (особенно медленные устройства подобные магнитным лентам и компакт-дискам) потребляют значительную часть времени на реализацию фаз выбора, разъединения и повторного соединения.
Варианты применения высокопроизводительных подсистем ввода/вывода широко варьируются в зависимости от требований, которые к ним предъявляются. Они охватывают диапазон от обработки малого числа больших массивов данных, которые необходимо реализовать с минимальной задержкой (ввод/вывод суперкомпьютера), до большого числа простых заданий, которые оперируют с малыми объемами данных (обработка транзакций).
Запросы на ввод/вывод заданной рабочей нагрузки можно характеризовать в терминах трех метрик: производительность, время ожидания и пропускная способность. Производительность определяется числом запросов на обслуживание, получаемых в единицу времени. Время ожидания определяет время, необходимое на обслуживание индивидуального запроса. Пропускная способность определяет количество данных, передаваемых между устройствами, требующими обслуживания, и устройствами, выполняющими обслуживание.
Ввод/вывод суперкомпьютера почти полностью определяется последовательным механизмом. Обычно данные передаются с диска в память большими блоками, а результаты записываются обратно на диск. В таких применениях требуется высокая пропускная способность и минимальное время ожидания, однако они характеризуются низкой производительностью. В отличие от этого обработка транзакций характеризуется огромным числом случайных обращений, относительно небольшими отрезками работы и требует умеренного времени ожидания при очень высокой производительности.
Так как системы обработки транзакций тратят большую часть времени обслуживания на поиск и ожидание, технологические успехи, приводящие к сокращению времени передачи, не будут оказывать особого влияния на производительность таких систем. С другой стороны, в научных применениях на поиск данных и на их передачу затрачивается одинаковое время, и поэтому производительность таких систем оказывается очень чувствительной к любым усовершенствованиям в технологии изготовления дисков. Как будет показано ниже, можно организовать матрицу дисков таким образом, что будет обеспечена высокая производительность ввода/вывода для широкого спектра рабочих нагрузок.
В последние годы плотность записи на жестких магнитных дисках увеличивается на 60% в год при ежеквартальном снижении стоимости хранения одного Мегабайта на 12%. По данным фирмы Dataquest такая тенденция сохранится и в ближайшие два года. Сейчас на рынке представлен широкий ассортимент дисковых накопителей емкостью до 9.1 Гбайт. При этом среднее время доступа у самых быстрых моделей достигает 8 мс. Например, жесткий диск компании Seagate Technology имеет емкость 4.1 Гбайт и среднее время доступа 8 мс при скорости вращения 7200 оборот/мин. Улучшаются также характеристики дисковых контроллеров на базе новых стандартов Fast SCSI-2 и Enhanced IDE. Предполагается увеличение скорости передачи данных до 13 Мбайт/с. Надежность жестких дисков также постоянно улучшается. Например, некоторые модели дисков компаний Conner Peripherals Inc., Micropolis Corp. и Hewlett-Packard имеют время наработки на отказ от 500 тысяч до 1 миллиона часов. На такие диски предоставляется 5-летняя гарантия.
Дальнейшее повышение надежности и коэффициента готовности дисковых подсистем достигается построением избыточных дисковых массивов RAID, о которых речь пойдет в подразделе 3.3.2.3.
Другим направлением развития систем хранения информации являются магнитооптические диски. Запись на магнитооптические диски (МО-диски) выполняется при взаимодействии лазера и магнитной головки. Луч лазера разогревает до точки Кюри (температуры потери материалом магнитных свойств) микроскопическую область записывающего слоя, которая при выходе из зоны действия лазера остывает, фиксируя магнитное поле, наведенное магнитной головкой. В результате данные, записанные на диск, не боятся сильных магнитных полей и колебаний температуры. Все функциональные свойства дисков сохраняются в диапазоне температур от -20 до +50 градусов Цельсия.
МО-диски уступают обычным жестким магнитным дискам лишь по времени доступа к данным. Предельное достигнутое МО-дисками время доступа составляет 19 мс. Магнитооптический принцип записи требует предварительного стирания данных перед записью, и соответственно, дополнительного оборота МО-диска. Однако завершенные недавно исследования в SONY и IBM показали, что это ограничение можно устранить, а плотность записи на МО-дисках можно увеличить в несколько раз. Во всех других отношениях МО-диски превосходят жесткие магнитные диски.
В магнитооптическом дисководе используются сменные диски, что обеспечивает практически неограниченную емкость. Стоимость хранения единицы данных на МО-дисках в несколько раз меньше стоимости хранения того же объема данных на жестких магнитных дисках.
Сегодня на рынке МО-дисков предлагается более 150 моделей различных фирм. Одно из лидирующих положений на этом рынке занимает компания Pinnacle Micro Inc. Для примера, ее дисковод Sierra 1.3 Гбайт обеспечивает среднее время доступа 19 мс и среднее время наработки на отказ 80000 часов. Для серверов локальных сетей и рабочих станций компания Pinnacle Micro предлагает целый спектр многодисковых систем емкостью 20, 40, 120, 186 Гбайт и даже 4 Тбайт. Для систем высокой готовности Pinnacle Micro выпускает дисковый массив Array Optical Disk System, который обеспечивает эффективное время доступа к данным не более 11 мс при скорости передачи данных до 10 Мбайт/с.
Масштабируемая архитектура UPA
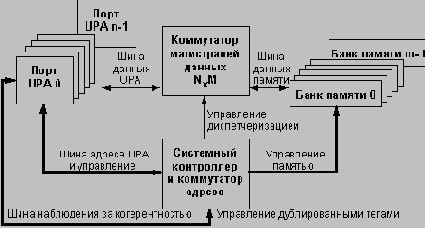
Отход от традиционных методов построения мультипроцессорных систем, основанных на наблюдаемой шине или на справочнике, позволяет существенно минимизировать задержки доступа к данным благодаря сокращению потерь на обработку промахов кэш-памяти. В итоге архитектура межсоединений UPA позволяет полностью использовать высокую пропускную способность процессора UltraSPARC-1. Максимальная скорость передачи данных составляет 1.3 Гбайт/с при работе UPA на тактовой частоте 83 МГц.
Разработчики архитектуры UPA многое сделали с целью минимизации задержек доступа к данным. Например, UPA поддерживает раздельные шины адреса и данных. Именно эти широкие шины (адресная шина имеет ширину 64 бит (в соответствии со спецификацией 64-битовой архитектуры V9), а шина данных - 144 бит (128 бит данных и 16 бит для контроля ошибок)) обеспечивают пиковую пропускную способность системы. Наличие отдельных шин позволяет устранить задержки, возникающие при переключении разделяемой шины между данными и адресом, а также возможные конфликты доступа к общей шине.
UPA не только поддерживает отдельные шины адреса и данных, но позволяет также иметь несколько шин с организацией соединений точка-точка. Обычно в большинстве систем имеются несколько интерфейсов для обеспечения работы подсистемы ввода/вывода, графической подсистемы и процессора. В мультипроцессорных системах требуются также дополнительные интерфейсы для организации связи между несколькими ЦП. Вместо одного набора шин данных и адреса для всех этих интерфейсов UPA допускает создание неограниченного количества шин.
Подобная организация имеет ряд достоинств. Наличие нескольких наборов шин позволяет минимизировать количество циклов арбитража и уменьшает вероятность конфликтов. Системный контроллер несет ответственность за работу и взаимодействие различных шин и может параллельно обрабатывать запросы нескольких шин. Он позволяет также уменьшить задержки, связанные с захватом шины. По существу, наличие нескольких шин адреса и данных означает меньшее число потенциальных главных устройств на каждом наборе шин. Для обеспечения наименьшей возможной задержки захвата шины используется распределенный конвейеризованный протокол арбитража. Каждый порт UPA имеет собственные схемы арбитража, при этом каждый порт в системе видит запросы шины всех других портов. Такая схема также позволяет уменьшить задержку доступа и обеспечивает увеличение общей производительности системы.
Архитектура UPA легко адаптируется для работы почти с любой конфигурацией системы (от однопроцессорной до массивно-параллельной). Разработчиками были предприняты специальные усилия с целью ее оптимизации для систем, содержащих от 1 до 4 процессоров. В результате до четырех тесно связанных процессоров и системный контроллер могут разделять доступ к одной и той же системной адресной шине. Однако на базе богатого набора транзакций и протокола когерентности, которые поддерживаются устройством интерфейса памяти процессора UltraSPARC-1 могут быть построены мультипроцессорные системы с большим количеством процессоров. В архитектуре UPA применяется протокол когерентности, построенный на основе операций записи с аннулированием соответствующих копий блока в кэш-памяти других процессоров системы и использующий для наблюдения дублированные теги. Процессор UltraSPARC поддерживает переходы состояний блоков кэш-памяти, соответствующие протоколам MOESI, MOSI и MSI.
Следует отметить, что в основу архитектуры UPA положены настолько гибкие принципы, что она позволяет иметь в системе не только несколько шин (мультиплексированных или раздельных), но и в широких пределах варьировать разрядность шины данных для удовлетворения различных требований к отношению стоимость/производительность. При этом в различных частях системы в зависимости от конкретных требований может использоваться разная скорость передачи данных. Например, разрядность шины данных системы ввода/вывода вполне может быть ограничена 64 битами, но для согласования с интерфейсом процессора более предпочтительна разрядность в 128 бит. С другой стороны, разрядность шины данных оперативной памяти системы может быть еще более увеличена для обеспечения высокой пропускной способности при использовании более медленных, но более дешевых микросхем памяти (в младших моделях компьютеров на базе микропроцессора UltraSPARC-1 используется 256-битовая шина данных памяти, а в старших моделях - 512-битовая).
Матричный коммутатор ССA2 сдвоенный
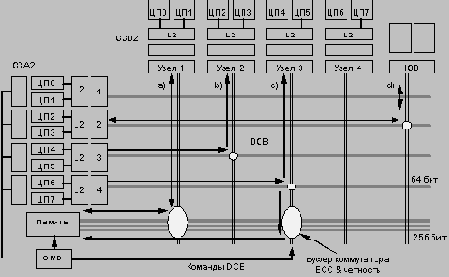
Процессорный узел или узел в/в коммутируется с массивом памяти (MA). Такое соединение используется для организации операций чтения памяти или записи в память.
Режим вмешательства (чтение): (b)
Читающий узел коммутируется с другим узлом (вмешивающимся узлом) и шиной данных MA. Этот режим используется тогда, когда при выполнении операции чтения строки от механизма наблюдения за когерентным состоянием памяти поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются читающему узлу и одновременно записываются в MA. Если читающий и вмешивающийся ЦП находятся внутри одного и того же узла, то данные заворачиваются назад на уровне узла и одновременно записываются в память.
Режим вмешательства (чтение с намерением модификации - RWITM):(c)
Процессорный узел или узел в/в (читающий узел) коммутируется с другим процессорным узлом или узлом в/в. Этот режим используется тогда, когда при выполнении операция RWITM от механизма наблюдения поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются только читающему узлу и не записываются в память.
Режим программируемого ввода/вывода (PIO): (d)
Процессорный узел коммутируется с узлом в/в. Это случай операций PIO, при котором данные обмениваются только между процессором и узлом в/в.
Режим в/в с отображением в памяти (memory mapped):
Главный узел коммутируется с узлами в/в (подчиненными узлами), вовлеченными в транзакцию. Это случай операций с памятью.
Метаданные СУБД
Обычно пользователи рассматривают СУБД как средство хранения и последующего поиска своих данных и вовсе не задумываются о том, что же в действительности хранится на диске. На практике, программное обеспечение СУБД поддерживает значительное количество дополнительной информации. Было бы серьезной ошибкой предполагать, что для размещения заданного количества данных пользователя потребуется тот же самый объем дискового пространства. Схема базы данных, табличные индексы, B-деревья узлов каталогов, временные таблицы, заранее выделенное пространство для хеш-таблиц и индексов, пространство для сортировки, файлы журнала, архивы и мириады других функций - все это включается в дисковое пространство системы.
Если отсутствует более точная информация, то обычно разумно было бы предусмотреть примерно удвоенный объем дискового пространства по сравнению с объемом "чистых" данных. Это обеспечивает некоторую гибкость для создания индексов и т.п., и в итоге позволяет улучшить производительности приложения. Хотя коэффициент 2 на первый взгляд кажется чрезмерным, следует, например, иметь в виду, что индексация, навязываемая предложенным тестом TPC-D потребляет более 400 Мб. При этом объем "чистых" данных составляет примерно 650 Мб. При использовании устанавливаемых по умолчанию параметров памяти СУБД Oracle, объем "чистых" данных, необходимых для реализации теста TPC-C, увеличивается на 30% при хранении их в базе данных Oracle даже без индексации. Поэтому можно легко потребовать для системы даже гораздо больше, чем 100% дополнительного пространства.
Рекомендации:
Объем дискового пространства базы данных должен по крайней мере на 50% превышать требования по объему "чистых" данных (к этому необходимо добавить накладные расходы файловой системы, если таковая применяется). Более безопасная цифра - 100%. Для размещения журналов транзакций и архивов необходимо выделить отдельное дисковое пространство. Его объем следует оценить отдельно, поскольку они должны размещаться на других физических дисках, чем сама база данных.Методика планирования компилятора для устранения конфликтов по данным
Многие типы приостановок конвейера могут происходить достаточно часто. Например, для оператора А = B + С компилятор скорее всего сгенерирует следующую последовательность команд (рисунок 3.6):
| LW R1,В | IF | ID | EX | MEM | WB | ||||
| LW R2,С | IF | ID | EX | MEM | WB | ||||
| ADD R3,R1,R2 | IF | ID | stall | EX | MEM | WB | |||
| SW A,R3 | IF | stall | ID | EX | MEM | WB |
MicroSPARCII
Эффективная с точки зрения стоимости конструкция не может полагаться только на увеличение тактовой частоты. Экономические соображения заставляют принимать решения, основой которых является массовая технология. Системы microSPARC обеспечивают высокую производительность при умеренной тактовой частоте путем оптимизации среднего количества команд, выполняемых за один такт. Это ставит вопросы эффективного управления конвейером и иерархией памяти. Среднее время обращения к памяти должно сокращаться, либо должно возрастать среднее количество команд, выдаваемых для выполнения в каждом такте, увеличивая производительность на основе компромиссов в конструкции процессора.
MicroSPARC-II (рисунок 5.6) является одним из сравнительно недавно появившихся процессоров семейства SPARC. Основное его назначение - однопроцессорные низкостоимостные системы. Он представляет собой высокоинтегрированную микросхему, содержащую целочисленное устройство, устройство управления памятью, устройство плавающей точки, раздельную кэш-память команд и данных, контроллер управления микросхемами динамической памяти и контроллер шины SBus.
Многопроцессорные системы с локальной памятью и многомашинные системы
Существуют два различных способа построения крупномасштабных систем с распределенной памятью. Простейший способ заключается в том, чтобы исключить аппаратные механизмы, обеспечивающие когерентность кэш-памяти, и сосредоточить внимание на создании масштабируемой системы памяти. Несколько компаний разработали такого типа машины. Наиболее известным примером такой системы является компьютер T3D компании Cray Research. В этих машинах память распределяется между узлами (процессорными элементами) и все узлы соединяются между собой посредством того или иного типа сети. Доступ к памяти может быть локальным или удаленным. Специальные контроллеры, размещаемые в узлах сети, могут на основе анализа адреса обращения принять решение о том, находятся ли требуемые данные в локальной памяти данного узла, или размещаются в памяти удаленного узла. В последнем случае контроллеру удаленной памяти посылается сообщение для обращения к требуемым данным.
Чтобы обойти проблемы когерентности, разделяемые (общие) данные не кэшируются. Конечно, с помощью программного обеспечения можно реализовать некоторую схему кэширования разделяемых данных путем их копирования из общего адресного пространства в локальную память конкретного узла. В этом случае когерентностью памяти также будет управлять программное обеспечение. Преимуществом такого подхода является практически минимальная необходимая поддержка со стороны аппаратуры, хотя наличие, например, таких возможностей как блочное (групповое) копирование данных было бы весьма полезным. Недостатком такой организации является то, что механизмы программной поддержки когерентности подобного рода кэш-памяти компилятором весьма ограничены. Существующая в настоящее время методика в основном подходит для программ с хорошо структурированным параллелизмом на уровне программного цикла.
Машины с архитектурой, подобной Cray T3D, называют процессорами (машинами) с массовым параллелизмом (MPP Massively Parallel Processor). К машинам с массовым параллелизмом предъявляются взаимно исключающие требования. Чем больше объем устройства, тем большее число процессоров можно расположить в нем, тем длиннее каналы передачи управления и данных, а значит и меньше тактовая частота. Происшедшее возрастание нормы массивности для больших машин до 512 и даже 64К процессоров обусловлено не ростом размеров машины, а повышением степени интеграции схем, позволившей за последние годы резко повысить плотность размещения элементов в устройствах. Топология сети обмена между процессорами в такого рода системах может быть различной. На Рисунок 3.32 приведены характеристики сети обмена для некоторых коммерческих MPP.
Для построения крупномасштабных систем альтернативой рассмотренному в предыдущем разделе протоколу наблюдения может служить протокол на основе справочника, который отслеживает состояние кэшей. Такой подход предполагает, что логически единый справочник хранит состояние каждого блока памяти, который может кэшироваться. В справочнике обычно содержится информация о том, в каких кэшах имеются копии данного блока, модифицировался ли данный блок и т.д. В существующих реализациях этого направления справочник размещается рядом с памятью. Имеются также протоколы, в которых часть информации размещается в кэш-памяти. Положительной стороной хранения всей информации в едином справочнике является простота протокола, связанная с тем, что вся необходимая информация сосредоточена в одном месте. Недостатком такого рода справочников является его размер, который пропорционален общему объему памяти, а не размеру кэш-памяти. Это не составляет проблемы для машин, состоящих, например, из нескольких сотен процессоров, поскольку связанные с реализацией такого справочника накладные расходы можно преодолеть. Но для машин большего размера необходима методика, позволяющая эффективно масштабировать структуру справочника.
| Фирма | Название | Коли-чество узлов | Базовая тополо-гия | Разряд-ность связи (бит) | Частота синхро-низации (Мгц) | Пиковая полоса пропус-кания связи (Мбайт/с) | Общая полоса пропускания (Мбайт/с) | Год выпуска |
| Thinking Machines | CM-2 | 1024-4096 | 12-мер-ный куб | 1 | 7 | 1 | 1024 | 1987 |
| nCube | nCube/ten | 1-1024 | 10-мер-ный куб | 1 | 10 | 1.2 | 640 | 1987 |
| Intel | iPSC/2 | 16-128 | 7-мерный куб | 1 | 16 | 2 | 345 | 1988 |
| Maspar | MP-1216 | 32-512 | 2-мерная сеть+сту-пенчатая Omega | 1 | 25 | 3 | 1300 | 1989 |
| Intel | Delta | 540 | 2-мерная сеть | 16 | 40 | 40 | 640 | 1991 |
| Thinking Machines | CM-5 | 32-2048 | многосту-пенчатое толстое дерево | 4 | 40 | 20 | 10240 | 1991 |
| Meiko | CS-2 | 2-1024 | многосту-пенчатое толстое дерево | 8 | 70 | 50 | 50000 | 1992 |
| Intel | Paragon | 4-1024 | 2-мерная сеть | 16 | 100 | 200 | 6400 | 1992 |
| Cray Research |
T3D | 16-1024 | 3-мерный тор | 16 | 150 | 300 | 19200 | 1993 |
Многопроцессорные системы с общей памятью
Требования, предъявляемые современными процессорами к полосе пропускания памяти можно существенно сократить путем применения больших многоуровневых кэшей. Тогда, если эти требования снижаются, то несколько процессоров смогут разделять доступ к одной и той же памяти. Начиная с 1980 года эта идея, подкрепленная широким распространением микропроцессоров, стимулировала многих разработчиков на создание небольших мультипроцессоров, в которых несколько процессоров разделяют одну физическую память, соединенную с ними с помощью разделяемой шины. Из-за малого размера процессоров и заметного сокращения требуемой полосы пропускания шины, достигнутого за счет возможности реализации достаточно большой кэш-памяти, такие машины стали исключительно эффективными по стоимости. В первых разработках подобного рода машин удавалось разместить весь процессор и кэш на одной плате, которая затем вставлялась в заднюю панель, с помощью которой реализовывалась шинная архитектура. Современные конструкции позволяют разместить до четырех процессоров на одной плате. На Рисунок 3.28 показана схема именно такой машины.
В такой машине кэши могут содержать как разделяемые, так и частные данные. Частные данные - это данные, которые используются одним процессором, в то время как разделяемые данные используются многими процессорами, по существу обеспечивая обмен между ними. Когда кэшируется элемент частных данных, их значение переносится в кэш для сокращения среднего времени доступа, а также требуемой полосы пропускания. Поскольку никакой другой процессор не использует эти данные, этот процесс идентичен процессу для однопроцессорной машины с кэш-памятью. Если кэшируются разделяемые данные, то разделяемое значение реплицируется и может содержаться в нескольких кэшах. Кроме сокращения задержки доступа и требуемой полосы пропускания такая репликация данных способствует также общему сокращению количества обменов. Однако кэширование разделяемых данных вызывает новую проблему: когерентность кэш-памяти.
Эти системы представляют собой компактные
Эти системы представляют собой компактные серверы в конструктиве напольной тумбы. Они базируются на технологиях PowerPC и MicroChannel. В модели С10 применяется микропроцессор 80 МГц PowerPC 601, а в модели С20 - более мощный микропроцессор 120 МГц PowerPC 604. В обеих системах для увеличения производительности оперативной обработки транзакций предусмотрена возможность установки кэш-памяти второго уровня емкостью 1 Мбайт. Оперативная память, защищенная кодами ECC, может расширяться от 16 до 256 Мбайт, емкость внутренних дисков может достигать 6.6 Гбайт, а при использовании внешних накопителей - 654 Гбайт.
4 гнезда расширения MicroChannel (3 - в модели C10) обеспечивают подключение широкой номенклатуры адаптеров и периферийных устройств. Серверы работают под управлением ОС AIX версий 3.2.5 и 4, которая обеспечивает возможность эксплуатации большинства приложений, разработанных для других систем RS/6000 (построенных на базе процессоров POWER, POWER2 и PowerPC). Компания IBM рекомендует использовать эти системы в небольших компаниях в качестве сетевых серверов, а также в больших корпорациях в качестве серверов рабочих групп и отделов для реализации серверов приложений.
Модель G40 считается системой начального
Модель G40 считается системой начального уровня среди симметричных мультипроцессорных систем, предлагаемых компанией IBM. Она может включать от 1 до 4 процессоров PowerPC 604, оснащаться оперативной памятью объемом 64 Мбайт - 1 Гбайт, кэш-памятью второго уровня емкостью 512 Кбайт на каждый процессор (микропроцессор PPC 604 имеет встроенные раздельные кэши первого уровня для команд и данных объемом по 16 Кбайт). Для снижения задержек и увеличения пропускной способности подсистемы памяти IBM применяет архитектуру неблокируемого коммутатора данных. Максимальная полоса пропускания подсистемы памяти составляет 1.8 Гбайт/с.
В состав системы входит специальный сервисный процессор IBM SystemGuard, который постоянно наблюдает за состоянием системы, обеспечивает выполнение локальной и удаленной диагностики системы и поддерживает процессы реконфигурации системы в случае проявления неисправностей. Сервисный процессор выполняет рутинные операции по обслуживанию системы: включение и выключение питания, выполнение диагностических процедур и поддержку системной консоли. При обнаружении каких-либо проблем сервисный процессор выполняет необходимые действия по автоматическому восстановлению системы. Если по каким-либо причинам систему не удается перезапустить, SystemGuard может автоматически связаться с сервисными службами IBM.
Система поддерживает два высокоскоростных (160 Мбайт/с) канала ввода/вывода и 5 гнезд расширения MicroChannel, обеспечивающих подключение множества периферийных адаптеров и устройств.
В состав стандартной конфигурации системы входят: дисковый накопитель емкостью 2.2 Гбайт, 4-скоростной считыватель компакт-дисков, флоппи-дисковод, 5 гнезд расширения MicroChannel и 3 отсека для установки внутренних накопителей. В дополнительную стойку расширения могут устанавливаться до 6 накопителей. Внешняя память может быть организована как на базе технологии SCSI-2, так и на основе SSA (Serial Storage Architecture). Объем дисковой памяти при использовании четырех стоек расширения может достигать 121.5 Гбайт, а при использовании пяти дисковых подсистем IBM 7134 Model 010 - 350 Гбайт.
Серверы G40 работают под управлением операционной системы AIX версий 4.1 и 4.2. С целью создания систем высокой готовности до 8 серверов G40 могут объединяться в кластер. Для этого необходимо приобретение специального слоя программных средств HACMP - High Availability Cluster Multi-Processing for AIX.
Среди симметричных мультипроцессорных систем, предлагаемых
Среди симметричных мультипроцессорных систем, предлагаемых компанией IBM, J40 считается системой среднего уровня. Она может включать от 2 до 8 процессоров PowerPC 604, оснащаться оперативной памятью объемом 128 Мбайт - 2 Мбайт, кэш-памятью второго уровня емкостью 1 Мбайт на каждый процессор (микропрцессор PPC 604 имеет встроенные раздельные кэши первого уровня для команд и данных объемом по 16 Кбайт). Для снижения задержек и увеличения пропускной способности подсистемы памяти как и в системах G40 применяется архитектура неблокируемого коммутатора данных. Максимальная полоса пропускания подсистемы памяти составляет 1.8 Гбайт/с.
Как и в серверах G40 в состав системы входит специальный сервисный процессор IBM SystemGuard, обеспечивающий выполнение диагностических процедур, наблюдение за состоянием и реконфигурацию системы.
Система поддерживает два высокоскоростных (160 Мбайт/с) канала ввода/вывода и 14 гнезд расширения MicroChannel, обеспечивающих подключение множества периферийных адаптеров и устройств.
В состав стандартной конфигурации системы входят: дисковый накопитель емкостью 4.5 Гбайт, 4-скоростной считыватель компакт-дисков, 7 отсеков для установки дисковых и 3 для установки ленточных накопителей. В дополнительную стойку расширения J01, имеющую 8 гнезд расширения MicroChannel, могут устанавливаться 12 дисковых и 2 ленточных накопителя. Таким образом, объем внутренней дисковой памяти может достигать 36 Гбайт, плюс 99 Гбайт может быть размещено в стойке расширения J01. Следует отметить, что конструкция системы допускает "горячую" замену всех дисковых и ленточных накопителей без выключения питания системы. Внешняя память может быть организована как на базе технологии SCSI-2, так и на основе SSA (Serial Storage Architecture).
Серверы J40, также как и серверы G40, работают под управлением операционной системы AIX версий 4.1 и 4.2. С целью создания систем высокой готовности до 8 серверов J40 могут объединяться в кластер. Для этого необходимо приобретение специального слоя программных средств HACMP - High Availability Cluster Multi-Processing for AIX.
Моделирование работы R10000 на нескольких компонентах пакета SPEC Кэшпамять второго уровня
Одним из методов улучшения временных показателей работы кэш-памяти является построение псевдо-множествнно-ассоциативной кэш-памяти. В такой кэш-памяти частота промахов находится на уровне частоты промахов множественно-ассоциативной памяти, а время выборки при попадании соответствует кэш-памяти с прямым отображением. Кэш-память R10000 организована именно таким способом, причем для ее реализации используются стандартные синхронные микросхемы памяти (SRAM). В одном наборе микросхем памяти находятся оба канала кэша. Информация о частоте использования этих каналов хранится в схемах управления кэшем на процессорном кристалле. Поэтому после обнаружения промаха в первичном кэше из наиболее часто используемого канала вторичного кэша считываются две четырехсловные строки. Их теги считываются вместе с первой четырехсловной строкой, а теги альтернативного канала читаются одновременно со второй четырехсловной строкой (это осуществляется простым инвертированием старшего разряда адреса).
При этом возможны три случая. Если происходит попадание по первому каналу, то данные доступны немедленно. Если происходит попадание по альтернативному каналу, происходит повторное чтение вторичного кэша. Если отсутствует попадание по обоим каналам, вторичный кэш должен перезаполняться из основной памяти.
Для обеспечения целостности данных в кэш-памяти большой емкости обычной практикой является использование кодов исправляющих одиночные ошибки (ECC-кодов). В R10000 с каждой четырехсловной строкой хранится 9-битовый ECC-код и бит четности. Дополнительный бит четности позволяет сократить задержку, поскольку проверка на четность может быть выполнена очень быстро, чтобы предотвратить использование некорректных данных. При этом, если обнаруживается корректируемая ошибка, то чтение повторяется через специальный двухтактный конвейер коррекции ошибок.
Мониторы обработки транзакций
Использование мониторов обработки транзакций является одним из методов достижения более высокой производительности для имеющейся конфигурации, особенно в режиме клиент/сервер. Иногда мониторы обработки транзакций оказываются очень полезными для создания гетерогенных баз данных, позволяющих хранить некоторые данные в одном формате (например, Oracle на Sun), а другие данные в другом (возможно Ingres на VAX или IMS на мейнфрейме IBM). Кроме того, некоторые TP-мониторы предоставляют сервис для легковесного компонента представления. Хорошо известен TP-монитор компании IBM - Customer Information Control System (CISC). Несколько реализаций CICS (MicroFocus, XDB, VI Systems, Integris) доступны в настоящее время на большинстве аппаратных платформ. Другими известными мониторами являются Tuxedo/T компании USL, TopEnd от NCR и Encina от Transarc.
TP-мониторы представляют собой промежуточный слой программного обеспечения, который располагается между приложением и системой или системами СУБД. При этом приложение должно быть модифицировано так, чтобы оно могло выдавать транзакции, написанные на языке монитора транзакций, а не обращаться прямо к базе данных посредством обычных механизмов (подобных различным формам встроенного SQL). Программисты прикладных систем являются также ответственными за составление файла описания, который отображает транзакции в определенные обращения к базе данных на родном языке обращений нижележащей СУБД (почти для всех СУБД под UNIX это SQL).
Мультипроцессорная когерентность кэшпамяти
Проблема, о которой идет речь, возникает из-за того, что значение элемента данных в памяти, хранящееся в двух разных процессорах, доступно этим процессорам только через их индивидуальные кэши. На Рисунок 3.30 показан простой пример, иллюстрирующий эту проблему.
Проблема когерентности памяти для мультипроцессоров и устройств ввода/вывода имеет много аспектов. Обычно в малых мультипроцессорах используется аппаратный механизм, называемый протоколом, позволяющий решить эту проблему. Такие протоколы называются протоколами когерентности кэш-памяти. Существуют два класса таких протоколов:
-
Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы). Этот подход будет рассмотрен в разд. 3.30.
Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии. Централизованная система записей отсутствует. Обычно кэши расположены на общей (разделяемой) шине и контроллеры всех кэшей наблюдают за шиной (просматривают ее) для определения того, не содержат ли они копию соответствующего блока.
В мультипроцессорных системах, использующих микропроцессоры с кэш-памятью, подсоединенные к централизованной общей памяти, протоколы наблюдения приобрели популярность, поскольку для опроса состояния кэшей они могут использовать заранее существующее физическое соединение - шину памяти.
Набор графических команд
UltraSPARC является первым универсальным процессором с 64-битовой архитектурой, обеспечивающий высокую пропускную способность, необходимую для реализации высокоскоростной графики и обработки видеоизображений в реальном масштабе времени. Расширенный набор команд UltraSPARC позволяет быстро (за один такт) выполнять достаточно сложные графические операции, для реализации которых обычно затрачивается несколько десятков тактов. При этом только три процента реальной площади кристалла было потрачено для реализации графических команд. Высокая производительность UltraSPARC и его способность выполнять декомпрессию и обработку видеоданных в реальном времени позволяют в ряде случае при построении системы обойтись без специальных дорогостоящих видеопроцессоров.
Высокоскоростная обработка графики и видеоизображений базируется на суперскалярной архитектуре процессора UltraSPARC. При этом для адресации данных (вычисления адресов команд загрузки и записи) широко используются целочисленные регистры, а для манипуляций с данными - регистры плавающей точки. Такое функциональное разделение регистров существенно увеличивает пропускную способность процессора, обеспечивая приложению максимальное количество доступных регистров и параллельное выполнение команд.
Специальный набор видеокоманд UltraSPARC (VIS - Video Instruction Set) предоставляет широкие возможности обработки графических данных: команды упаковки и распаковки пикселей, команды параллельного сложения, умножения и сравнения данных, представленных в нескольких целочисленных форматах, команды выравнивания и слияния, обработки контуров изображений и адресации массивов. Эти графические команды оптимизированы для работы с малоразрядной целочисленной арифметикой, при использовании которой обычно возникают значительные накладные расходы из-за необходимости частого преобразования целочисленного формата в формат ПТ и обратно. Возможность увеличения разрядности промежуточных результатов обеспечивает дополнительную точность, необходимую для высококачественных графических изображений. Все операнды графических команд находятся в регистрах ПТ, что обеспечивает максимальное количество регистров для хранения промежуточных результатов вычислений и параллельное выполнение команд.
UltraSPARC поддерживает различные алгоритмы компрессии, используемые для разнообразных видеоприложений и обработки неподвижных изображений, включая H.261, MPEG-1, MPEG-2 и JPEG. Более того, он может обеспечивать скорости кодирования и декодирования, необходимые для организации видеоконференций в реальном времени.
Набор кристаллов процессора hyperSPARC
Центральный процессор RT620 (рисунок 5.5) состоит из целочисленного устройства, устройства с плавающей точкой, устройства загрузки/записи, устройства переходов и двухканальной множественно-ассоциативной памяти команд емкостью 8 Кбайт. Целочисленное устройство включает АЛУ и отдельный тракт данных для операций загрузки/записи, которые представляют собой два из четырех исполнительных устройств процессора. Устройство переходов обрабатывает команды передачи управления, а устройство плавающей точки, реально состоит из двух независимых конвейеров - сложения и умножения чисел с плавающей точкой. Для увеличения пропускной способности процессора команды плавающей точки, проходя через целочисленный конвейер, поступают в очередь, где они ожидают запуска в одном из конвейеров плавающей точки. В каждом такте выбираются две команды. В общем случае, до тех пор, пока эти две команды требуют для своего выполнения различных исполнительных устройств при отсутствии зависимостей по данным, они могут запускаться одновременно. RT620 содержит два регистровых файла: 136 целочисленных регистров, сконфигурированных в виде восьми регистровых окон, и 32 отдельных регистра плавающей точки, расположенных в устройстве плавающей точки.
Названия компьютеров Alpha
Названия новых моделей компьютеров семейства Alpha строятся следующим образом: AlphaServer (AlphaStation) поколение процессора/частота, где AlphaServer или AlphaStation обозначает, соответственно, сервер или рабочую станцию, поколение процессоров представляется цифрой 4 для процессоров 2106* и цифрой 5 - для 21164.
Обеспечение резервного копирования
Поскольку обычно базы данных бывают очень большими и в них хранится исключительно важная информация, правильная организация резервного копирования данных является очень важным вопросом. Объем вовлеченных в этот процесс данных обычно огромен, особенно по отношению к размеру и обычной скорости устройств резервного копирования. Просто непрактично осуществлять дамп базы данных объемом 20 Гбайт на 4 мм магнитную ленту, работающую со скоростью 500 Кбайт/с: это займет примерно 12 часов. В этой цифре не учтены даже такие важные для работы системы соображения, как обеспечение согласованного состояния базы данных и готовность системы.
Обработка команд перехода
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Одним из типов конфликтов, с которыми приходится иметь дело разработчикам высокопроизводительных процессоров, являются конфликты по управлению, которые возникают при конвейеризации команд перехода и других команд, изменяющих значение счетчика команд.
Конфликты по управлению могут вызывать даже большие потери производительности суперскалярного процессора, чем конфликты по данным. По статистике среди команд управления, меняющих значение счетчика команд, преобладают команды условного перехода. Таким образом, снижение потерь от условных переходов становится критически важным вопросом. Имеется несколько методов сокращения приостановок конвейера, возникающих из-за задержек выполнения условных переходов. В процессоре R10000 используются два наиболее мощных метода динамической оптимизации выполнения условных переходов: аппаратное прогнозирование направления условных переходов и "выполнение по предположению" (speculation).
Устройство переходов процессора R10000 может декодировать и выполнять только по одной команде перехода в каждом такте. Поскольку за каждой командой перехода следует слот задержки, максимально могут быть одновременно выбраны две команды перехода, но только одна более ранняя команда перехода может декодироваться в данный момент времени. Во время декодирования команд к каждой команде добавляется бит признака перехода. Эти биты используются для пометки команд перехода в конвейере выборки команд.
Направление условного перехода прогнозируется с помощью специальной памяти (branch history table) емкостью 512 строк, которая хранит историю выполнения переходов в прошлом. Обращение к этой таблице осуществляется с помощью адреса команды во время ее выборки. Двухбитовый код прогноза в этой памяти обновляется каждый раз, когда принято окончательное решение о направлении перехода. Моделирование показало, что точность двухбитовой схемы прогнозирования для тестового пакета программ SPEC составляет 87%.
Все команды, выбранные вслед за командой условного перехода, считаются выполняемыми по предположению (условно). Это означает, что в момент их выборки заранее не известно, будет ли завершено их выполнение. Процессор допускает предварительную обработку и прогнозирование направления четырех команд условного перехода, которые могут разрешаться в произвольном порядке. При этом для каждой выполняемой по предположению команды условного перехода в специальный стек переходов записывается информация, необходимая для восстановления состояния процессора в случае, если направление перехода было предсказано неверно. Стек переходов имеет глубину в 4 элемента и позволяет в случае необходимости быстро и эффективно (за один такт) восстановить конвейер.
Общие положения
Основная память представляет собой следующий уровень иерархии памяти. Основная память удовлетворяет запросы кэш-памяти и служит в качестве интерфейса ввода/вывода, поскольку является местом назначения для ввода и источником для вывода. Для оценки производительности основной памяти используются два основных параметра: задержка и полоса пропускания. Традиционно задержка основной памяти имеет отношение к кэш-памяти, а полоса пропускания или пропускная способность относится к вводу/выводу. В связи с ростом популярности кэш-памяти второго уровня и увеличением размеров блоков у такой кэш-памяти, полоса пропускания основной памяти становится важной также и для кэш-памяти.
Задержка памяти традиционно оценивается двумя параметрами: временем доступа (access time) и длительностью цикла памяти (cycle time). Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти.
Основная память современных компьютеров реализуется на микросхемах статических и динамических ЗУПВ (Запоминающее Устройство с Произвольной Выборкой). Микросхемы статических ЗУВП (СЗУПВ) имеют меньшее время доступа и не требуют циклов регенерации. Микросхемы динамических ЗУПВ (ДЗУПВ) характеризуются большей емкостью и меньшей стоимостью, но требуют схем регенерации и имеют значительно большее время доступа.
В процессе развития ДЗУВП с ростом их емкости основным вопросом стоимости таких микросхем был вопрос о количестве адресных линий и стоимости соответствующего корпуса. В те годы было принято решение о необходимости мультиплексирования адресных линий, позволившее сократить наполовину количество контактов корпуса, необходимых для передачи адреса. Поэтому обращение к ДЗУВП обычно происходит в два этапа: первый этап начинается с выдачи сигнала RAS - row-access strobe (строб адреса строки), который фиксирует в микросхеме поступивший адрес строки, второй этап включает переключение адреса для указания адреса столбца и подачу сигнала CAS - column-access stobe (строб адреса столбца), который фиксирует этот адрес и разрешает работу выходных буферов микросхемы. Названия этих сигналов связаны с внутренней организацией микросхемы, которая как правило представляет собой прямоугольную матрицу, к элементам которой можно адресоваться с помощью указания адреса строки и адреса столбца.
Дополнительным требованием организации ДЗУВП является необходимость периодической регенерации ее состояния. При этом все биты в строке могут регенерироваться одновременно, например, путем чтения этой строки. Поэтому ко всем строкам всех микросхем ДЗУПВ основной памяти компьютера должны прозводиться периодические обращения в пределах определенного временного интервала порядка 8 миллисекунд.
Это требование кроме всего прочего означает, что система основной памяти компьютера оказывается иногда недоступной процессору, так как она вынуждена рассылать сигналы регенерации каждой микросхеме. Разработчики ДЗУПВ стараются поддерживать время, затрачиваемое на регенерацию, на уровне менее 5% общего времени. Обычно контроллеры памяти включают в свой состав аппаратуру для периодической регенерации ДЗУПВ.
В отличие от динамических, статические ЗУПВ не требуют регенерации и время доступа к ним совпадает с длительностью цикла. Для микросхем, использующих примерно одну и ту же технологию, емкость ДЗУВП по грубым оценкам в 4 - 8 раз превышает емкость СЗУПВ, но последние имеют в 8 - 16 раз меньшую длительность цикла и большую стоимость. По этим причинам в основной памяти практически любого компьютера, проданного после 1975 года, использовались полупроводниковые микросхемы ДЗУПВ (для построения кэш-памяти при этом применялись СЗУПВ). Естественно были и исключения, например, в оперативной памяти суперкомпьютеров компании Cray Research использовались микросхемы СЗУПВ.
Для обеспечения сбалансированности системы с ростом скорости процессоров должна линейно расти и емкость основной памяти. В последние годы емкость микросхем динамической памяти учетверялась каждые три года, увеличиваясь примерно на 60% в год. К сожалению скорость этих схем за этот же период росла гораздо меньшими темпами (примерно на 7% в год). В то же время производительность процессоров начиная с 1987 года практически увеличивалась на 50% в год. На рисунке 3.24 представлены основные временные параметры различных поколений ДЗУПВ.
Очевидно, согласование производительности современных процессоров со скоростью основной памяти вычислительных систем остается на сегодняшний день одной из важнейших проблем. Приведенные в предыдущем разделе методы повышения производительности за счет увеличения размеров кэш-памяти и введения многоуровневой организации кэш-памяти могут оказаться не достаточно эффективными с точки зрения стоимости систем. Поэтому важным направлением современных разработок являются методы повышения полосы пропускания или пропускной способности памяти за счет ее организации, включая специальные методы организации ДЗУПВ.
| Год появления | Емкость кристалла |
Длительность RAS | Длительность CAS | Время цикла | Оптими-зированный режим |
|
| max | min | |||||
| 1980 1983 1986 1989 1992 1995? |
64 Кбит 256 Кбит 1 Мбит 4 Мбит 16 Мбит 64 Мбит |
180 нс 150 нс 120 нс 100 нс 80 нс 65 нс |
150 нс 120 нс 100 нс 80 нс 60 нс 45 нс |
75 нс 50 нс 25 нс 20 нс 15 нс 10 нс |
250 нс 220 нс 190 нс 165 нс 120 нс 100 нс |
150 нс 100 нс 50 нс 40 нс 30 нс 20 нс |
Очередь целочисленных команд
Очередь целочисленных команд содержит 16 строк и выдает команды в два арифметико-логических устройства. Целочисленные команды поступают в свободные строки этой очереди, причем в каждом такте в нее могут записываться до 4 команд. Целочисленные команды остаются в очереди до тех пор, пока они не будут выданы в одно из АЛУ.
Очередь команд плавающей точки
Очередь адресных команд выдает команды в устройство загрузки/записи и содержит 16 строк. Очередь организована в виде циклического буфера FIFO (first-in first-out). Команды могут выдаваться в произвольном порядке, но должны записываться в очередь и изыматься из нее строго последовательно. В каждом такте в очередь могут поступать до 4 команд. Буфер FIFO поддерживает первоначальную последовательность команд, что упрощает обнаружение зависимостей по адресам. Выполнение выданной команды может не закончиться при обнаружении зависимости по адресам, кэш-промаха или конфликта по ресурсам. В этих случаях адресная очередь должна заново повторять выдачу команды до тех пор, пока ее выполнение не завершится.
Одновременная выдача нескольких команд для выполнения и динамическое планирование
Методы минимизации приостановок работы конвейера из-за наличия в программах логических зависимостей по данным и по управлению, рассмотренные в предыдущих разделах, были нацелены на достижение идеального CPI (среднего количества тактов на выполнение команды в конвейере), равного 1. Чтобы еще больше повысить производительность процессора необходимо сделать CPI меньшим, чем 1. Однако этого нельзя добиться, если в одном такте выдается на выполнение только одна команда. Следовательно необходима параллельная выдача нескольких команд в каждом такте. Существуют два типа подобного рода машин: суперскалярные машины и VLIW-машины (машины с очень длинным командным словом). Суперскалярные машины могут выдавать на выполнение в каждом такте переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. В отличие от суперскалярных машин, VLIW-машины выдают на выполнение фиксированное количество команд, которые сформатированы либо как одна большая команда, либо как пакет команд фиксированного формата. Планирование работы VLIW-машины всегда осуществляется компилятором.
Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств. Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд, прогнозирование переходов, кэши целевых адресов переходов и условное (по предположению) выполнение команд. Возросшая сложность, реализуемая этими механизмами, создает также проблемы реализации точного прерывания.
В типичной суперскалярной машине аппаратура может осуществлять выдачу от одной до восьми команд в одном такте. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждом такте не может выдаваться более одной команды обращения к памяти. Если какая-либо команда в потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах является переменной. Это отличает их от VLIW-машин, в которых полную ответственность за формирование пакета команд, которые могут выдаваться одновременно, несет компилятор, а аппаратура в динамике не принимает никаких решений относительно выдачи нескольких команд.
Предположим, что машина может выдавать на выполнение две команды в одном такте. Одной из таких команд может быть команда загрузки регистров из памяти, записи регистров в память, команда переходов, операции целочисленного АЛУ, а другой может быть любая операция плавающей точки. Параллельная выдача целочисленной операции и операции с плавающей точкой намного проще, чем выдача двух произвольных команд. В реальных системах (например, в микропроцессорах PA7100, hyperSPARC, Pentium и др.) применяется именно такой подход. В более мощных микропроцессорах (например, MIPS R10000, UltraSPARC, PowerPC 620 и др.) реализована выдача до четырех команд в одном такте.
Выдача двух команд в каждом такте требует одновременной выборки и декодирования по крайней мере 64 бит. Чтобы упростить декодирование можно потребовать, чтобы команды располагались в памяти парами и были выровнены по 64-битовым границам. В противном случае необходимо анализировать команды в процессе выборки и, возможно, менять их местами в момент пересылки в целочисленное устройство и в устройство ПТ. При этом возникают дополнительные требования к схемам обнаружения конфликтов. В любом случае вторая команда может выдаваться, только если может быть выдана на выполнение первая команда. Аппаратура принимает такие решения в динамике, обеспечивая выдачу только первой команды, если условия для одновременной выдачи двух команд не соблюдаются. На рисунке 3.18 представлена диаграмма работы подобного конвейера в идеальном случае, когда в каждом такте на выполнение выдается пара команд.
Такой конвейер позволяет существенно увеличить скорость выдачи команд. Однако чтобы он смог так работать, необходимо иметь либо полностью конвейеризованные устройства плавающей точки, либо соответствующее число независимых функциональных устройств. В противном случае устройство плавающей точки станет узким горлом и эффект, достигнутый за счет выдачи в каждом такте пары команд, сведется к минимуму.
| Тип команды | Ступень конвейера | |||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| Команда ПТ | IF | ID | EX | MEM | WB | |||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| КомандаПТ | IF | ID | EX | MEM | WB | |||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| Команда ПТ | IF | ID | EX | MEM | WB | |||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| Команда ПТ | IF | ID | EX | MEM | WB |
Описание архитектуры PowerScale
В архитектуре PowerScale (Рисунок 4.1) основным средством оптимизации доступа к разделяемой основной памяти является использование достаточно сложной системной шины. В действительности эта "шина" представляет собой комбинацию шины адреса/управления, реализованной классическим способом, и набора магистралей данных, которые соединяются между собой посредством высокоскоростного матричного коммутатора. Эта система межсоединений получила название MPB_SysBus. Шина памяти используется только для пересылки простых адресных тегов, а неблокируемый матричный коммутатор - для обеспечения более интенсивного трафика данных. К матричному коммутатору могут быть подсоединены до 4 двухпроцессорных портов, порт ввода/вывода и подсистема памяти.
Главным преимуществом такого подхода является то, что он позволяет каждому процессору иметь прямой доступ к подсистеме памяти. Другим важным свойством реализации является использование расслоения памяти, что позволяет многим процессорам обращаться к памяти одновременно.
Ниже приведена схема, иллюстрирующая общую организацию доступа к памяти (Рисунок 4.2) Каждый процессорный модуль имеет свой собственный выделенный порт памяти для пересылки данных. При этом общая шина адреса и управления гарантирует, что на уровне системы все адреса являются когерентными.
Определение минимальной конфигурации системы на основе анализа основных транзакций
При выборе конфигурации системы приходится рассматривать комбинацию достаточно сложных объектов: аппаратные средства + операционная система + СУБД + приложение. Из-за сложности анализа комбинации этих объектов обычно невозможно определить, будет ли способна данная система поддерживать требуемую нагрузку. Тем не менее, часто возможно сделать некоторые предположения и затем грубо проанализировать основные транзакции чтобы определить, при каких конфигурациях система не будет способной обработать эти основные транзакции. Хотя такой подход полезен только для относительно простых приложений, особенно для приложений с одной или двумя основными транзакциями, он дает неплохое начальное приближение и для больших и более сложных приложений. Вопрос о том, как соотнести конкретные запросы с требованиями пропускной способности дисковой подсистемы уже обсуждался в разделе 2.2.6.1.
В процессе оценки рассматриваются известные ограничения отдельных частей предлагаемой системы и затем производится их сравнение с минимальными потребностями в соответствии с поставленной задачей. Например, известно, что диск емкостью 2.1 Гбайт может выполнить 62 операции произвольного доступа в секунду. На каждую операцию затрачивается примерно 2 мс процессорного времени. Если приложение требует выполнения примерно 700 операций произвольного чтения диска в секунду, то очевидно, что система с одним диском не справится с такой задачей за требуемое время: необходимо по крайней мере 12 накопителей. Более того, практически сразу видно, что однопроцессорная система не может справиться с этой задачей, поскольку для обработки 700 дисковых операций требуется 1400 миллисекунд процессорного времени в секунду (т.е. более 1 секунды). Хотя совершенно ясно, что однопроцессорная система с одним диском не будет способна выполнять это приложение с требуемой скоростью, совсем неочевидно, что двухпроцессорная система с 12 дисками обеспечит требуемую производительность. Это происходит потому, что приложение очень сильно абстрагировано (в этом случае, любой вид работы приложения упрощен!).
Организация кэшпамяти
Концепция кэш-памяти возникла раньше чем архитектура IBM/360, и сегодня кэш-память имеется практически в любом классе компьютеров, а в некоторых компьютерах - во множественном числе.
Все термины, которые были определены раньше могут быть использованы и для кэш-памяти, хотя слово "строка" (line) часто употребляется вместо слова "блок" (block).
| Размер блока (строки) | 4-128 байт |
| Время попадания (hit time) | 1-4 такта синхронизации (обычно 1 такт) |
| Потери при промахе (miss penalty) (Время доступа - access time) (Время пересылки - transfer time) |
8-32 такта синхронизации (6-10 тактов синхронизации) (2-22 такта синхронизации) |
| Доля промахов (miss rate) | 1%-20% |
| Размер кэш-памяти | 4 Кбайт - 16 Мбайт |