Продолжительность резервного копирования
Продолжительность процедур резервного копирования возможно является наиболее важным вопросом для организаций с большими базами данных (объемом более 10 Гбайт), и выбор методики резервного копирования может определяться именно этим. Резервное копирование небольших баз данных может легко осуществляться при наличии всего одного накопителя на магнитной ленте Exabyte или DAT. Хотя выпускаемые в настоящее время накопители на МЛ позволяют копировать данные со скоростью примерно 1.25 Гбайт в час, для больших баз данных это очевидно неприемлемо. Для увеличения пропускной способности несколько устройств могут работать параллельно, хотя конфликты по ресурсам делают этот способ недостаточно эффективным при использовании одновременно более трех-четырех НМЛ.
Некоторые НМЛ на 8 мм ленте с аппаратной компрессией способны обеспечивать скорость до 3 Гбайт/час, т.е. более чем вдвое превышают скорость стандартных устройств. Некоторые из этих устройств имеют емкость до 25 Гбайт, но более типичной является емкость 8-10 Гбайт. Совместимые с IBM 3480 устройства, например, Fujitsu Model 2480, могут обеспечивать скорость около 10 Гбайт в час, но ограниченный объем носителя (200-400 Мбайт до компрессии) означает, что для обеспечения эффективности они должны устанавливаться в механических стекерах. Некоторые относительно новые устройства используют носитель информации в формате VHS и предлагают исключительно высокую пропускную способность и емкость. В сообщении об одном из таких устройств (от Metrum) указана скорость передачи в установившемся режиме почти 15 Мбайт/с при подключении с помощью выделенных каналов fast/wide SCSI-2. Емкость этого устройства составляет 14 Гбайт на одну ленту без компрессии.
Если недоступно устройство, которое поддерживает аппаратную компрессию, возможно стоит рассмотреть возможность использования программной компрессии. Скорость резервного копирования обычно определяется скоростью физической ленты, поэтому любой метод сокращающий количество данных, которые должны быть записаны на ленту, должен исследоваться, особенно при использовании быстрых ЦП. Базы данных являются хорошими кандидатами для компрессии, поскольку большинство таблиц и строк включают значительную часть свободного пространства (обычно используются даже коэффициенты заполнения, обеспечивающие определенный процент свободного пространства с целью увеличения производительности). Некоторые таблицы могут содержать также текст или разбросанные поля двоичных данных и готовы для компрессии.
Программное обеспечение
Ключевым свойством новой архитектуры является гибкость. Она полностью поддерживает программно реализованные, распределенные отказоустойчивые системы, подобные NonStop-Kernel. Аппаратные средства позволяют создавать отказоустойчивые SMP-конфигураций для операционных систем, подобных UNIX или Windows NT. Системы могут поддерживать также программное продукты типа Oracle Parallel Server, которые базируются на модели разделяемых общих дисков.
ServerNet позволяет также создавать гибридные системы. Например, одна система может работать под управлением Windows NT в качестве фронтальной машины для базы данных Oracle Parallel Server. При этом системы соединяются друг с другом посредством ServerNet.
Поддержка большого числа операционных систем требует сведения к минимуму усилий по портированию программного обеспечения. С этой целью весь специфический для конкретной платформы код вынесен за рамки операционной системы. При этом для обеспечения отказоустойчивости не требует никаких модификаций в ядре операционной системы. Большая часть этого специфичного для соответствующей платформы кода работает на сервисном процессоре, независимо от операционной системы основных процессоров.
Специальный набор портируемых приложений обеспечивает средства управления системой. Эти приложения отображают состояние аппаратуры, сообщают об ошибках, предпринимают при необходимости автоматические шаги по восстановлению и обеспечивают интерфейсы для удаленного управления системой, используя стандартные для промышленности протоколы.
Простейшая организация конвейера и оценка его производительности
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода. При параллелизме совмещение операций достигается путем воспроизведения в нескольких копиях аппаратной структуры. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Для иллюстрации основных принципов построения процессоров мы будем использовать простейшую архитектуру, содержащую 32 целочисленных регистра общего назначения (R0, ... ,R31), 32 регистра плавающей точки (F0,...,F31) и счетчик команд PC. Будем
считать, что набор команд нашего процессора включает типичные арифметические
и логические операции, операции с плавающей точкой, операции пересылки данных, операции управления потоком команд и системные операции. В арифметических
командах используется трехадресный формат, типичный для RISC-процессоров, а для обращения к памяти используются операции загрузки и записи содержимого регистров в память.
Выполнение типичной команды можно разделить на следующие этапы:
выборка команды - IF (по адресу, заданному счетчиком команд, из памяти извлекается команда); декодирование команды / выборка операндов из регистров - ID; выполнение операции / вычисление эффективного адреса памяти - EX; обращение к памяти - MEM; запоминание результата - WB.На рисунке 3.1 представлена схема простейшего процессора, выполняющего указанные выше этапы выполнения команд без совмещения. Чтобы конвейеризовать эту схему, мы можем просто разбить выполнение команд на указанные выше этапы, отведя для выполнения каждого этапа один такт синхронизации, и начинать в каждом такте выполнение новой команды. Естественно, для хранения промежуточных результатов каждого этапа необходимо использовать регистровые станции. Хотя общее время выполнения одной команды в таком конвейере будет составлять пять тактов, в каждом такте аппаратура будет выполнять в совмещенном режиме пять различных команд.
Работу конвейера можно условно представить в виде временной диаграммы (рисунок 3.2), на которых обычно изображаются выполняемые команды, номера тактов и этапы выполнения команд.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
Тот факт, что время выполнения каждой команды в конвейере не уменьшается, накладывает некоторые ограничения на практическую длину конвейера. Кроме ограничений, связанных с задержкой конвейера, имеются также ограничения, возникающие в результате несбалансированности задержки на каждой его ступени и из-за накладных расходов на конвейеризацию. Частота синхронизации не может быть выше, а, следовательно, такт синхронизации не может быть меньше, чем время, необходимое для работы наиболее медленной ступени конвейера. Накладные расходы на организацию конвейера возникают из-за задержки сигналов в конвейерных регистрах (защелках) и из-за перекосов сигналов синхронизации. Конвейерные регистры к длительности такта добавляют время установки и задержку распространения сигналов. В предельном случае длительность такта можно уменьшить до суммы накладных расходов и перекоса сигналов синхронизации, однако при этом в такте не останется времени для выполнения полезной работы по преобразованию информации.
Протокол MESI и функция вмешательства
В рамках архитектуры PowerScale используется протокол MESI, который представляет собой стандартный способ реализации вторичной когерентности кэш-памяти. Одной из основных задач протокола MESI является откладывание на максимально возможный срок операции обратной записи кэшированных данных в глобальную память системы. Это позволяет улучшить производительность системы за счет минимизации ненужного трафика данных между кэшами и основной памятью. Протокол MESI определяет четыре состояния, в которых может находиться каждая строка каждого кэша системы. Эта информация используется для определения соответствующих последующих операций (Рисунок 4.4).
Состояние строки "Единственная" (Exclusive):
Данные этой строки достоверны в данном кэше и недостоверны в любом другом кэше. Данные не модифицированы по отношению к памяти.
Состояние строки "Разделяемая" (Shared):
Данные этой строки достоверны в данном кэше, а также в одном или нескольких удаленных кэшах.
Состояние строки "Модифицированная" (Modified):
Данные этой строки достоверны только в данном кэше и были модифицированы. Данные недостоверны в памяти.
Состояние строки "Недостоверная" (Invalid):
Достоверные данные не были найдены в данном кэше.
Работа суперскалярного конвейера
При параллельной выдаче двух операций (одной целочисленной команды и одной команды ПТ) потребность в дополнительной аппаратуре, помимо обычной логики обнаружения конфликтов, минимальна: целочисленные операции и операции ПТ используют разные наборы регистров и разные функциональные устройства. Более того, усиление ограничений на выдачу команд, которые можно рассматривать как специфические структурные конфликты (поскольку выдаваться на выполнение могут только определенные пары команд), обнаружение которых требует только анализа кодов операций. Единственная сложность возникает, только если команды представляют собой команды загрузки, записи и пересылки чисел с плавающей точкой. Эти команды создают конфликты по портам регистров ПТ, а также могут приводить к новым конфликтам типа RAW, когда операция ПТ, которая могла бы быть выдана в том же такте, является зависимой от первой команды в паре.
Проблема регистровых портов может быть решена, например, путем реализации отдельной выдачи команд загрузки, записи и пересылки с ПТ. В случае составления ими пары с обычной операцией ПТ ситуацию можно рассматривать как структурный конфликт. Такую схему легко реализовать, но она будет иметь существенное воздействие на общую производительность. Конфликт подобного типа может быть устранен посредством реализации в регистровом файле двух дополнительных портов (для выборки и записи).
Если пара команд состоит из одной команды загрузки с ПТ и одной операции с ПТ, которая от нее зависит, необходимо обнаруживать подобный конфликт и блокировать выдачу операции с ПТ. За исключением этого случая, все другие конфликты естественно могут возникать, как и в обычной машине, обеспечивающей выдачу одной команды в каждом такте. Для предотвращения ненужных приостановок могут, правда потребоваться дополнительные цепи обхода.
Другой проблемой, которая может ограничить эффективность суперскалярной обработки, является задержка загрузки данных из памяти. В нашем примере простого конвейера команды загрузки имели задержку в один такт, что не позволяло следующей команде воспользоваться результатом команды загрузки без приостановки. В суперскалярном конвейере результат команды загрузки не может быть использован в том же самом и в следующем такте. Это означает, что следующие три команды не могут использовать результат команды загрузки без приостановки. Задержка перехода также становится длиною в три команды, поскольку команда перехода должна быть первой в паре команд. Чтобы эффективно использовать параллелизм, доступный на суперскалярной машине, нужны более сложные методы планирования потока команд, используемые компилятором или аппаратными средствами, а также более сложные схемы декодирования команд.
Рассмотрим, например, что дает разворачивание циклов и планирование потока команд для суперскалярного конвейера. Ниже представлен цикл, который мы уже разворачивали и планировали его выполнение на простом конвейере.
Loop: LD F0,0(R1) ;F0=элемент вектора
ADDD F4,F0,F2 ;добавление скалярной величины из F2
SD 0(R1),F4 ;запись результата
SUBI R1,R1,#8 ;декрементирование указателя
;8 байт на двойное слово
BNEZ R1,Loop ;переход R1!=нулю
Чтобы спланировать этот цикл для работы без задержек, необходимо его развернуть и сделать пять копий тела цикла. После такого разворачивания цикл будет содержать по пять команд LD, ADDD, и SD, а также одну команду SUBI и один условный переход BNEZ. Развернутая и оптимизированная программа этого цикла дана ниже:
| Целочисленная команда | Команда ПТ | Номер такта |
| Loop: LD F0,0(R1) LD F8,-8(R1) LD F10,-16(R1) LD F14,-24(R1) LD F18,-32(R1) SD 0(R1),F4 SD -8(R1),F8 SD -16(R1),F12 SD -24(R1),F16 SUBI R1,R1,#40 BNEZ R1,Loop SD -32(R1),F20 |
ADDD F4,F0,F2 ADDD F8,F6,F2 ADDD F12,F10,F2 ADDD F16,F14,F2 ADDD F20,F18,F2 |
1 2 3 4 5 6 7 8 9 10 11 12 |
Этот развернутый суперскалярный цикл теперь работает со скоростью 12 тактов на итерацию, или 2.4 такта на один элемент (по сравнению с 3.5 тактами для оптимизированного развернутого цикла на обычном конвейере. В этом примере производительность суперскалярного конвейера ограничена существующим соотношением целочисленных операций и операций ПТ, но команд ПТ не достаточно для поддержания полной загрузки конвейера ПТ. Первоначальный оптимизированный неразвернутый цикл выполнялся со скоростью 6 тактов на итерацию, вычисляющую один элемент. Мы получили таким образом ускорение в 2.5 раза, больше половины которого произошло за счет разворачивания цикла. Чистое ускорение за счет суперскалярной обработки дало улучшение примерно в 1.5 раза.
В лучшем случае такой суперскалярный конвейер позволит выбирать две команды и выдавать их на выполнение, если первая из них является целочисленной, а вторая - с плавающей точкой. Если это условие не соблюдается, что легко проверить, то команды выдаются последовательно. Это показывает два главных преимущества суперскалярной машины по сравнению с WLIW-машиной. Во-первых, малое воздействие на плотность кода, поскольку машина сама определяет, может ли быть выдана следующая команда, и нам не надо следить за тем, чтобы команды соответствовали возможностям выдачи. Во-вторых, на таких машинах могут работать неоптимизированные программы, или программы, откомпилированные в расчете на более старую реализацию. Конечно такие программы не могут работать очень хорошо. Один из способов улучшить ситуацию заключается в использовании аппаратных средств динамической оптимизации.
В общем случае в суперскалярной системе команды могут выполняться параллельно и возможно не в порядке, предписанном программой. Если не предпринимать никаких мер, такое неупорядоченное выполнение команд и наличие множества функциональных устройств с разными временами выполнения операций могут приводить к дополнительным трудностям. Например, при выполнении некоторой длинной команды с плавающей точкой (команды деления или вычисления квадратного корня) может возникнуть исключительная ситуация уже после того, как завершилось выполнение более быстрой операции, выданной после этой длинной команды. Для того, чтобы поддерживать модель точных прерываний, аппаратура должна гарантировать корректное состояние процессора при прерывании для организации последующего возврата.
Обычно в машинах с неупорядоченным выполнением команд предусматриваются дополнительные буферные схемы, гарантирующие завершение выполнения команд в строгом порядке, предписанном программой. Такие схемы представляют собой некоторый буфер "истории", т.е. аппаратную очередь, в которую при выдаче попадают команды и текущие значения регистров результата этих команд в заданном программой порядке.
В момент выдачи команды на выполнение она помещается в конец этой очереди, организованной в виде буфера FIFO (первый вошел - первый вышел). Единственный способ для команды достичь головы этой очереди - завершение выполнения всех предшествующих ей операций. При неупорядоченном выполнении некоторая команда может завершить свое выполнение, но все еще будет находиться в середине очереди. Команда покидает очередь, когда она достигает головы очереди и ее выполнение завершается в соответствующем функциональном устройстве. Если команда находится в голове очереди, но ее выполнение в функциональном устройстве не закончено, она очередь не покидает. Такой механизм может поддерживать модель точных прерываний, поскольку вся необходимая информация хранится в буфере и позволяет скорректировать состояние процессора в любой момент времени.
Этот же буфер "истории" позволяет реализовать и условное (speculative) выполнение команд (выполнение по предположению), следующих за командами условного перехода. Это особенно важно для повышения производительности суперскалярных архитектур. Статистика показывает, что на каждые шесть обычных команд в программах приходится в среднем одна команда перехода. Если задерживать выполнение следующих за командой перехода команд, потери на конвейеризацию могут оказаться просто неприемлемыми. Например, при выдаче четырех команд в одном такте в среднем в каждом втором такте выполняется команда перехода. Механизм условного выполнения команд, следующих за командой перехода, позволяет решить эту проблему. Это условное выполнение обычно связано с последовательным выполнением команд из заранее предсказанной ветви команды перехода. Устройство управления выдает команду условного перехода, прогнозирует направление перехода и продолжает выдавать команды из этой предсказанной ветви программы.
Если прогноз оказался верным, выдача команд так и будет продолжаться без приостановок. Однако если прогноз был ошибочным, устройство управления приостанавливает выполнение условно выданных команд и, если необходимо, использует информацию из буфера истории для ликвидации всех последствий выполнения условно выданных команд. Затем начинается выборка команд из правильной ветви программы. Таким образом, аппаратура, подобная буферу, истории позволяет не только решить проблемы с реализацией точного прерывания, но и обеспечивает увеличение производительности суперскалярных архитектур.
RAID 2 матрица с поразрядным расслоением
Один из путей достижения надежности при снижении потерь емкости памяти может быть подсказан организацией основной памяти, в которой для исправления одиночных и обнаружения двойных ошибок используются избыточные контрольные разряды. Такое решение можно повторить путем поразрядного расслоения данных и записи их на диски группы, дополненной достаточным количеством контрольных дисков для обнаружения и исправления одиночных ошибок. Один диск контроля четности позволяет обнаружить одиночную ошибку, но для ее исправления требуется больше дисков.
Такая организация обеспечивает лишь один поток ввода/вывода для каждой группы независимо от ее размера. Группы большого размера приводят к снижению избыточной емкости, идущей на обеспечение отказоустойчивости, тогда как при организации меньшего числа групп наблюдается снижение операций ввода/вывода, которые могут выполняться матрицей параллельно.
При записи больших массивов данных системы уровня 2 имеют такую же производительность, что и системы уровня 1, хотя в них используется меньше контрольных дисков и, таким образом, по этому показателю они превосходят системы уровня 1. При передаче небольших порций данных производительность теряется, так как требуется записать либо считать группу целиком, независимо от конкретных потребностей. Таким образом, RAID уровня 2 предпочтительны для суперкомпьютеров, но не подходят для обработки транзакций. Компания Thinking Machine использовала RAID уровня 2 в ЭВМ Connection Machine при 32 дисках данных и 10 контрольных дисках, включая 3 диска горячего резерва.
RAID 3 аппаратное обнаружение ошибок и четность
Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. Эти диски становятся полностью избыточными, так как большинство контроллеров в состоянии определить, когда диск отказал при помощи специальных сигналов, поддерживаемых дисковым интерфейсом, либо при помощи дополнительного кодирования информации, записанной на диск и используемой для исправления случайных сбоев. По существу, если контроллер может определить положение ошибочного разряда, то для восстановления данных требуется лишь один бит четности. Уменьшение числа контрольных дисков до одного на группу снижает избыточность емкости до вполне разумных размеров. Часто количество дисков в группе равно 5 (4 диска данных плюс 1 контрольный). Подобные устройства выпускаются, например, фирмами Maxtor и Micropolis. Каждое из таких устройств воспринимается машиной как отдельный логический диск с учетверенной пропускной способностью, учетверенной емкостью и значительно более высокой надежностью.
RAID 4 внутригрупповой параллелизм
RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу к группе в единицу времени. Логические блоки передачи в данном случае не распределяются между отдельными дисками, вместо этого каждый индивидуальный блок попадает на отдельный диск.
Достоинство поразрядного расслоения состоит в простоте вычисления кода Хэмминга, что необходимо для обнаружения и исправления ошибок в системах уровня 2. В RAID уровня 3 обнаружение ошибок диска с точностью до сектора осуществляется дисковым контроллером. Следовательно, если записывать отдельный блок передачи в отдельный сектор, то можно обнаружить ошибки отдельного считывания без доступа к дополнительным дискам. Главное отличие между системами уровня 3 и 4 состоит в том, что в последних расслоение выполняется на уровне сектора, а не на уровне битов или байтов.
В системах уровня 4 обновление контрольной информации реализовано достаточно просто. Для вычисления нового значения четности требуются лишь старый блок данных, старый блок четности и новый блок данных:
новая четность = (старые данные xor новые данные) xor старая четность
В системах уровня 4 для записи небольших массивов данных используются два диска, которые выполняют четыре выборки (чтение данных плюс четности, запись данных плюс четности). Производительность групповых операций записи и считывания остается прежней, но при небольших (на один диск) записях и считываниях производительность существенно улучшается. К сожалению, улучшение производительности оказывается недостаточной для того, чтобы этот метод мог занять место системы уровня 1.
RAID 5 четность вращения для распараллеливания записей
RAID уровня 4 позволяли добиться параллелизма при считывании отдельных дисков, но запись по-прежнему ограничена возможностью выполнения одной операции на группу, так как при каждой операции должны выполняться запись и чтение контрольного диска. Система уровня 5 улучшает возможности системы уровня 4 посредством распределения контрольной информации между всеми дисками группы.
Это небольшое изменение оказывает огромное влияние на производительность записи небольших массивов информации. Если операции записи могут быть спланированы так, чтобы обращаться за данными и соответствующими им блоками четности к разным дискам, появляется возможность параллельного выполнения N/2 записей, где N - число дисков в группе. Данная организация имеет одинаково высокую производительность при записи и при считывании как небольших, так и больших объемов информации, что делает ее наиболее привлекательной в случаях смешанных применений.
RAID 6 Двумерная четность для обеспечения большей надежности
Этот пункт можно рассмотреть в контексте соотношения отказоустойчивость/пропускная способность. RAID 5 предлагают, по существу, лишь одно измерение дисковой матрицы, вторым измерением которой являются секторы. Теперь рассмотрим объединение дисков в двумерный массив таким образом, чтобы секторы являлись третьим измерением. Мы можем иметь контроль четности по строкам, как в системах уровня 5, а также по столбцам, которые, в свою очередь. могут расслаиваться для обеспечения возможности параллельной записи. При такой организации можно преодолеть любые отказы двух дисков и многие отказы трех дисков. Однако при выполнении логической записи реально происходит шесть обращений к диску: за старыми данными, за четностью по строкам и по столбцам, а также для записи новых данных и новых значений четности. Для некоторых применений с очень высокими требованиями к отказоустойчивости такая избыточность может оказаться приемлемой, однако для традиционных суперкомпьютеров и для обработки транзакций данный метод не подойдет.
В общем случае, если доминируют короткие записи и считывания и стоимость емкости памяти не является определяющей, наилучшую производительность демонстрируют системы RAID уровня 1. Однако если стоимость емкости памяти существенна, либо если можно снизить вероятность появления коротких записей (например, при высоком коэффициенте отношения числа считываний к числу записей, при эффективной буферизации последовательностей считывания-модификации-записи, либо при приведении коротких записей к длинным с использованием стратегии кэширования файлов), RAID уровня 5 могут обеспечить очень высокую производительность, особенно в терминах отношения стоимость/производительность.
RAID1 Зеркальные диски
Зеркальные диски представляют традиционный способ повышения надежности магнитных дисков. Это наиболее дорогостоящий из рассматриваемых способов, так как все диски дублируются и при каждой записи информация записывается также и на проверочный диск. Таким образом, приходится идти на некоторые жертвы в пропускной способности ввода/вывода и емкости памяти ради получения более высокой надежности. Зеркальные диски широко применяются многими фирмами. В частности компания Tandem Computers применяет зеркальные диски, а также дублирует контроллеры и магистрали ввода/вывода с целью повышения отказоустойчивости. Эта версия зеркальных дисков поддерживает параллельное считывание.
Контроллер HSC-70, используемый в VAX-кластерах компании DEC, выполнен по методу зеркальных дисков, называемому методом двойников. Содержимое отдельного диска распределяется между членами его группы двойников. Если группа состоит из двух двойников, мы получаем вариант зеркальных дисков. Заданный сектор может быть прочитан с любого из устройств группы двойников. После того как некоторый сектор записан, необходимо обновить информацию на всех дисках-двойниках. Контроллер имеет возможность предсказывать ожидаемые отказы некоторого диска и выделять горячий резерв для создания копии и сохранения ее на время работы механизма создания группы двойников. Затем отказавший диск может быть выключен.
Дублирование всех дисков может означать удвоение стоимости всей системы или, иначе, использование лишь 50% емкости диска для хранения данных. Повышение емкости, на которое приходится идти, составляет 100%. Такая низкая экономичность привела к появлению следующего уровня RAID.
Распределение данных
Другим фактором, влияющим на конфигурацию подсистемы ввода/вывода, является предполагаемое распределение данных по дискам. Даже минимальная по объему система должна иметь по крайней мере четыре диска: один для операционной системы и области подкачки (swap), один для данных, один для журнала и один для индексов. Конфликты по этим ресурсам в системе с ограничениями ввода/вывода являются самым большим отдельным классом проблем обеспечения производительности в среде, в которой приложение в определенной степени было настроено (т.е. в наиболее продуктивных средах). Более крупные системы должны учитывать даже большее количество переменных, такие как зеркалирование дисков, расщепление дисков и перекрытие ресурсов. Вообще говоря, наиболее продуктивным и достаточно эффективным по стоимости способом распределения данных является обеспечение всех основных логических сущностей отдельным набором дисков.
Хотя технически возможно объединить по несколько логических функций на одних и тех же (физических или логических) дисках, для подсистемы ввода/вывода это оказывается очень разрушительным и почти всегда приводит к неудовлетворительной производительности. Например, рассмотрим базу данных, которая состоит из таблицы данных размером 1.5 Гбайт и индексов объемом 400 Мбайт, и которая требует 40 Мбайт для размещения журнального файла. Соблазнительно просуммировать эти объемы вместе и обнаружить, что вся эта информация может поместиться на одном диске емкостью 2.1 Гбайт. Если реализовать такую конфигурацию системы, то при выполнении приложением практически любого обновления базы данных, каретка диска все время будет сновать челноком по диску для каждой транзакции. В частности, процесс формирования журнала, который должен писаться синхронно и медленно, в действительности будет выполняться в режиме произвольного доступа, а не в режиме последовательного доступа к диску. Уже только это одно будет существенно задерживать каждую транзакцию обновления базы данных.
Кроме того, выполнение запросов, выбирающих записи из таблицы данных путем последовательного сканирования индекса, будет связано с сильно увеличенным временем ожидания ввода/вывода. Обычно сканирование индекса выполняется последовательно, но в данном случае каретка диска должна перемещаться для поиска каждой записи данных между выборками индексов. В результате происходит произвольный доступ к индексу, который предполагался последовательным! (В действительности индекс мог специально создаваться с целью последовательного сканирования). Если таблица данных, индекс и журнал находятся на отдельных дисках, то произвольный доступ к диску осуществляется только при выборке данных из таблицы и результирующая производительность увеличивается вдвое.
Последним пунктом обсуждения возможности объединения разных функций на одних и тех же физических ресурсах является то, что подобное объединение часто создает ситуации, в которых максимизируются времена подвода головок на диске. Хотя время позиционирования в спецификациях дисковых накопителей обычно приводится как одно число, в действительности длительность позиционирования сильно зависит от необходимого конкретного перемещения головок. Приводимое в спецификациях время позиционирования представляет собой сумму времен всех возможных позиционирований головок, деленное на количество возможных позиционирований. Это не то время, которое затрачивается при выполнении "типичного" позиционирования. Сама физика процесса перемещения дисковой каретки определяет, что позиционирование на короткое расстояние занимает гораздо меньше времени, чем на длинное. Позиционирование на смежный цилиндр занимает всего несколько миллисекунд, в то время как позиционирование на полный ход каретки длится значительно больше времени, чем приводимое в спецификациях среднее время позиционирования. Например, для диска 2.1 Гб позиционирование головки на соседний цилиндр обычно занимает 1.7 мс, но длится 23 мс для полного хода каретки (в 13 раз дольше). Поэтому длительное позиционирование головок, возникающее при последовательности обращений к двум разным частям диска, необходимо по возможности исключать.
Рекомендации:
Отдельные логические функции СУБД следует реализовывать на отдельных выделенных дисковых ресурсах. Необходимо планировать размещение данных на дисках для минимизации количества и длительности позиционирования головок.Распределение памяти в четырехпроцессорной SMPсистеме
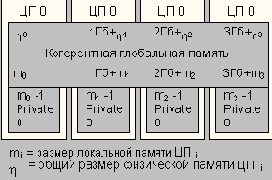
В такой архитектуре можно выделить три отдельных класса памяти (Рисунок 4.11). Наименьшее время доступа имеет локальная память, доступ к глобальной памяти, размещенной на плате локального процессора, занимает больше времени, а доступ к глобальной памяти на плате другого ЦП занимает еще больше времени. Локальная память каждого ЦП содержит копию части программного кода и данных операционной системы, доступ к которым разрешен только по чтению. Кроме того, в локальную память операционная система может поместить некоторые частные для процессора данные. Проведенная оценка показала, что размещение этих объектов в локальной памяти и случайное распределение глобальной памяти будет обеспечивать производительность, сравнимую с производительностью системы, реализующей механизмы единой глобальной памяти.
Системы с разделяемой памятью могут функционировать либо в симплексном, либо в дуплексном режиме. Система, построенная на узлах SMP и обеспечивающая отказоустойчивость программными средствами, может использовать симплексный режим. Полностью аппаратная отказоустойчивая система с масштабируемостью SMP требует реализации дуплексного режима работы.
Шина когерентности может также поддерживать работу гибридных распределенных систем, в которых распределенная память используется для обмена данными между процессорами. В этом случае система распределяет большую часть памяти под "локальные нужды" процессоров, а в глобальную память помещает только разделяемые данные.
Расширение устройства ПТ средствами выполнения по предположению
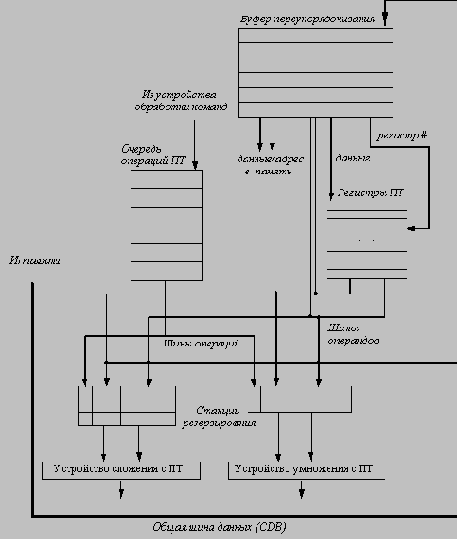
-
Выдача. Получает команду из очереди команд плавающей точки. Выдает команду для выполнения, если имеется свободная станция резервирования и свободная строка в буфере переупорядочивания; передает на станцию резервирования операнды, если они находятся в регистрах или в буфере переупорядочивания; и обновляет поля управления для индикации того, что буфера используются. Номер отведенной под результат строки буфера переупорядочивания также записывается в станцию резервирования, так что этот номер может использоваться для тегирования (пометки) результата, когда он помещается на CDB. Если все станции резервирования заполнены, или полон буфер переупорядочивания, выдача команды приостанавливается до тех пор, пока в обоих буферах не появится доступной строки.
Выполнение. Если один или несколько операндов еще не готовы (отсутствуют), осуществляется просмотр CDB (Common Data Bus) и происходит ожидание вычисления значения требуемого регистра. На этом шаге выполняется проверка наличия конфликтов типа RAW. Когда оба операнда оказываются на станции резервирования, происходит вычисление результата операции.
Запись результата. Когда результат вычислен и становится доступным, выполняется его запись на CDB (с посылкой тега буфера переупорядочивания, который был присвоен команде на этапе выдачи для выполнения) и из CDB в буфер переупорядочивания, а также в каждую станцию резервирования, ожидающую этот результат. (Можно было бы также читать результат из буфера переупорядочивания, а не из CDB, точно также, как централизованная схема управления (scoreboard) читает результаты из регистров, а не с шины завершения). Станция резервирования помечается как свободная.
Фиксация. Когда команда достигает головы буфера переупорядочивания и ее результат присутствует в буфере, соответствующий регистр обновляется значением результата (или выполняется запись в память, если операция - запись в память), и команда изымается из буфера переупорядочивания.
Когда команда фиксируется, соответствующая строка буфера переупорядочивания очищается, а место назначения результата (регистр или ячейка памяти) обновляется. Чтобы не менять номера строк буфера переупорядочивания после фиксации результата команды, буфер переупорядочивания реализуется в виде циклической очереди, так что позиции в буфере переупорядочивания меняются, только когда команда фиксируется. Если буфер переупорядочивания полностью заполнен, выдача команд останавливается до тех пор, пока не освободится очередная строка буфера.
Поскольку никакая запись в регистры или ячейки памяти не происходит до тех пор, пока команда не фиксируется, машина может просто ликвидировать все свои выполненные по предположению действия, если обнаруживается, что направление условного перехода было спрогнозировано не верно.
Исключительные ситуации в подобной машине не воспринимаются до тех пор, пока соответствующая команда не готова к фиксации. Если выполняемая по предположению команда вызывает исключительную ситуацию, эта исключительная ситуация записывается в буфер упорядочивания. Если обнаруживается неправильный прогноз направления условного перехода и выясняется, что команда не должна была выполняться, исключительная ситуация гасится вместе с командой, когда обнуляется буфер переупорядочивания. Если же команда достигает вершины буфера переупорядочивания, то мы знаем, что она более не является выполняемой по предположению (она уже стала безусловной), и исключительная ситуация должна действительно восприниматься.
Эту методику выполнения по предположению легко распространить и на целочисленные регистры и функциональные устройства. Действительно, выполнение по предположению может быть более полезно в целочисленных программах, поскольку именно такие программы имеют менее предсказуемое поведение переходов. Кроме того, эти методы могут быть расширены так, чтобы обеспечить работу в машинах с выдачей на выполнение и фиксацией результатов нескольких команд в каждом такте. Выполнение по предположению возможно является наиболее интересным методом именно для таких машин, поскольку менее амбициозные машины могут довольствоваться параллелизмом уровня команд внутри базовых блоков при соответствующей поддержке со стороны компилятора, использующего технологию разворачивания циклов.
Очевидно, все рассмотренные ранее методы не могут достичь большей степени распараллеливания, чем заложено в конкретной прикладной программе. Вопрос увеличения степени параллелизма прикладных систем в настоящее время является предметом интенсивных исследований, проводимых во всем мире.
Резервное копирование в режиме online
В некоторых случаях необходимо выполнять "резервное копирование в режиме online", т.е. выполнять резервное копирование в то время, когда база данных находится в активном состоянии с подключенными и работающими пользователями.
При выполнении резервного копирования базы данных предполагается, что она находится в согласованном состоянии, т.е. все зафиксированные обновления базы данных не только занесены в журнал, но и записаны также в таблицы базы данных. При реализации резервного копирования в режиме online возникает проблема: чтобы резервные копии оказались согласованными, после того как достигнута точка согласованного состояния базы данных и начинается резервное копирование, все обновления базы данных должны выполняться без обновления таблиц самой базы до тех пор, пока не завершится ее полное копирование. Большинство основных СУБД обеспечивают возможность резервного копирования в режиме online.
СБИС 6портового маршрутизатора ServerNet Процессорный модуль
Сегментация памяти
Другой подход к организации памяти опирается на тот факт, что программы обычно разделяются на отдельные области-сегменты. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается своя собственная нумерация слов, начиная с нуля.
Обычно в подобных системах обмен информацией между пользователями строится на базе сегментов. Поэтому сегменты являются отдельными логическими единицами информации, которые необходимо защищать, и именно на этом уровне вводятся различные режимы доступа к сегментам. Можно выделить два основных типа сегментов: программные сегменты и сегменты данных (сегменты стека являются частным случаем сегментов данных). Поскольку общие программы должны обладать свойством повторной входимости, то из программных сегментов допускается только выборка команд и чтение констант. Запись в программные сегменты может рассматриваться как незаконная и запрещаться системой. Выборка команд из сегментов данных также может считаться незаконной и любой сегмент данных может быть защищен от обращений по записи или по чтению.
Для реализации сегментации было предложено несколько схем, которые отличаются деталями реализации, но основаны на одних и тех же принципах.
В системах с сегментацией памяти каждое слово в адресном пространстве пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер сегмента, а младшие - как номер слова внутри сегмента. Наряду с сегментацией может также использоваться страничная организация памяти. В этом случае виртуальный адрес слова состоит из трех частей: старшие разряды адреса определяют номер сегмента, средние - номер страницы внутри сегмента, а младшие - номер слова внутри страницы.
Как и в случае страничной организации, необходимо обеспечить преобразование виртуального адреса в реальный физический адрес основной памяти. С этой целью для каждого пользователя операционная система должна сформировать таблицу сегментов. Каждый элемент таблицы сегментов содержит описатель (дескриптор) сегмента (поля базы, границы и индикаторов режима доступа). При отсутствии страничной организации поле базы определяет адрес начала сегмента в основной памяти, а граница - длину сегмента. При наличии страничной организации поле базы определяет адрес начала таблицы страниц данного сегмента, а граница - число страниц в сегменте. Поле индикаторов режима доступа представляет собой некоторую комбинацию признаков блокировки чтения, записи и выполнения.
Таблицы сегментов различных пользователей операционная система хранит в основной памяти. Для определения расположения таблицы сегментов выполняющейся программы используется специальный регистр защиты, который загружается операционной системой перед началом ее выполнения. Этот регистр содержит дескриптор таблицы сегментов (базу и границу), причем база содержит адрес начала таблицы сегментов выполняющейся программы, а граница - длину этой таблицы сегментов. Разряды номера сегмента виртуального адреса используются в качестве индекса для поиска в таблице сегментов. Таким образом, наличие базово-граничных пар в дескрипторе таблицы сегментов и элементах таблицы сегментов предотвращает возможность обращения программы пользователя к таблицам сегментов и страниц, с которыми она не связана. Наличие в элементах таблицы сегментов индикаторов режима доступа позволяет осуществить необходимый режим доступа к сегменту со стороны данной программы. Для повышения эффективности схемы используется ассоциативная кэш-память.
Отметим, что в описанной схеме сегментации таблица сегментов с индикаторами доступа предоставляет всем программам, являющимся частями некоторой задачи, одинаковые возможности доступа, т. е. она определяет единственную область (домен) защиты. Однако для создания защищенных подсистем в рамках одной задачи для того, чтобы изменять возможности доступа, когда точка выполнения переходит через различные программы, управляющие ее решением, необходимо связать с каждой задачей множество доменов защиты. Реализация защищенных подсистем требует разработки некоторых специальных аппаратных средств. Рассмотрение таких систем, которые включают в себя кольцевые схемы защиты, а также различного рода мандатные схемы защиты, выходит за рамки данного обзора.
Семейство компьютеров Alpha
Отличительная черта платформы Alpha - это сбалансированность. Благодаря 64-разрядной архитектуре и высокоскоростным каналам связи с периферией Alpha поддерживает работу с огромными массивами данных, как на дисках, так и в оперативной памяти, что является весьма критичным для многих приложений.
Другим отличительным качеством платформы Alpha является ее универсальность с точки зрения применения различных операционных систем. Это и всем известные NetWare и Pick, а также DECelx - операционная система реального времени. OpenVMS, операционная система компьютеров VAX, продолжает свой путь на платформе Alpha. Digital UNIX - UNIX нового поколения, унифицированный, удовлетворяющий стандартам Open Software Foundation (OSF) и обеспечивающий совместимость с BSD и System V, - также функционирует на платформе Alpha, которая поддерживает и операционную систему
Windows NT - продукт Microsoft.
Одним из последних продуктов, выпущенных
Одним из последних продуктов, выпущенных компанией HP, является семейство параллельных систем, представленных в настоящее время двумя моделями ESP21 и ESP30. Основная концепция, лежащая в основе этих систем достаточно проста. Она заключается в создании комбинированной структуры, в которой объединяются возможности и сильные стороны проверенной временем высокопроизводительной симметричной мультипроцессорной обработки с практически неограниченным потенциалом по росту производительности и масштабируемости, который может быть достигнут посредством параллельной архитектуры. Результатом такого объединения является высокопроизводительная архитектура, обеспечивающая чрезвычайно высокую степень распараллеливания вычислений.
В отличие от некоторых других параллельных архитектур, которые используют слабо связанные однопроцессорные узлы, параллельная архитектура серверов ESP21 и ESP30 использует высокопроизводительную SMP-технологию в качестве масштабируемых строительных блоков. Преимущество такого подхода заключается в том, что прикладные системы могут пользоваться вычислительной мощностью и возможностями множества тесно связанных процессоров в инфраструктуре SMP и достаточно эффективно обеспечивать максимально возможную производительность приложений. По мере необходимости дополнительные SMP-модули могут быть добавлены в систему для увеличения степени параллелизма для масштабирования общей производительности системы, ее емкости, пропускной способности в/в, или таких системных ресурсов как основная и дисковая память.
Изделия этой серии предназначены главным образом для обеспечения масштабируемости, превышающей обычные возможности SMP-архитектуры, для крупномасштабных систем принятия решений, систем оперативной обработки транзакций, построения хранилищ данных во Всемирной Паутине Internet. Для большинства приложений модели ESP обеспечивают практически линейный рост уровня производительности. Это достигается посредством использования высокопроизводительной шинной архитектуры SMP узлов ESP в сочетании с возможностями установки дополнительных SMP-узлов с помощью разработанного компанией HP коммутатора оптоволоконных каналов (Fiber Channel Enterprise Switch). Управление всеми ресурсами системы осуществляется с единой консоли управления.
При необходимости обеспечения высокой готовности системы ESP поддерживают специальный слой программных средств MC/ServiceGuard. Эти средства позволяют создать эффективное сочетание свойств высокой производительности, масштабируемости и высокой готовности, и помимо стандартных возможностей RAS (надежности, готовности и удобства обслуживания) обеспечивают замену узлов без останова работы системы.
По сути серия EPS предоставляет средства для объединения моделей класса К (EPS21) и Т(EPS30) в единую систему. 16-канальный коммутатор Fiber Channel позволяет объединить до 64 процессоров в модели EPS21 (до 256 процессоров в будущем) и до 224 процессоров в модели EPS30 (до 768 процессоров в будущем). Общая пиковая пропускная способность систем может достигать уровня 15 Гбайт/с.
Таблица 4.8. Суммарные характеристики системы при использовании
в качестве коммутатора Fibre Channel Enterprise Switch модели 266
| EPS21 | EPS30 | |
| Максимальное число узлов | 16 | 16 |
| Общее количество ЦП | 64 | 224 |
| Пиковая пропускная способность системной шины | 15.68 Гб/с | 15.68 Гб/с |
| Средняя пропускная способность системной шины | 12.28 Гб/с | 12.28 Гб/с |
| Пиковая пропускная способность ввода/вывода | 4.4 Гб/с | 4.1 Гб/с |
| Максимальный объем распределенной памяти | 64 Гб | 64 Гб |
| Максимальный объем распределенной дисковой памяти | 132 Тб | 320 Тб |
Таблица 4.9. Характеристики отдельного узла EPS
| EPS21 | EPS21 | EPS30 | |
| Тип процессора | PA8000 | PA7200 | PA7200 |
| Количество ЦП | 4 | 4 | 14 |
| Тактовая частота | 180 | 120 | 120 |
| Кэш-память команд/данных (Мб) | 1/1 | 1/1 | 1/1 |
| Стандартный объем памяти (Мб) | 128 | 128 | 256 |
| Максимальный объем памяти (Гб) | 4 | 4 | 4 |
| Максимальный объем дисков (Тб) | 8.3 | 8.3 | 20 |
| SPECint95 | 11.8 (1ЦП) | 4.6 (1ЦП) | 5.34 (1ЦП) |
| SPECfp95 | 20.2 (1ЦП) | 8.2 (1ЦП) | 4.35 (1ЦП) |
| SPECrate_int95 | 415 (4ЦП) | 163 (4ЦП) | 531 (12ЦП) |
| SPECrate_fp95 | 400 (4ЦП) | 248 (4ЦП) | 263 (12ЦП) |
Хотя архитектура RISC была разработана
Хотя архитектура RISC была разработана научным сотрудником компании IBM Джоном Куком в 1974 году, первая коммерческая RISC разработка компании (RT/PC} не была принята рынком. Однако появившиеся вслед за этим компьютеры с архитектурой RISC, представленные компаниями Sun Microsystems, Hewlett-Packard и Digital Equipment были намного более успешными и действительно создали рынок RISC/UNIX рабочих станций и серверов. В феврале 1990 года, когда компания IBM поставила свою первую RISC-систему RS/6000, эти три поставщика прочно занимали лидирующие позиции.
В настоящее время семейство RS/6000 компании IBM включает в себя работающие под управлением операционной системы AIX рабочие станции и серверы, построенные на базе суперскалярной архитектуры POWER, расширенной архитектуры POWER2 и архитектуры PowerPC.
Процессоры POWER работают на частоте 33, 41.6, 45, 50 и 62.5 МГЦ. Архитектура POWER включает отдельные кэши команд и данных, 64- или 128-битовую шину памяти и 52-битовый виртуальный адрес. Она также имеет интегрированный процессор плавающей точки и таким образом хорошо подходит для приложений с интенсивными вычислениями, типичными для технической среды, хотя текущая стратегия RS/6000 нацелена как на коммерческие, так и на технические приложения. RS/6000 показывает хорошую производительность на плавающей точке: 134.6 SPECp92 для POWERstation/Powerserver 580. Первая реализация архитектуры POWER появилась на рынке в 1990 году. С тех пор компания IBM представила на рынок еще две версии процессоров POWER2 и POWER2+, обеспечивающих поддержку кэш-памяти второго уровня и имеющих расширенный набор команд. Эти процессоры работают с тактовой частотой 66.7 и 71.5 МГц и применяются в наиболее мощных рабочих станциях и серверах семейства RS/6000.
Для реализации быстрой обработки ввода/вывода в архитектуре POWER используется шина Micro Channel, имеющая пропускную способность 40 или 80 МГбайт/сек. Шина Micro Channel включает 64-битовую шину данных и обеспечивает поддержку работы нескольких главных адаптеров шины. Такая поддержка позволяет сетевым контроллерам, видеоадаптерам и другим интеллектуальным устройствам передавать информацию по шине независимо от основного процессора, что снижает нагрузку на процессор и соответственно увеличивает системную производительность.
Компания IBM распространяет влияние архитектуры POWER в направлении UNIX-систем с помощью платформы PowerPC. Архитектура POWER в этой форме обеспечивает уровень производительности и масштабируемость, превышающие возможности современных систем на платформе Intel. В архитектурном плане основные отличия этих двух разработок заключаются лишь в том, что системы PowerPC используют однокристальную реализацию архитектуры POWER, изготавливаемую компанией Motorola, в то время как большинство выпускавшихся до последнего времени систем RS/6000 использовали многокристальную реализацию. Сегодня уже выпускаются несколько вариаций процессора PowerPC, которые обеспечивают как потребности портативных изделий и настольных рабочих станций, так и достаточно мощных серверов. Первым на рынке появился процессор 601, первоначально предназначавшийся для использования в настольных рабочих станциях компаний IBM и Apple. На базе этого процессора уже построены многие модели рабочих станций и серверов RS/6000 (в том числе и реализующих симметричную мультипроцессорную обработку). Совсем недавно компания IBM представила рабочие станции моделей 42T и 42P, построенные на базе нового мощного процессора PowerPC 604, работающего с тактовой частотой 100, 120 и 133 МГц. В скором времени на рынке должен появиться микропроцессор PowerPC 620, который разработан специально для серверных конфигураций и ожидается, что со своей полностью 64-битовой архитектурой он обеспечит исключительно высокий уровень производительности.
В таблице 4.10 приведены основные характеристики серверов, а в таблице 4.11 многопроцессорных PowerPC SMP-серверов семейства RS/6000.
Семейство UNIXсерверов Escala
На российский рынок в настоящее время активно продвигаются UNIX-серверы семейства Escala - многопроцессорные системы с архитектурой PowerScale, построенные на базе микропроцессора PowerPC 601. Они предлагаются для работы в качестве нескольких типов серверов приложений: сервера транзакций (Transation Server) при использовании мониторов обработки транзакций подобных Tuxedo, сервера базы данных (Database Server) на основе таких известных систем как Oracle или Informix, а также управляющего сервера (System Management Server), обеспечивающего управление инфраструктурой предприятия и существенно упрощающего администрирование гетерогенными системами и сетями. Серверы Escala двоично совместимы с системами Bull DPX/20, а их архитектура разработана с учетом возможности применения новейших процессоров PowerPC 604 и 620.
Основные характеристики серверов Escala в зависимости от применяемого конструктива даны в таблице 4.1. Системы семейства Escala обеспечивают подключение следующих коммуникационных адаптеров: 8-, 16- и 128-входовых адаптеров асинхронных последовательных портов, 1- или 4-входовых адаптеров портов 2 Мбит/с X.25, а также адаптеров Token-Ring, Ethernet и FDDI.
Таблица 4.1
| МОДЕЛЬ Escala | M101 | M201 | D201 | D401 | R201 |
| Mini-Tower | Deskside | Rack-Mounted | |||
| ЦП | |||||
| Тип процессора | PowerPC 601 | ||||
| Тактовая частота (МГц) | 75 | 75 | 75 | 75 | 75 |
| Число процессоров | 1/4 | 2/4 | 2/8 | 4/8 | 2/8 |
| Размер кэша второго уровня (Кб) | 512 | 512 | 1024 | 1024 | 1024 |
| ПАМЯТЬ | |||||
| Стандартный объем (Мб) | 32 | 64 | 64 | 64 | 64 |
| Максимальный объем (Мб) | 512 | 512 | 2048 | 2048 | 2048 |
| ВВОД/ВЫВОД | |||||
| Тип шины | MCA | MCA | MCA | MCA | MCA |
| Пропускная способность (Мб/с) | 160 | 160 | 160 | 2x160 | 2x160 |
| Количество слотов | 6 | 6 | 15 | 15 | 16 |
| Количество посадочных мест | |||||
| 3.5" | 4 | 4 | 7 | 7 | 7 |
| 5.25" | 2 | 2 | 3 | 3 | 3 |
| Емкость внутренней дисковой памяти Гб) |
1/18 | 1/18 | 2/36 | 4/99 | - |
| Емкость внешней дисковой памяти (Гб) |
738 | 738 | 1899 | 1899 | 2569 |
| Количество сетевых адаптеров | 1/4 | 1/4 | 1/12 | 1/12 | 1/13 |
| ПРОИЗВОДИТЕЛЬНОСТЬ (число процессоров 2/4) | |||||
| SPECint92 | 77 | 77 | 77 | 77 | 77 |
| SPECfp92 | 84 | 84 | 84 | 84 | 84 |
| SPECrate_int92 | 3600/6789 | 3600/6789 | 3600/6789 | - /6789 | 3600/6789 |
| SPECrate_fp92 | 3900/7520 | 3900/7520 | 3900/7520 | - /7520 | 3900/7520 |
| Tpm-C | 750/1350 | 750/1350 | 750/1350 | 750/1350 | 750/1350 |
ServerNet
ServerNet представляет собой быструю, масштабируемую, надежную системную сеть, обеспечивающую гибкость соединения большого числа ЦП и периферийных устройств в/в между собой. Главными свойствами этой сети коммутации пакетов являются малая задержка и высокая надежность передачи данных. Для уменьшения задержки в сети применяется метод червячной маршрутизации, не требующий приема всего пакета до его отсылки к следующему приемнику. Физический уровень ServerNet образуют независимые каналы приема и передачи, каждый из которых имеет 9-битовое поле команд/данных и сигнал синхронизации. Поле команд/данных обеспечивает кодирование 256 символов данных и до 20 символов команд. Символы команд используются для управления уровнем звена, инициализации и сигнализации об ошибках. Кодирование в одних и тех же линиях команд и данных сокращает количество контактов и упрощает обнаружение ошибок в логике управления.
Система использует ServerNet для организации связей ЦП-ЦП, ЦП-В/В и В/В-В/В. Пересылки между микропроцессором и памятью для каждого узла ЦП остаются локальными.
Данные в сети ServerNet пересылаются со скоростью 50 Мбайт в секунду. Такая скорость передачи данных была выбрана исходя из того, чтобы превзойти потребности существующих периферийных устройств при соблюдении низких цен. В будущих поколениях ServerNet производительность линий связи будет увеличиваться по мере необходимости.
В настоящее время максимальная длина линии связи ServerNet ограничена 30 м. В будущих адаптерах предполагается увеличение расстояния между узлами ServerNet с помощью последовательных оптоволоконных линий связи. Предполагается, что этот переход будет относительно простым, поскольку все функции управления используют одни и те же линии команд/данных.
Пакеты ServerNet состоят из 8-байтного заголовка, дополнительного 4-байтного адреса, поля данных переменного размера и поля контрольной суммы. Заголовок определяет идентификаторы источника и приемника, объем передаваемых данных и необходимую для выполнения операцию. 4-байтное адресное поле обеспечивает 4-гигабайтное окно в адресном пространстве узла назначения. В устройствах в/в какие-либо механизмы преобразования адресов отсутствуют. ЦП преобразуют адрес из пакета в адрес физической памяти с помощью таблицы удостоверения и преобразования адреса (AVT - Address Validation and Translation Table). AVT проверяет допустимость удаленных обращений к локальной памяти узла. Каждый элемент таблицы обеспечивает доступ по чтению и/или записи одного узла ЦП или узла в/в к данным внутри 4-килобайтного диапазона адресов локальной памяти. С помощью нескольких элементов таблицы AVT узел ЦП может иметь доступ к большим сегментам своей памяти или обеспечивать несколько узлов доступом к одному и тому же сегменту памяти. Неисправный узел может испортить только те сегменты памяти, к которым ЦП предоставил ему доступ. AVT выполняет также преобразование смежных адресов памяти в несмежные адреса страниц физической памяти.
Все транзакции по сети ServerNet происходят в два этапа: выполнение запроса и ожидание соответствующего ответа, который должен вернуться до истечения заданного интервала времени (счетчика таймаута). Все узлы ServerNet поддерживают возможность выдачи несколько исходящих запросов в другие узлы. Помимо стандартных действий в соответствии с протоколом уровня передачи пакетов, получатель определенной транзакции может по своему усмотрению выполнить некоторые локальные действия. Например, существующие в настоящее время узлы ЦП или В/В преобразуют транзакции записи по определенным адресам в локальные прерывания.
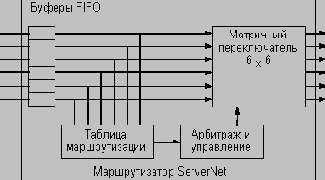
В СБИС маршрутизатора ServerNet реализован матричный переключатель размерностью 6х6. Решение о направлении маршрутизации принимается на основе анализа идентификатора приемника из заголовка пакета. В состав маршрутизаторов входят входные буфера FIFO, логика арбитража и управления потоком данных, реализованная с помощью ЗУПВ таблица маршрутизации и матричный переключатель (см. Рисунок 4.9). Инициализация и реконфигурация сети выполняются программными средствами путем загрузки соответствующих таблиц маршрутизации.
Серверы HP9000 класса D
В секторе рынка серверов рабочих групп компания HP представлена довольно широкой серией систем HP9000 класса D. Это серия систем с относительно низкой стоимостью, которая конкурирует с серверами, построенными на базе ПК. Эти системы базируются на архитектуре процессоров PA-RISC (75 и 100 МГц PA-7100LC, 100 и 120 МГц PA-7200, а также 160 МГц PA-8000) и работают под управлением операционной системы HP-UX.
Модели D200, D210 и D310 представляют собой однопроцессорные системы. Модели D250, D260, D270 и D350 могут оснащаться как одним, так и двумя процессорами. В своих моделях D3XX HP подчеркивает свойства обеспечения высокой готовности: возможность "горячей" замены внутренних дисковых накопителей, возможность организации дискового массива RAID и наличие источника бесперебойного питания. Эти модели обладают также расширенными возможностями по наращиванию оперативной памяти и подсистемы ввода/вывода.
В моделях D2XX имеется 5 гнезд расширения ввода/вывода и 2 отсека для установки дисковых накопителей с интерфейсом SCSI-2. В моделях D3XX количество гнезд расширения ввода/вывода расширено до 8, в 5 отсеках могут устанавливаться дисковые накопители с интерфейсом Fast/Wide SCSI-2, которые допускают замену без выключения питания системы.
Старшие модели серии обеспечивают возможность расширения оперативной ECC-памяти до 1.5 Гбайт, при этом коэффициент расслоения может увеличиваться до 12. Максимальный объем дискового пространства при использовании внешних дисковых массивов может достигать 5.0 Тбайт.
Пиковая пропускная способность системной шины составляет 960 Мбайт/с. Все модели оснащаются высокоскоростными шинами в/в HP-HSC (high speed connect) с пропускной способностью 160 Мбайт/с. Установка двух HP-HSC в моделях D3XX обеспечивает удвоение пропускной способности ввода/вывода этих систем (до 320 Мбайт/с). В таблицах 4.3 и 4.4 приведены основные характеристики серверов класса D.
Таблица 4.3. Основные характеристики серверов HP 9000 класса D
| МОДЕЛЬ | D200/ D210 | D250 | D260 | D270 | D310 | D350 |
| ЦП | ||||||
| Тип процессора | PA7100LC | PA7200 | PA7200 | PA8000 | PA7100LC | PA7200 |
| Тактовая частота (МГц) | 75(D200) 100(D210) | 100 | 120 | 160 | 100 | 100 |
| Число процессоров | 1 | 1-2 | 2 | 1-2 | 1 | 1-2 |
| Пропускная способность системной шины (Мб/сек) | 960 | 960 | 960 | 960 | 960 | 960 |
| Размер кэша (Кб) (команд/данных) | 256 | 256/256 | 1024/1024 | 512/ 512 | 256 | 256/256 |
| ПАМЯТЬ | ||||||
| Минимальный объем (Мб) | 32 | 32 | 128 | 64 | 32 | 32 |
| Максимальный объем (Гб) | 0.5 | 1.5 | 1.5 | 1.5 | 0.5 | 1.5 |
| ВВОД/ВЫВОД | ||||||
| Тип шины | HP-HSC | HP-HSC | HP-HSC | HP-HSC | HP-HSC | HP-HSC |
| Количество слотов | 5 1EISA 1HSC 3EISA/ HSC Comb |
5 1EISA 1HSC 3EISA/ HSC Comb |
5 1EISA 1HSC 3EISA/ HSC Comb |
5 1EISA 1HSC 3EISA/ HSC Comb |
8 1EISA 1HSC 3EISA/ HSC Comb |
8 3EISA 3EISA/ HSC Comb |
| Максимальная пропускная способность подсистемы в/в (Мб/сек) | 160 | 160 | 160 | 160 | 320 | 320 |
| Количество отсеков для дисков Fast/Wide SCSI-2 | 2(Opt) | 2(Opt) | 2(Opt) | 2(Opt) | 5 | 5 |
| Количество отсеков для дисков SCSI-2 | 2 | 2 | 2 | 2 | - | - |
| Количество отсеков для НМЛ и CD-ROM | 3 | 3 | 3 | 3 | 3 | 3 |
| Максимальная емкость дисковой памяти (Tб) | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| Количество последовательных портов | 2 | 2 | 2 | 2 | 2 | 2 |
| Количество параллельных портов | 1 | 1 | 1 | 1 | 1 | 1 |
| Сетевые интерфейсы | Ethernet | Ethernet | Ethernet | Ethernet | Ethernet | Ethernet |
Таблица 4.4. Производительность серверов HP9000 класса D
| 1 ЦП PA7100LC 75 Мгц D200 |
1 ЦП PA7100LC 100 Мгц D210/310 |
1 ЦП PA7200 100 Мгц D250/350 |
1 ЦП PA8000 160 Мгц D270/370 |
2 ЦП PA7200 100 Мгц D250/350 |
2 ЦП PA7200 120 Мгц D260/360 |
2 ЦП PA8000 160 Мгц D270/370 |
|
| SPECint95 | 2.2 | 2.9 | 3.6 | 10.4 | - | - | - |
| SPECfp95 | 2.9 | 3.7 | 6.1 | 17.9 | - | - | - |
| SPECrate_int95 | 19.2 | 26.5 | 32.5 | 90 | 64.5 | 81.4 | 180 |
| SPECrate_fp95 | 25.8 | 33.3 | 55.1 | 150 | 97.4 | 131 | 240 |
| tpmC | - | - | - | - | - | - | 5822 |
Серверы HP9000 класса K
Серверы HP9000 класса K представляют собой системы среднего класса, поддерживающие симметричную мультипроцессорную обработку (до 4 процессоров). Также как и системы класса D они базируются на архитектуре PA-RISC (120 МГц PA-7200 с кэш-памятью команд/данных первого уровня 256/256 Кбайт или 1/1 Мбайт, а также 160 и 180 МГц PA-8000 с кэш-памятью команд/данных первого уровня 1/1 Мбайт, работающей на тактовой частоте процессора).
Конструкция серверов класса К обеспечивает высокую пропускную способность систем. Основными компонентами поддержания высокой производительности являются системная шина с пиковой пропускной способностью 960 Мбайт/с, большая оперативная память с контролем и исправлением одиночных ошибок (ECC) емкостью до 4 Гбайт c 32-кратным расслоением, многоканальная подсистема ввода/вывода с пропускной способностью до 288 Мбайт/с, стандартная высокоскоростная шина Fast/Wide Differential SCSI-2, а также дополнительные возможности по подключению высокоскоростных сетей и каналов типа FDDI, ATM и Fibre Channel.
В конструкции сервера предусмотрены 4 отсека для установки дисковых накопителей, а с помощью специальных стоек (кабинетов) расширения емкость дисковой памяти системы может быть доведена до 8.3 Тбайт. Основные параметры серверов HP9000 класса К представлены в таблицах 4.5 и 4.6.
Таблица 4.5. Производительность серверов HP9000
| 1 ЦП K210 K410 |
1 ЦП K220 K420 |
1 ЦП K250 K450 |
1 ЦП K260 K460 |
|
| SPECint95 | 4.4 | 4.6 | 10.8 | 11.8 |
| SPECfp95 | 7.4 | 8.2 | 18.4 | 20.2 |
| SPECrate_int95 | 39.7 | 41.3 | 95.0 | 107.0 |
| SPECrate_fp95 | 66.6 | 73.2 | 160.0 | 180.0 |
| 2 ЦП K210 K410 |
2 ЦП K220 K420 |
2 ЦП K250 K450 |
2 ЦП K260 K460 |
|
| SPECrate_int95 | 77.2 | 82.1 | 190.0 | 210.0 |
| SPECrate_fp95 | 127.0 | 142.0 | 260.0 | 300.0 |
| 4 ЦП K210 K410 |
4 ЦП K220 K420 |
4 ЦП K250 K450 |
4 ЦП K260 K460 |
|
| SPECrate_int95 | 152.0 | 163.0 | 390.0 | 415.0 |
| SPECrate_fp95 | 217.0 | 248.0 | 380.0 | 400.0 |
| tpmC | - | - | 11580 | 12320 |
| LADDIS (IOPS) | - | - | - | 9572 |
Таблица 4.6. Основные характеристики серверов HP 9000 класса K
| МОДЕЛЬ | K210 | K220 | K250 | K260 | K410 | K420 | K450 | K460 |
| ЦП | ||||||||
| Тип процессора | PA7200 | PA7200 | PA8000 | PA8000 | PA7200 | PA7200 | PA8000 | PA8000 |
| Тактовая частота (МГц) | 120 100(D210) |
120 | 160 | 180 | 120 | 120 | 160 | 180 |
| Число процессоров | 1-4 | 1-4 | 1-4 | 1-4 | 1-4 | 1-4 | 1-4 | 1-4 |
| Пропускная способность системной шины (Мб/сек) | 960 | 960 | 960 | 960 | 960 | 960 | 960 | 960 |
| Размер кэша (Кб) (команд/данных) | 256/ 256 |
1024/ 1024 |
1024/ 1024 |
1024/ 1024 |
256/ 256 |
1024/ 1024 |
1024/ 1024 |
1024/ 1024 |
| ПАМЯТЬ | ||||||||
| Минимальный объем (Мб) | 64 | 128 | 128 | 128 | 128 | 128 | 128 | 128 |
| Максимальный объем (Гб) | 2.0 | 2.0 | 2.0 | 2.0 | 3.0 | 3.0 | 4.0 | 4.0 |
| ВВОД/ВЫВОД | ||||||||
| Количество слотов HP-HSC |
1 | 1 | 1 | 1 | 5 | 5 | 5 | 5 |
| Количество слотов HP-PB | 4 | 4 | 4 | 4 | 8 | 8 | 8 | 8 |
| Максимальная пропускная способность подсистемы в/в (Мб/сек) | 288 | 288 | 288 | 288 | 288 | 288 | 288 | 288 |
| Количество отсеков для дисков Fast/Wide SCSI-2 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Максимальная емкость дисковой памяти (Tб) | 3.8 | 3.8 | 3.8 | 3.8 | 8.3 | 8.3 | 8.3 | 8.3 |
| Количество последовательных портов | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Количество параллельных портов | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Сетевые интерфейсы | Ethernet | Ethernet | Ethernet | Ethernet | Ethernet | Ethernet | Ethernet | Ethernet |
Серверы компании DEC
Корпорация Digital Equipment (далее по тексту - Digital) широко известна в мире и является одной из крупнейших компьютерных компаний, компьютеры которой остаются популярными уже в течение почти 40 лет (начиная с ее основания в 1957 году и выпуска первых машин PDP-1 в 1960 г.).
Продукция Digital чрезвычайно разнообразна и включает в себя следующие основные направления: компьютерную технику - от персональных компьютеров до мощных информационных центров; телекоммуникационные устройства для локальных и распределенных сетей и для всех видов передающей физической среды - от коннекторов, осуществляющих физическое соединение различных устройств, до мощных высокоскоростных модульных концентраторов, включающих в себя маршрутизаторы, мосты, шлюзы, повторители и др.; периферийные устройства, принтеры, мультимедиа; программное обеспечение, включающее операционные системы, сетевые программные средства, системы электронной почты и электронного обмена данными, распределенную офисную среду, средства разработки приложений и др.
Компания Digital широко известна своими сериями мини-ЭВМ PDP-11 и VAX, работающими под управлением операционных систем RSX11M и VMS соответственно. Имея огромную базу установленных по всему миру систем этого типа, компания Digital вынуждена ее поддерживать и в настоящее время выпускает целый ряд совместимых с PDP и VAX изделий. Однако понимая необходимость перехода на стандарты открытых систем Digital разработала новую стратегию, ключевым камнем которой является новая технология, основанная на 64-битовой суперскалярной архитектуре Alpha.
В настоящее время корпорация Digital сконцентрировала основные усилия на разработке и производстве современных 64-разрядных RISC-систем. Новейший микропроцессор Alpha DECchip 21164 на сегодня является самым быстрым микропроцессором. Архитектура Alpha полностью сохраняет преемственность поколений компьютеров: практически все программное обеспечение ЭВМ VAX работает и на новых системах Alpha.
Кроме того, в течение последних лет корпорация Digital применяет свой огромный опыт для производства персональных компьютеров, которые завоевывают все более прочное положение на современном рынке.
Серверы компании HewlettPackard
Компания Hewlett-Packard была учреждена в Калифорнии в 1938 году с целью создания электронного тестирующего и измерительного оборудования. В настоящее время компания разрабатывает, производит, осуществляет маркетинг и сервис систем для коммерческих приложений, автоматизации производственных процессов, процессов разработки, тестирования и измерений, а также аналитические и медицинские инструменты и системы, периферийное оборудование, калькуляторы и компоненты для использования в широком ряде отраслей промышленности. Она продает более 4500 изделий, используемых в промышленности, бизнесе, науке, образовании, медицине и инженерии.
Основой разработки современных компьютеров Hewlett-Packard является архитектура PA-RISC. Она была разработана компанией в 1986 году, и с тех пор, благодаря успехам интегральной технологии, прошла несколько стадий своего развития от многокристального до однокристального исполнения. Архитектура PA-RISC разрабатывалась с учетом возможности построения многопроцессорных систем, которые реализованы в старших моделях серверов.
Серверы компании IBM
Несмотря на пережитые в последние годы финансовые трудности, корпорация IBM остается самой большой и мощной компьютерной компанией в мире. Ее присутствие ощущается буквально на всех направлениях развития компьютерного рынка: от чисто научно-исследовательских работ до разработки и производства кристаллов, от производства персональных компьютеров до создания самых мощных систем класса "мейнфрейм". В последние годы для компании характерно резкое расширение распространения программных продуктов собственного производства и сервисных услуг по созданию и поддержке крупных информационных систем.
Серверы компании Silicon Graphics
Компания Silicon Graphics (SGI) была создана в 1981 году. Основным направлением работы компании в течение многих лет было создание высокопроизводительных графических рабочих станций. В настоящее время ее интересы распространяются на рынок высокопроизводительных вычислений как для технических, так и для коммерческих приложений. В частности она концентрирует свои усилия на разработке и внедрении современных технологий визуализации вычислений, трехмерной графики, обработки звука и мультимедиа.
Отчет независимой аналитической организации IDC 1995 года показал, что в период 1994 календарного года SGI оказалась самой быстро растущей компанией-поставщиком UNIX-систем. Правда она еще далеко отстает от лидеров (HP и Sun) по общему количеству поставок систем и доходу. (Например, в течение этого же периода SGI осуществила поставку 65000 систем, в то время как Sun увеличила на это число количество своих поставок). Silicon Graphics сохраняет лидирующие позиции на рынке суперкомпьютеров отделов, занимая 36% этого рынка и более чем вдвое опережая своего ближайшего конкурента. Недавно она приобрела известную компанию Cray Research и теперь расширяет свое присутствие на рынке суперкомпьютеров.
Разработка процессора R10000 позволила компании перейти к объединению своих серверов Challenge (на базе процессора R4000) и PowerChallenge (на базе процессора R8000) в единую линию изделий. Благодаря повышенной производительности этого процессора на целочисленных операциях и плавающей точке обе линии продуктов могут быть слиты без потери производительности.
Все высокопроизводительные серверы SGI обладают рядом средств по поддержанию свойств RAS (надежности, готовности и удобства обслуживания), в частности, обеспечивают автоматическое восстановление системы после сбоя и подключение источников бесперебойного питания.
Серверы Silicon Graphics работают под управлением операционной системы IRIX - ОС UNIX реального времени, построенной в соответствии с требованиями стандартов SVID (System V Interface Definition) и XPG4. Она поддерживает возможность работы нескольких машин на одном шлейфе SCSI (multi-hosted SCSI), 4-кратное зеркалирование и 128-кратное расщепление дисковых накопителей. На платформе поддерживаются многие продукты компаний Oracle, Informix и Sybase.
Основные характеристики серверов компании Silicon Graphics приведены в таблице 4.12.
Таблица 4.12.
| МОДЕЛЬ Challenge | S | DM | L | XL |
| ЦП | ||||
| Тип процессора | MIPS R4400 MIPS R4600 MIPS R5000 |
MIPS R4400 | MIPS R10000 | MIPS R10000 |
| Тактовая частота (МГц) | 200 | 200 | 200 | 200 |
| Число процессоров | 1 | 1-4 | 2-12 | 2-36 |
| Системная шина (Мбайт/с) | 267 | 1200 | 1200 | 1200 |
| Разрядность шины (бит) данных/адреса |
- | 256/40 | 256/40 | 256/40 |
| Размер кэша: | ||||
| L1 (команды/данные)(Кб) | 16/16 (R4400,R4600) 32/32 (R5000) | 16/16 | 32/32 | 32/32 |
| L2 (Мб) | 1 (R4400) 0.5 (R5000) |
1-4 | 1-4 | 1-4 |
| ПАМЯТЬ ECC | ||||
| Минимальный объем (Мб) | 32 | 64 | 64 | 64 |
| Максимальный объем (Гб) | 0.256 | 6 | 6 | 16 |
| Расслоение | 1,2 | 1,2,4 | 1,2,4 | 1,2,4,8 |
| ВВОД/ВЫВОД | ||||
| Тип фирменной шины | SGI GIO | SGI HIO | SGI HIO | SGI HIO |
| Пропускная способность(Мб/с) | 267 | 320/HIO | 320/HIO | 320/HIO |
| Количество шин | 1 | 1-3 | 1-3 | 1-6 |
| Количество слотов | 2 GIO | 2-6 HIO | 2-6 HIO | 2-12 HIO |
| Тип стандартной шины | - | VME64 | VME64 | VME64 |
| Пропускная способность стандартной шины (Мб/с) |
- | 50 | 50 | 50 |
| Количество стандартных шин | - | 1 | 1 | 1-5 |
| Количество слотов стандартной шины |
- | 5 | 5 | 5-25 |
| Периферийные интерфейсы | Fast/Wide SCSI-2 |
Fast/Wide SCSI-2 | Fast/Wide SCSI-2 | Fast/Wide SCSI-2 |
| Максимальная емкость дисковой памяти |
277 Гб | 10.0Тб (RAID) |
10.0Тб (RAID) |
17.4Тб (RAID) |
Серверы компании Sun Microsystems
Компания Sun Microsystems основана в 1982 году и к настоящему времени является одной из трех крупнейших компаний-поставщиков на рынке высокопроизводительных рабочих станций и серверов.
С самого начала своей деятельности Sun придерживалась концепции проектирования открытых систем. Ее первые изделия базировались на семействе микропроцессоров Motorola 680X0 и частично на микропроцессорах Intel и работали под управлением собственной версии операционной системы UNIX - SunOS. Компания разработала сетевой протокол NFS, который стал промышленным стандартом и используется практически всеми компаниями-производителями вычислительных систем. С 1987 года компания взяла на вооружение концепцию компьютеров с сокращенным набором команд (RISC), разработав собственную архитектуру SPARC - Scalable Processor Architecture.
В настоящее время семейство рабочих станций и серверов компании Sun Microsystems включает в себя однопроцессорные и многопроцессорные системы, построенные на базе собственной архитектуры SPARC RISC и работающие под управлением операционной системы Solaris (SunOS 5).
Используя только процессоры SPARC в своих новейших рабочих станциях и серверах, Sun сохраняет контроль за развитием своей процессорной технологии, обеспечивает двоичную совместимость (прикладные пакеты, разработанные для одной рабочей станции SPARCstation или сервера, могут работать без каких-либо изменений на других рабочих станциях и серверах), а также масштабируемость (системы SPARC компании Sun обеспечивают ясную, модульную линию перехода от малых настольных станций до больших серверов).
Концепция открытых систем компании включает такие компоненты как: открытую архитектуру (SPARC и высокоскоростную шину S-bus; в настоящее время имеется 64-битовая версия S-bus), открытое системное программное обеспечение (UNIX System V Release 4, стандартные инструментальные средства и языки программирования, а также DOS), открытые интерфейсы прикладных программ (Open Look, Motif, X.11/NeWS, OpenFonts) и открытую среду сетевых вычислений (ONC+, NFS, SunLink и SunNet).
Компания обеспечивает средства связи своих систем с компьютерами класса mainframe и миникомпьютерами других фирм и работу в больших корпоративных средах. Операционная среда Solaris позволяет прикладным пакетам, ориентированным на UNIX, работать на аппаратных платформах SPARC, PowerPC и Intel (на этих платформах используется версия Solaris 2.5). Текущая версия Solaris 2.5 поддерживает симметричную многопроцессорную обработку, многопотоковую обработку, связанные с ней прикладные системы DeskSet и ToolTalk (объектно-ориентированную систему разработки, которая будет объединена с COSE, недавно согласованную общую операционную среду), обеспечивает поддержку NetWare и всех основных стандартов SVR4 (POSIX, XPG/3 и SVID).
Компания Sun Microsystems поставляет широкий ряд серверов, способных удовлетворить потребностям самых взыскательных пользователей. Основными принципами компании при построении серверов являются:
Строгая приверженность промышленным стандартам и стандартам открытых систем, позволяющая легко осуществлять интеграцию и связь не только среди собственных изделий компании, но и с компьютерным оборудованием практически всех ведущих фирм. Гибкость конструктивных решений, обеспечивающая простую и удобную линию наращивания производительности путем увеличения количества процессоров, объемов оперативной памяти, емкости дисков, количества и типов сетевых адаптеров. Двоичная совместимость начиная с простых настольных систем и кончая высокопроизводительными центрами обработки данных, дающая возможность легко разрабатывать и переносить прикладные программы с системы на систему без дополнительных затрат. Гибкие средства управления системой, упрощающие управление сложными сетями, включающими сети Novell NetWare, Banyan VINES или AppleTalk. Средства высокой готовности, предусматривающие автоматическую реконфигурацию системы в случае отказа компонентов, использование дисковых массивов RAID и возможность построения кластеров, обеспечивающих работу с параллельными базами данных, а также снижающих неплановое и плановое время простоя систем.Серверы рабочих групп строятся на базе SPARCserver 4, SPARCserver 5 и SPARCserver 20, выпускающихся в настольных конструктивах, совпадающих с конструкциями соответствующих рабочих станций. Характеристики этих серверов, а также характеристики серверов масштаба предприятия представлены в табл. 4.13-4.15.
Серверы на базе Alpha
Семейство серверов Alpha представляет собой полный ряд систем: от минимальной конструкции до сервера крупной распределенной сети. Ниже дано описание основных свойств этих компьютеров и средств их реализации.
Высокая надежность и доступность:
"Горячее" переключение дисков, т.е. внутренний диск может быть заменен во время работы сервера. Код коррекции ошибок (ECC, Error Correcting Code). Серверы Alpha включают ECC для основной и кэш- памяти. При использовании этой технологии происходит постоянная проверка памяти, причем при этом ошибки не только обнаруживаются, но и автоматически корректируются. Технология дублирования дисков (Redundant Array of Inexpensive Disks, RAID) Двойная шина SCSI. Дублирование источников питания. Автоматический перезапуск системы. При сбое в операционной системе эта возможность минимизирует время недоступности системы. Управление температурным режимом. Системы AlphaServer включают температурные и другие датчики, позволяющие следить за состоянием системы.Открытая архитектура:
Шина PCI, обеспечивающая скорость передачи 132 Мб/с и соответствие международным стандартам. Стандартные слоты EISA, предоставляющие возможность использования большого количества стандартных карт. Высокоскоростной интерфейс SCSI-2 для подключения до 7 периферийных устройств, обеспечивающие в два раза более высокую скорость передачи шины SCSI и возможность подключения различных стандартных периферийных устройств. Сетевые опции, включающие Ethernet, Token Ring, FDDI.Средства управления:
Реализация удаленного управления. Расширенные средства диагностики. Получение информации о конфигурации системы. Программное обеспечение управления нестандартными ситуациями и журналы диагностики сбоев.Расширяемость/наращиваемость:
Возможность обновления процессора ("upgrade"). Возможность подключения внешней памяти. Использование симметричной мультипроцессорной обработки (Symmetric Multi-Processing, SMP), позволяющей добавлять дополнительные процессоры. Гибкость выбора операционной системы (OpenVMS AXP, Digital UNIX, Microsoft Windows NT).Использование кластеров:
Возможность построения кластерных систем.Основные характеристики серверов AlphaServer представлены в таблице 4.2.
Таблица 4.2.
| Система/ Характеристики |
AlphaServer 400 |
AlphaServer 1000 |
AlphaServer 2000 |
AlphaServer 2100 |
AlphaServer 8200 |
AlphaServer 8400 |
| Частота | 166 МГц | 233 МГц | 4/275:275 МГц | 5/250:250 МГц | 300 Мгц 4/233:233 МГц |
300 МГц 4/275:275 МГц 4/200:200 МГц |
| Число процессоров |
1 | 1 | 1-2 | 1-4 | 1-6 | 1-12 |
| Число транзакций в секунду (TpsA) | До 130 | До 300 | 4/275:До 625 4/233:До 400 | 5/250:До 1200 4/275:До 850 4/200:До 675 | Свыше 2000 | Свыше 3000 |
| Максимальная память | 192 Мб | 512 Мб | 4/275: 1 Гб 4/233:640 Мб | 2 Гб | 6 Гб | 14 Гб |
| Память на диске |
441 Гб | 220 Гб | Свыше 500Гб | 500 Гб | 10 Тб | 10 Тб |
| Поддержка ввода/вывода | 2 слота PCI 3 слота EISA 1 слот PCI/EISA |
2 слота PCI 7 слотов EISA |
3 слота PCI 7 слотов EISA |
3 слота PCI 8 слотов EISA |
108 слотов PCI 8 слотов EISA |
144 слота PCI 8 слотов EISA 1 слот PCI/EISA |
| ECC память | Нет | Да | Да | Да | Да | Да |
| RAID | Да | Да | Да | Да | Да | Да |
| Авто перезагрузка |
Да | Да | Да | Да | Да | Да |
| Дублирование питания | Нет | Да | Да | Да | Да | Да |
| Управление температурой | Нет | Да | Да | Да | Да | Да |
Серверы серии 500 базируются на
Серверы серии 500 базируются на комбинации многокристальной технологии POWER2 и шинной архитектуре MicroChannel. Эти однопроцессорные системы обеспечивают высокий уровень производительности при решении вычислительных задач и задач оперативной обработки транзакций.
Таблица 4.11. Основные характеристики SMP-серверов RS/6000 на базе PowerPC
| МОДЕЛЬ | G40 | J40 | |||||
| ЦП | |||||||
| Тип процессора | PowerPC604 | PowerPC604 | |||||
| Тактовая частота (Мгц) | 112 | 112 | 112 | 112 | 112 | 112 | 112 |
| Число процессоров | 1 | 2 | 4 | 2 | 4 | 6 | 8 |
| Системная шина (бит) | 64 | 64 | 64 | 64 | 64 | 64 | 64 |
| Размер кэша: | |||||||
| L1 (команды/данные) (Кб) | 16/16 | 16/16 | 16/16 | 16/16 | 16/16 | 16/16 | 16/16 |
| L2 (Мб) | 0.5 | 0.5 | 0.5 | 1 | 1 | 1 | 1 |
| ПАМЯТЬ | |||||||
| Минимальный объем (Мб) | 64 | 64 | 64 | 128 | 128 | 128 | 128 |
| Максимальный объем (Мб) | 1024 | 1024 | 1024 | 2048 | 2048 | 2048 | 2048 |
| ВВОД/ВЫВОД | |||||||
| Количество слотов | 5MCA | 5MCA | 5MCA | 6MCA | 6MCA | 6MCA | 6MCA |
| Периферийные интерфейсы | Fast/Wide SCSI-2 | Fast/Wide SCSI-2 | |||||
| Максимальная емкость внутренних дисков (Гб) |
13.5 | 13.5 | 13.5 | 36 | 36 | 36 | 36 |
| Максимальная емкость дисковой памяти (Гб) |
350 | 350 | 350 | 99 | 99 | 99 | 99 |
| ПРОИЗВОДИТЕЛЬНОСТЬ | |||||||
| SPECint_rate95 | 33.6 | 66.5 | 122.0 | 71.9 | 138.0 | 205.0 | 258.0 |
| SPECfp_rate95 | 28.2 | 53.3 | - | 57.3 | 107.0 | 159.0 | 200.0 |
| SPECint_base_rate95 | 32.2 | 60.6 | 110.0 64.9 | 129.0 | 195.0 | 244.0 | |
| SPECfp_Base_rate95 | 26.9 | 50.7 | - | 53.4 | 102.0 | 154.0 | 189.0 |
| tpmC | - | - | - | - | - | - | 5774 |
| $/tpmC | - | - | - | - | - | - | 243 |
Использование специального пакета HACMP/6000 for AIX дает возможность создания кластера, объединяющего до 8 систем серии 500.
В состав модели 591 входит микропроцессор 77 МГц POWER2, интегрированный сдвоенный процессор плавающей точки и четырехсловная система памяти с многоразрядной шиной, обеспечивающая быструю пересылку больших блоков данных. В эту систему включены также 16-битовый контроллер Fast/Wide SCSI-2, дисковый накопитель объемом 2 Гбайт и 4-скоростной считыватель компакт-дисков.
Модель 590 отличается от модели 591 лишь использованием менее скоростного процессора (66 МГц POWER2), что обеспечивает более низкую стоимость системы.
В стандартную поставку модели 59H входит кэш-память второго уровня емкостью
1 Мбайт. Эта система обеспечивает наивысшую производительность в серии 500 при выполнении приложений оперативной обработки транзакций.
Схема неконвейерного целочисленного
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Существуют три класса конфликтов:
-
Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Схема организации доступа к памяти
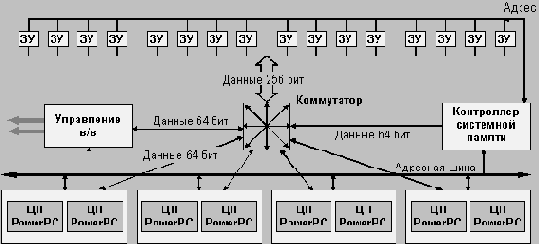
Процессор PowerPC определяет слабо упорядоченную модель памяти, которая позволяет оптимизировать использование пропускной способности памяти системы. Это достигается за счет того, что аппаратуре разрешается переупорядочивать операции загрузки и записи так, что требующие длительного времени операции загрузки могут выполняться ранее определенных операций записи. Такой подход позволяет уменьшить действительную задержку операций загрузки. Архитектура PowerScale полностью поддерживает эту модель памяти как на уровне процессора за счет набора команд PowerPC, так и глобально путем реализации следующих ограничений:
Обращения к глобальным переменным синхронизации выполняются строго последовательно. Никакое обращение к переменной синхронизации не выдается процессором до завершения выполнения всех обращений к глобальным данным. Никакие обращения к глобальным данным не выдаются процессором до завершения выполнения предыдущих обращений к переменной синхронизации.Для обеспечения подобной модели упорядоченных обращений к памяти на уровне каждого процессора системы используются определенная аппаратная поддержка и явные команды синхронизации. Кроме того, на системном уровне соблюдение необходимых протоколов для обеспечения упорядочивания обращений между процессорами или между процессорами и подсистемой ввода/вывода возложено на программное обеспечение.
Симметричные многопроцессорные серверы HP9000 класса Т
Самым мощным и расширяемым рядом корпоративных серверов компании HP на базе ОС UNIX является семейство HP9000 класса T. Это следующее поколение серверов, которое было разработано компанией вслед за HP9000 model 870. В начале на рынке появились системы HP9000 T500, допускающие установку до 12 процессоров PA7100, затем HP объявила 14-процессорные системы T520, построенные на базе процессора 120 МГц PA7150. В настоящее время объявлены 12-процессорные системы Т600 на базе процессора PA-8000, поставки которых должны начаться в 1997 году. Существующие системы (Т500 и Т520) допускают замену старых процессоров на процессоры PA-8000.
Характерной особенностью архитектуры серверов класса Т является большая емкость кэш-памяти команд (1 Мбайт) и данных (1 Мбайт) у каждого процессора системы. Серверы класса T используют 64-битовую шину с расщеплением транзакций, которая поддерживает до 14 процессоров, работающих на частоте 120 МГц. Эффективность этой шины, как и шины Runway, составляет 80%, что обеспечивает в установившемся режиме пропускную способность 768 Мбайт/с при пиковой производительности 960 Мбайт/с.
Серверы класса T могут поддерживать до 8 каналов HP-PB (HP Precision Bus), работающих со скоростью 32 Мбайт/с, однако в стойке основной системы поддерживается только один канал HP-PB. Для обеспечения полной конфигурации подсистемы ввода/вывода необходима установка 7 стоек расширения, занимающих достаточно большую площадь. Общая пиковая полоса пропускания подсистемы в/в в полностью сконфигурированной 8-стоечной системе составляет 256 Мбайт/с, что меньше полосы пропускания подсистемы в/в серверов класса К. Однако максимальная емкость дисковой памяти при использовании RAID-массивов достигает 20 Тбайт.
Указанная двухярусная шинная структура сервера обеспечивает оптимальный баланс между требованиями процессоров и подсистемы ввода/вывода, гарантируя высокую пропускную способность системы даже при тяжелой рабочей нагрузке. Доступ процессоров к основной памяти осуществляется посредством мощной системной шины процессор-память, поддерживающей когерентное состояние кэш-памятей всей системы. В будущих системах планируется 4-кратное увеличение пропускной способности подсистемы ввода/вывода.
Для защиты от отказов питания может применяться устанавливаемая в стойку система бесперебойного питания HP PowerTrust. Основные характеристики серверов класса Т приведены в таблице 4.7.
Таблица 4.7. Основные характеристики серверов HP 9000 класса T
| МОДЕЛЬ | T500 | T520 | T600 |
| ЦП | |||
| Тип процессора | PA7100 | PA7200 | PA8000 |
| Тактовая частота (МГц) | 90 | 120 | 180 |
| Число процессоров | 1-12 | 1-14 | 1-12 |
| Пропускная способность системной шины (Мб/сек) | 960 | 960 | 960 |
| Размер кэша (Кб) (команд/данных) | 1024/1024 | 1024/1024 | 1024/1024 |
| ПРОИЗВОДИТЕЛЬНОСТЬ | |||
| SPECint92 | 135.7 | 160.3 | - |
| SPECfp92 | 221.2 | 222.6 | - |
| SPECrate_int92 | 3286- 23717 |
4112- 39038 |
- - |
| SPECrate_fp92 | 5232- 38780 |
5243- 51057 |
- |
| tpmC | - | 7000 | 15000 |
| ПАМЯТЬ | |||
| Минимальный объем (Мб) | 256 | 256 | 256 |
| Максимальный объем (Гб) | 3.75 | 3.75 | 3.75 |
| ВВОД/ВЫВОД | |||
| Количество слотов HP-HSC | 1 | 1 | 1 |
| Количество слотов HP-PB | 4 | 4 | 4 |
| Максимальная пропускная способность подсистемы в/в (Мб/сек) | 288 | 288 | 288 |
| Максимальная емкость дисковой памяти (Tб) |
20 | 20 | 30 |
| Количество последовательных портов |
16 | 16 | 16 |
| Сетевые интерфейсы | Ethernet | Ethernet | Ethernet |
Симметричные мультипроцессорные системы компании Bull
Группа компаний, объединенных под общим названием Bull, является одним из крупнейших производителей информационных систем на мировом компьютерном рынке и имеет свои отделения в Европе и США. Большая часть акций компании принадлежит французскому правительству. В связи с происходившей в последнем пятилетии перестройкой структуры компьютерного рынка компания объявила о своей приверженности к направлению построения открытых систем. В настоящее время компания продолжает выпускать компьютеры класса мейнфрейм (серии DPS9000/900, DPS9000/800, DPS9000/500) и среднего класса (серии DPS7000 и DPS6000), работающие под управлением фирменной операционной системы GCOS8, UNIX-системы (серии DPX/20, Escala), а также широкий ряд персональных компьютеров компании Zenith Data Systems (ZDS), входящей в группу Bull.
Активность Bull в области открытых систем сосредоточена главным образом на построении UNIX-систем. В результате технологического соглашения с компанией IBM, в 1992 году Bull анонсировала ряд компьютеров DPX/20, базирующихся на архитектуре POWER, а позднее в 1993 году на архитектуре PowerPC и работающих под управлением операционной системы AIX (версия системы UNIX компании IBM). Версия ОС AIX 4.1, разработанная совместно специалистами IBM и Bull, поддерживает симметричную многопроцесоорную обработку.
Архитектура PowerScale, представляет собой первую реализацию симметричной мультипроцессорной архитектуры (SMP), разработанной Bull специально для процессоров
PowerPC. В начале она была реализована на процессоре PowerPC 601, но легко модернизируется для процессоров 604 и 620. Эта новая SMP-архитектура используется в семействе систем Escala.
Система обслуживания
Основные функции системы обслуживания включают инсталляцию системы, формирование сообщений об ошибках, диагностику и управление средствами контроля питающих напряжений и температурных режимов работы. Системой обслуживания управляют два сервисных процессора (SP), которые размещаются в каждой стойке и работают как специализированные контроллеры в/в ServerNet. SP, размещенные в разных стойках, также связаны друг с другом посредством ServerNet.
Система обслуживания использует специальную систему независимых шин. Эти шины базируются на двух стандартных для промышленности интерфейсах: SPI (Serial Peripheral Interconnect) компании Motorola и систему сканирования в стандарте IEEE 1149.1 JTAG. SPI используется в качестве недорогой последовательной шины в/в для связи со всеми средствами контроля и управления состоянием окружающей среды. Система обслуживания использует средства сканирования для управления, инициализации, тестирования и отображения работы всех СБИС. Применяемое Tandem расширение к стандарту IEEE 1149.1, обеспечивает доступ к регистрам СБИС. Работа средств сканирования никак не затрагивает нормальную работу СБИС. Этот универсальный механизм обеспечивает средство для инициализации СБИС, определения топологии ServerNet и передачи сообщений об ошибках.
Системные и локальные шины
В вычислительной системе, состоящей из множества подсистем, необходим механизм для их взаимодействия. Эти подсистемы должны быстро и эффективно обмениваться данными. Например, процессор, с одной стороны, должен быть связан с памятью, с другой стороны, необходима связь процессора с устройствами ввода/вывода. Одним из простейших механизмов, позволяющих организовать взаимодействие различных подсистем, является единственная центральная шина, к которой подсоединяются все подсистемы. Доступ к такой шине разделяется между всеми подсистемами. Подобная организация имеет два основных преимущества: низкая стоимость и универсальность. Поскольку такая шина является единственным местом подсоединения для разных устройств, новые устройства могут быть легко добавлены, и одни и те же периферийные устройства можно даже применять в разных вычислительных системах, использующих однотипную шину. Стоимость такой организации получается достаточно низкой, поскольку для реализации множества путей передачи информации используется единственный набор линий шины, разделяемый множеством устройств.
Главным недостатком организации с единственной шиной является то, что шина создает узкое горло, ограничивая, возможно, максимальную пропускную способность ввода/вывода. Если весь поток ввода/вывода должен проходить через центральную шину, такое ограничение пропускной способности весьма реально. В коммерческих системах, где ввод/вывод осуществляется очень часто, а также в суперкомпьютерах, где необходимые скорости ввода/вывода очень высоки из-за высокой производительности процессора, одним из главных вопросов разработки является создание системы нескольких шин, способной удовлетворить все запросы.
Одна из причин больших трудностей, возникающих при разработке шин, заключается в том, что максимальная скорость шины главным образом лимитируется физическими факторами: длиной шины и количеством подсоединяемых устройств (и, следовательно, нагрузкой на шину). Эти физические ограничения не позволяют произвольно ускорять шины. Требования быстродействия (малой задержки) системы ввода/вывода и высокой пропускной способности являются противоречивыми. В современных крупных системах используется целый комплекс взаимосвязанных шин, каждая из которых обеспечивает упрощение взаимодействия различных подсистем, высокую пропускную способность, избыточность (для увеличения отказоустойчивости) и эффективность.
Традиционно шины делятся на шины, обеспечивающие организацию связи процессора с памятью, и шины ввода/вывода. Шины ввода/вывода могут иметь большую протяженность, поддерживать подсоединение многих типов устройств, и обычно следуют одному из шинных стандартов. Шины процессор-память, с другой стороны, сравнительно короткие, обычно высокоскоростные и соответствуют организации системы памяти для обеспечения максимальной пропускной способности канала память-процессор. На этапе разработки системы, для шины процессор-память заранее известны все типы и параметры устройств, которые должны соединяться между собой, в то время как разработчик шины ввода/вывода должен иметь дело с устройствами, различающимися по задержке и пропускной способности.
Как уже было отмечено, с целью снижения стоимости некоторые компьютеры имеют единственную шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Персональные компьютеры, как правило, строятся на основе одной системной шины в стандартах ISA, EISA или MCA. Необходимость сохранения баланса производительности по мере роста быстродействия микропроцессоров привела к двухуровневой организации шин в персональных компьютерах на основе локальной шины. Локальной шиной называется шина, электрически выходящая непосредственно на контакты микропроцессора. Она обычно объединяет процессор, память, схемы буферизации для системной шины и ее контроллер, а также некоторые вспомогательные схемы. Типичными примерами локальных шин являются VL-Bus и PCI.
Рассмотрим типичную транзакцию на шине. Шинная транзакция включает в себя две части: посылку адреса и прием (или посылку) данных. Шинные транзакции обычно определяются характером взаимодействия с памятью: транзакция типа "Чтение" передает данные из памяти (либо в ЦП, либо в устройство ввода/вывода), транзакция типа "Запись" записывает данные в память. В транзакции типа "Чтение" по шине сначала посылается в память адрес вместе с соответствующими сигналами управления, индицирующими чтение. Память отвечает, возвращая на шину данные с соответствующими сигналами управления. Транзакция типа "Запись" требует, чтобы ЦП или устройство в/в послало в память адрес и данные и не ожидает возврата данных. Обычно ЦП вынужден простаивать во время интервала между посылкой адреса и получением данных при выполнении чтения, но часто он не ожидает завершения операции при записи данных в память.
Разработка шины связана с реализацией ряда дополнительных возможностей (рисунок 3.25). Решение о выборе той или иной возможности зависит от целевых параметров стоимости и производительности. Первые три возможности являются очевидными: раздельные линии адреса и данных, более широкие (имеющие большую разрядность) шины данных и режим групповых пересылок (пересылки нескольких слов) дают увеличение производительности за счет увеличения стоимости.
Следующий термин, указанный в таблице, - количество главных устройств шины (bus master). Главное устройство шины - это устройство, которое может инициировать транзакции чтения или записи. ЦП, например, всегда является главным устройством шины. Шина имеет несколько главных устройств, если имеется несколько ЦП или когда устройства ввода/вывода могут инициировать транзакции на шине. Если имеется несколько таких устройств, то требуется схема арбитража, чтобы решить, кто следующий захватит шину. Арбитраж часто основан либо на схеме с фиксированным приоритетом, либо на более "справедливой" схеме, которая случайным образом выбирает, какое главное устройство захватит шину.
В настоящее время используются два типа шин, отличающиеся способом коммутации: шины с коммутацией цепей (circuit-switched bus) и шины с коммутацией пакетов (packet-switched bus), получившие свои названия по аналогии со способами коммутации в сетях передачи данных. Шина с коммутацией пакетов при наличии нескольких главных устройств шины обеспечивает значительно большую пропускную способность по сравнению с шиной с коммутацией цепей за счет разделения транзакции на две логические части: запроса шины и ответа. Такая методика получила название "расщепления" транзакций (split transaction). (В некоторых системах такая возможность называется шиной соединения/разъединения (connect/disconnect) или конвейерной шиной (pipelined bus). Транзакция чтения разбивается на транзакцию запроса чтения, которая содержит адрес, и транзакцию ответа памяти, которая содержит данные. Каждая транзакция теперь должна быть помечена (тегирована) соответствующим образом, чтобы ЦП и память могли сообщить что есть что.
Шина с коммутацией цепей не делает расщепления транзакций, любая транзакция на ней есть неделимая операция. Главное устройство запрашивает шину, после арбитража помещает на нее адрес и блокирует шину до окончания обслуживания запроса. Большая часть этого времени обслуживания при этом тратится не на выполнение операций на шине (например, на задержку выборки из памяти). Таким образом, в шинах с коммутацией цепей это время просто теряется. Расщепленные транзакции делают шину доступной для других главных устройств пока память читает слово по запрошенному адресу. Это, правда, также означает, что ЦП должен бороться за шину для посылки данных, а память должна бороться за шину, чтобы вернуть данные. Таким образом, шина с расщеплением транзакций имеет более высокую пропускную способность, но обычно она имеет и большую задержку, чем шина, которая захватывается на все время выполнения транзакции. Транзакция называется расщепленной, поскольку произвольное количество других пакетов или транзакций могут использовать шину между запросом и ответом.
Последний вопрос связан с выбором типа синхронизации и определяет является ли шина синхронной или асинхронной. Если шина синхронная, то она включает сигналы синхронизации, которые передаются по линиям управления шины, и фиксированный протокол, определяющий расположение сигналов адреса и данных относительно сигналов синхронизации. Поскольку практически никакой дополнительной логики не требуется для того, чтобы решить, что делать в следующий момент времени, эти шины могут быть и быстрыми, и дешевыми. Однако они имеют два главных недостатка. Все на шине должно происходить с одной и той же частотой синхронизации, поэтому из-за проблемы перекоса синхросигналов, синхронные шины не могут быть длинными. Обычно шины процессор-память синхронные.
| Возможность | Высокая производительность | Низкая стоимость |
| Общая разрядность шины | Отдельные линии адреса и данных |
Мультиплексирование линий адреса и данных |
| Ширина (рязрядность) данных |
Чем шире, тем быстрее (например, 32 бит) | Чем уже, тем дешевле (например, 8 бит) |
| Размер пересылки | Пересылка нескольких слов имеет меньшие накладные расходы | Пересылка одного слова дешевле |
| Главные устройства шины | Несколько (требуется арбитраж) | Одно (арбитраж не нужен) |
| Расщепленные транзакции? | Да - отдельные пакеты Запроса и Ответа дают большую полосу пропускания (нужно несколько главных устройств) | Нет - продолжающееся соединение дешевле и имеет меньшую задержку |
| Тип синхронизации | Синхронные | Асинхронные |
Системный интерфейс
Системный интерфейс процессора R10000 работает в качестве шлюза между самим процессором, связанным с ним кэшем второго уровня и остальной системой. Системный интерфейс работает с тактовой частотой внешней синхронизации (SysClk). Возможно программирование работы системного интерфейса на тактовой частоте 200, 133, 100, 80, 67, 57 и 50 МГц. Все выходы и входы системного интерфейса синхронизируются нарастающим фронтом сигнала SysClk, позволяя ему работать на максимально возможной тактовой частоте.
В большинстве микропроцессорных систем в каждый момент времени может происходить только одна системная транзакция.
Процессор R10000 поддерживает протокол расщепления транзакций, позволяющий осуществлять выдачу очередных запросов процессором или внешним абонентом шины, не дожидаясь ответа на предыдущий запрос. Максимально в любой момент времени поддерживается до четырех одновременных транзакций на шине.
Для технических приложений, предъявляющих очень
Для технических приложений, предъявляющих очень большие требования к производительности, IBM также разрабатывает ряд высокопроизводительных систем с параллельной архитектурой. Первая из них, SP1, разработана прежде всего для задач с большим объемом вычислений таких как сейсмические исследования, гидродинамика и вычислительная химия. Она может иметь от 8 до 64 процессорных узлов POWER, обеспечивая производительность от 1 до 8 Гфлопс. Система поддерживает новейшую многоступенчатую архитектуру с пакетным переключением и может выполнять задачи как на отдельных процессорах, так и распараллеливать выполнение одной задачи на нескольких процессорах. Одним из узких мест SP1 является ввод/вывод, осуществляющийся через сеть Ethеrnet, и относительно небольшой объем дисковой памяти. Именно это и ограничивает ее применение для решения задач коммерческого назначения. С целью устранения этого узкого места IBM разработала следующий вариант этой системы, получивший название SP2. Она включает уже 128 узлов с процессорами POWER2, соединенных между собой высокоскоростным коммутатором с пропускной способностью 2.56 Гбайт/с. Система может поддерживать в каждый момент времени до 64 соединений, так что скорость обмена данными между ее двумя узлами достигает 40 Мбайт/с. Кроме того, к ней может теперь подключаться большое число внешних дисковых накопителей. На весенней выставке CeBIT в Ганновере, Германия, работа SP2 демонстрировалась не только при решении научно-инженерных задач типа прогноза погоды и расчетов в области географии, но и при работе таких коммерческих приложений как АСУ R3 компании SAP, CICS/6000 и DB2/6000 компании IBM. С теоретической точки зрения все, что разрабатывается для кластерных систем, сможет работать на системе SP2.
Системы СУБД клиент/сервер сконфигурированные
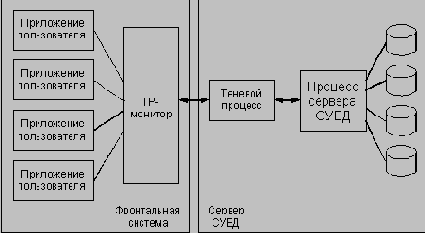
Рекомендации:
TP-мониторы могут рассматриваться как кандидаты для включения в состав системы, когда доступен исходный текст приложения. TP-мониторы следует использовать для интеграции в корне отличных источников информации базы данных. TP-мониторы особенно полезны для сокращения трафика клиент/сервер на сетях с низкой полосой пропускания или глобальных сетях. Применение системе TP-монитора следует рассматривать, когда должно обслуживаться большое количество пользователей и используемая СУБД предпочитает или требует реализации архитектуры "2N".Снижение потерь на выполнение команд условного перехода
Имеется несколько методов сокращения приостановок конвейера, возникающих из-за задержек выполнения условных переходов. В данном разделе обсуждаются четыре простые схемы, используемые во время компиляции. В этих схемах прогнозирование направления перехода выполняется статически, т.е. прогнозируемое направление перехода фиксируется для каждой команды условного перехода на все время выполнения программы. После обсуждения этих схем мы исследуем вопрос о правильности предсказания направления перехода компиляторами, поскольку все эти схемы основаны на такой технологии. В следующей главе мы рассмотрим более мощные схемы, используемые компиляторами (такие, например, как разворачивание циклов), которые уменьшают частоту команд условных переходов при реализации циклов, а также динамические, аппаратно реализованные схемы прогнозирования.
Метод выжидания
Простейшая схема обработки команд условного перехода заключается в замораживании или подавлении операций в конвейере, путем блокировки выполнения любой команды, следующей за командой условного перехода, до тех пор, пока не станет известным направление перехода. Рисунок 3.8 отражал именно такой подход. Привлекательность такого решения заключается в его простоте.
Метод возврата
Более хорошая и не на много более сложная схема состоит в том, чтобы прогнозировать условный переход как невыполняемый. При этом аппаратура должна просто продолжать выполнение программы, как если бы условный переход вовсе не выполнялся. В этом случае необходимо позаботиться о том, чтобы не изменить состояние машины до тех пор, пока направление перехода не станет окончательно известным. В некоторых машинах эта схема с невыполняемыми по прогнозу условными переходами реализована путем продолжения выборки команд, как если бы условный переход был обычной командой. Поведение конвейера выглядит так, как будто ничего необычного не происходит. Однако, если условный переход на самом деле выполняется, то необходимо просто очистить конвейер от команд, выбранных вслед за командой условного перехода и заново повторить выборку команд (рисунок 3.9).
| Невыполняемый условный переход | IF | ID | EX | MEM | WB | ||||
| Команда i+1 | IF | ID | EX | MEM | WB | ||||
| Команда i+2 | IF | ID | EX | MEM | WB | ||||
| Команда i+3 | IF | ID | EX | MEM | WB | ||||
| Команда i+4 | IF | ID | EX | MEM | WB | ||||
| Выполняемый условный переход |
IF | ID | EX | MEM | WB | ||||
| Команда i+1/целевая команда | IF | IF | ID | EX | MEM | WB | |||
| Целевая команда +1 | stall | IF | ID | EX | MEM | WB | |||
| Целевая команда +2 | stall | IF | ID | EX | MEM | WB | |||
| Целевая команда +3 | stall | IF | ID | EX | MEM |
Сокращение потерь на выполнение команд перехода и минимизация конфликтов по управлению
Конфликты по управлению могут вызывать даже большие потери производительности конвейера, чем конфликты по данным. Когда выполняется команда условного перехода, она может либо изменить, либо не изменить значение счетчика команд. Если команда условного перехода заменяет счетчик команд значением адреса, вычисленного в команде, то переход называется выполняемым; в противном случае, он называется невыполняемым.
Простейший метод работы с условными переходами заключается в приостановке конвейера как только обнаружена команда условного перехода до тех пор, пока она не достигнет ступени конвейера, которая вычисляет новое значение счетчика команд (рисунок 3.8). Такие приостановки конвейера из-за конфликтов по управлению должны реализовываться иначе, чем приостановки из-за конфликтов по данным, поскольку выборка команды, следующей за командой условного перехода, должна быть выполнена как можно быстрее, как только мы узнаем окончательное направление команды условного перехода.
| Команда перехода | IF | ID | EX | MEM | WB | |||||
| Следующая команда | IF | stall | stall | IF | ID | EX | MEM | WB | ||
| Следующая команда +1 | stall | stall | stall | IF | ID | EX | MEM | WB | ||
| Следующая команда +2 | stall | stall | stall | IF | ID | EX | MEM | |||
| Следующая команда +3 | stall | stall | stall | IF | ID | EX | ||||
| Следующая команда +4 | stall | stall | stall | IF | ID | |||||
| Следующая команда +5 | stall | stall | stall | IF |
Соображения по использованию режима клиент/сервер
Если СУБД работает в режиме клиент/сервер, то сеть или сети, соединяющие клиентов с сервером должны быть адекватно оборудованы. К счастью, большинство клиентов работают с вполне определенными фрагментами данных: индивидуальными счетами, единицами хранящихся на складе изделий, историей индивидуальных счетов и т.п. При этих обстоятельствах скорость сети, соединяющей клиентов и серверы редко оказывается проблемой. Отдельной сети Ethernet или Token Ring обычно достаточно для обслуживания 100-200 клиентов. На одном из тестов Sun конфигурация клиент/сервер, поддерживающая более 250 пользователей Oracle*Financial, генерировала трафик примерно 200 Кбайт/с между фронтальной системой и сервером базы данных. По очевидным причинам стоит более плотно наблюдать за загрузкой сети, особенно когда число клиентов превышает примерно 20 на один сегмент Ethernet. Сети Token Ring могут поддерживать несколько большую нагрузку, чем сети Ethernet, благодаря своим превосходным характеристикам по устойчивости к деградации под нагрузкой.
Даже если с пропускной способностью сети не возникает никаких вопросов, проблемы задержки часто приводят к тому, что более удобной и полезной оказывается установка отдельной, выделенной сети между фронтальной системой и сервером СУБД. В существующих в настоящее время конфигурациях серверов почти всегда используется большое количество главных адаптеров шины SCSI; поскольку как правило эти адаптеры спарены с портами Ethernet, обеспечение выделенного канала Ethernet между клиентом и сервером выполняется простым их подключением к дешевому хабу с помощью кабельных витых пар. Стоимость 4-портового хаба не превышает $250, поэтому причины, по которым не стоило бы обеспечить такое выделенное соединение, практически отсутствуют.
Соотношение запрос/индекс/диск
Без понимания приложения заказчика, стратегии индексации, принятой администратором базы данных, а также механизмов поиска и хранения СУБД сложно сделать точное утверждение о том, какого типа доступ к диску данная транзакция будет навязывать системе. Особенно трудно количественно определить сложные транзакции, которые имеют место в приложениях третьих фирм, например, в продукте R/3 SAP, который надстроен над Oracle. Однако в отсутствие фирменной информации стоит предположить, что любая транзакция, которая находит небольшое число специально поименованных записей из индексированной таблицы "по индексному ключу" будет представлять собой операцию произвольного доступа к диску. Например, транзакция
select name, salary from employee
were phone-number = "555-1212" or
ssn = "111-111-1111";
почти наверняка будет осуществлять произвольное обращение к диску, если таблица служащих индексируется с помощью phone-number и ssn. Однако, если таблица индексируется только именем и номером служащего, то такая транзакция будет выполняться путем последовательного сканирования таблицы, вполне возможно затрагивая каждую ее запись.
Запросы, которые содержат целый ряд значений ключей, могут генерировать комбинацию произвольного и последовательного доступа, в зависимости от имеющей место индексации.
Рассмотрим запрос
select part_no, description, num-on-hand from stock
where (part_no > 2000 and part_no < 24000);
Если складская таблица индексируется с помощью part_no (что очень вероятно), этот запрос будет вероятно генерировать последовательное сканирование индексов (а возможно только частичное сканирование, если индексы физически хранятся в некотором способом отсортированном порядке), за которым последует произвольная выборка подходящих строк из таблицы данных. Однако, если по каким-то причинам эта таблица не индексировалась бы с помощью part_no, то запрос почти наверняка приводил бы к полному сканированию таблицы.
Напомним, что любое обновление базы данных связано и с обновлением всех затронутых индексов, а также с выполнением записи в журнал. К сожалению, вся эта техника уходит далеко за рамки данной части курса, требуя основательного понимания работы конкретной используемой СУБД, сложной природы запросов и методов оптимизации запросов. Оценка требований к выполнению дисковых операций оказывается неточной без детальной информации о том, как СУБД хранит данные, даже для показанных здесь простых транзакций. Вычисление количества и типа дисковых обращений для операции соединения пяти таблиц, ограниченной коррелирующим подзапросом был бы сложен даже для авторов приложения!
Замечание. В случаях, когда ожидается, что такие запросы будут определять общую производительностью прикладной системы, следует настаивать на консультациях экспертов. Диапазон ошибок для такого рода запросов часто составляет 1000:1!
SPARCcenter 2000/2000E
Многопроцессорный сервер SPARCcenter 2000 на сегодняшний день является достаточно мощным сервером компании Sun Microsystems. Это изделие представляет собой дальнейшее развитие стратегической линии компании на замену старых больших ЭВМ (mainframe) в учреждениях и организациях. В SPARCcenter 2000 могут устанавливаться от двух до двадцати процессоров SuperSPARC, что обеспечивает пиковую производительность до 2.7 GIPS (миллиардов операций в секунду) и до 350 MFLOPS (миллионов команд с плавающей точкой в секунду). Каждый процессор в системе снабжается внешним кэшем емкостью 2 Мб, а объем оперативной памяти системы может достигать 5 Гб. Для обеспечения эффективной работы 20 процессоров используется внутренняя сдвоенная шина SDbus с пропускной способностью 500 Мб/сек. Симметричная многопроцессорная архитектура сервера обеспечивает поддержку до 40 S-bus слотов расширения, дисковое пространство объемом до 4.8 Тбайт и предоставляет широкие возможности расширения для реализации очень больших баз данных. Благодаря реализации модульного принципа на всех уровнях конструктивной иерархии наращивание объема оперативной памяти, числа процессоров и дисков происходит значительно дешевле по сравнению с наращиванием аналогичных частей систем на базе миникомпьютеров и больших ЭВМ.
SPARCcluster PDB server
SPARCcluster PDB server - это название продукта, обеспечивающего объединение SPARCserver 1000 и SPARCcenter 2000 в системы высокой готовности, обеспечивающие поддержку Oracle Parallel Server.
наиболее доступный по стоимостным характеристикам
SPARCserver 4 - наиболее доступный по стоимостным характеристикам сервер, обладает прекрасным соотношением производительность/стоимость и может служить в качестве файл-сервера рабочей группы, принт-сервера или сервера приложений, а также в качестве сетевого сервера. Максимальный объем дисковой памяти, поддерживаемый сервером составляет 28 Гбайт.
один из наиболее популярных настольных
SPARCserver 5 - один из наиболее популярных настольных серверов рабочих групп компании Sun. Его конструкция сбалансирована по производительности, использует S-bus - высокоскоростную шину ввода/вывода, являющуюся промышленным стандартом. Максимальный объем внешней дисковой памяти равен 100 Гбайт. В конфигурациях с названием Netra поставляется с программным обеспечением для объединения с сетями персональных компьютеров и сетью Internet.
SPARCserver 20 предоставляет возможность создания
SPARCserver 20 предоставляет возможность создания многопроцессорных конфигураций. Компактная конструкция, высокая производительность при работе с базами данных и хорошие возможности интеграции в существующие локальные вычислительные сети позволяют создавать на базе SPARCserver 20 высокопроизводительные серверы рабочих групп, заменяющие существующие миникомпьютеры. Емкость массовой памяти, поддерживаемой на системах SPARCserver 20 может достигать 338 Гб.
SPARCserver 1000/1000E
Высокопроизводительный сервер SPARCserver 1000/1000E, который пришел на смену серверам серии 600MP, обеспечивает производительность на уровне больших вычислительных систем (mainframe) и может использоваться в качестве многоцелевого сервера NFS или сервера небольшого предприятия, поддерживающего работу до 1500 пользователей.
SPARCserver 1000/1000E имеет модульную конструкцию, в которую могут устанавливаться до 8 процессоров 50, 60 или 75 МГц SuperSPARC с кэшем второго уровня емкостью 1 Мб на каждый процессор. Для обеспечения эффективной работы в многопроцессорном режиме в SPARCserver 1000/1000E используется внутренняя шина XDbus c пропускной способностью 250 Мб/сек. Шина XDbus, работающая в режиме пакетного переключения, обеспечивает модульное расширение количества процессоров, карт ввода/вывода, оперативной памяти и S-bus слотов. В системном блоке могут устанавливаться до четырех плат (системных или дисковых). На каждой системной плате могут размещаться один или два процессорных модуля, работающих на частоте 50, 60 или 85 МГц и до 512 Мб оперативной памяти. Каждая системная плата содержит 3 слота расширения S-bus, два последовательных порта, контроллер SCSI-2 и контроллер сети Ethernet. Таким образом максимальный объем оперативной памяти системы может достигать 2 Гб, а количество S-bus слотов - 12. Свободные слоты S-bus могут использоваться для установки карт видеоадаптеров, сетевых контроллеров и дополнительных контроллеров SCSI-2. Максимальный объем дискового пространства может достигать 760 Гб.
Работая под управлением операционной системы Solaris 2.5 (обеспечивает симметричную многопроцессорную обработку), SPARCserver 1000 в восьмипроцессорной конфигурации имеет отличную производительность при работе с базами данных - 400 TPC-A (транзакций в минуту) и соотношение стоимость/производительность - $5987/TPC-A.